90-Day Data Science with GenAI Roadmap: Your Complete Guide to Getting Hired
Table of Contents
This is a structured, day-by-day 90-day roadmap to go from zero to job-ready data scientist — covering Python, Machine Learning, Deep Learning, and Generative AI. Built on Frontlines Edutech’s proven Data Science with GenAI course curriculum, this plan is designed specifically for students in India who want practical skills, not just certificates. By Day 90, you’ll have a project portfolio, an optimised LinkedIn profile, and the technical confidence to crack interviews at companies like TCS, Infosys, Wipro, and top Hyderabad/Bangalore startups. No prior coding experience needed. Just 90 days of focused effort.
Explore Future-Ready Data Science with GenAI Courses →
Why This Roadmap Works (When Others Don't)
Most YouTube tutorials and free courses teach concepts in isolation. They leave you knowing what Python is — but not knowing what to build next. That’s the gap this roadmap closes.
Here’s what makes this plan different:
- Day-by-day structure — no guesswork about what to learn or when
- Employability from Day 1 — LinkedIn, GitHub, and portfolio-building are baked in throughout
- GenAI-first — you’re not just learning ML from 2018; you’re learning LLMs, RAG, and Agentic AI that employers want right now
- India-market focus — job platforms, company names, and salary benchmarks are tailored for Hyderabad, Bangalore, Pune, and other Indian tech hubs
The Indian job market for data scientists is booming. Companies including Infosys, TCS, Accenture, Capgemini, Wipro, Cognizant, IBM, and KPMG are actively hiring professionals who can work with both traditional ML and GenAI. This roadmap prepares you for exactly that.
The 3-Month Learning Structure at a Glance
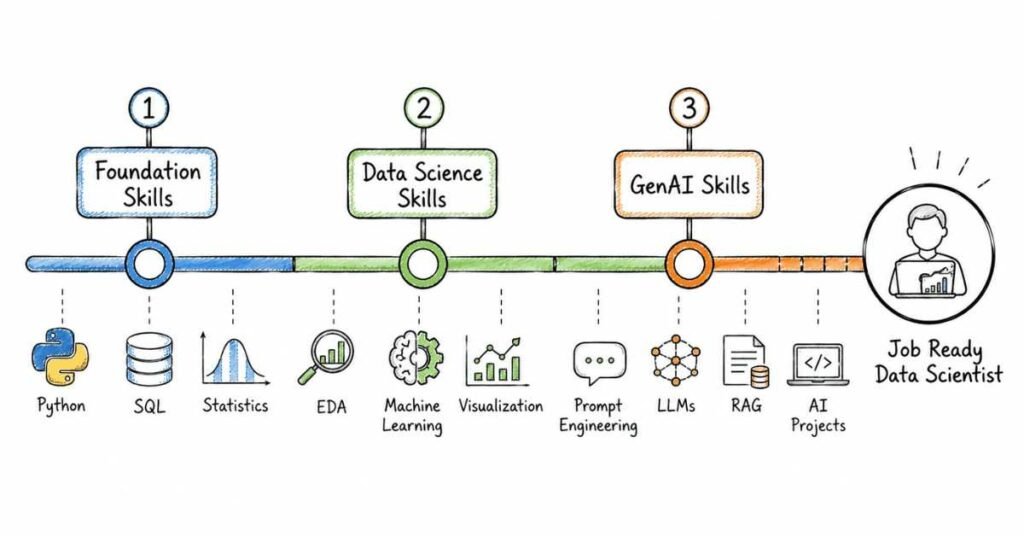
Month 1: Build Your Foundation (Days 1–30)
The first 30 days are non-negotiable. Students who skip the foundation always hit a wall in Month 2. Give these weeks your full focus.
Week 1: Python Programming Fundamentals (Days 1–7)
You don’t need to be a computer science graduate. You just need to be consistent. Here’s what Week 1 covers:
- Day 1 — Set up Python, Anaconda, PyCharm. Write your first program.
- Day 2 — Numeric data types, variables, memory management
- Day 3 — Strings, Lists, Dictionaries, Tuples, Sets — the backbone of all data work
- Day 4 — Control flow: if-else, if-elif-else, ternary expressions
- Day 5 — Loops: while, for, map, zip, range, enumerate
- Day 6 — Functions: def, LEGB scoping rules, multiple return values
- Day 7 — Lambda, generators, recursion + Week 1 mini-project
💡 Career Tip: This week itself, set up your LinkedIn profile with the headline: “Aspiring Data Scientist | Python Programmer | Machine Learning Enthusiast” — recruiters search these keywords daily.
Explore the Complete Data Science with GenAI Career Guide →
Week 2: Modules, Packages & OOP (Days 8–14)
Object-Oriented Programming (OOP) is where many students get stuck. Take it slow here — it pays off in every ML framework you’ll ever use.
- Python module system, import statements, pycache
- Package structures and relative imports
- Classes, constructors (__init__), inheritance, polymorphism
- Object persistence with Pickle and Shelves
- Week 2 Project: Build a complete class hierarchy from scratch
Week 3: Operator Overloading & Exception Handling (Days 15–21)
- Custom operators (__getitem__, __repr__, __add__)
- Inheritance vs. Composition (“IS-A” vs. “HAS-A” relationships)
- Method Resolution Order (MRO), @staticmethod, @classmethod
- Try/except/finally, custom exceptions, context managers (with/as)
- Week 3 Project: Build a program with robust, production-style error handling
💡 Career Tip: Start posting your learning journey on LinkedIn using #DataScience #PythonProgramming #100DaysOfCode — consistency here builds your professional brand before you’ve even applied anywhere.
Week 4: NumPy, Pandas & Data Wrangling (Days 22–30)
This is where Python becomes data science. These libraries are used in every single job you’ll interview for.
- NumPy — arrays, indexing, universal functions, broadcasting
- Pandas — Series, DataFrames, reading CSV/Excel/SQL, data cleaning
- Data Wrangling — merge, join, groupby, pivot, apply, loc, iloc
- Regex — pattern matching, text cleaning, email/phone extraction
- Day 29 — Month 1 Capstone: Full data analysis pipeline in Jupyter
- Day 30 — LinkedIn profile complete: photo, banner, skills, featured section, 50+ connections
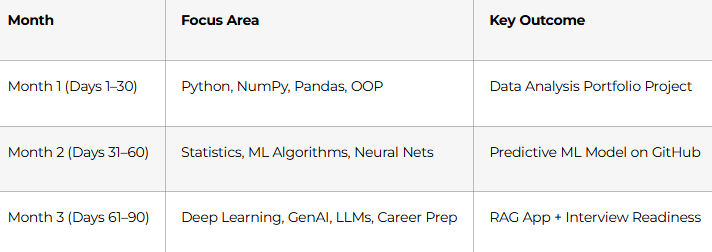
Month 2: Mathematics, Statistics & Machine Learning (Days 31–60)
Month 2 is where you stop being a Python programmer and start becoming a data scientist. This is where the real fun begins.
Week 5: Math & Statistics for Data Science (Days 31–37)
Don’t panic — you don’t need a maths degree. You need applied understanding:

Week 6: Machine Learning Foundations (Days 38–44)
- Supervised vs. unsupervised learning
- Train/validation/test splits and preventing overfitting
- Binary classification — your first real ML model
- Confusion matrix, precision, recall, F1-score
- Linear regression from scratch — understand gradient descent deeply
- Ridge, Lasso, Polynomial Regression
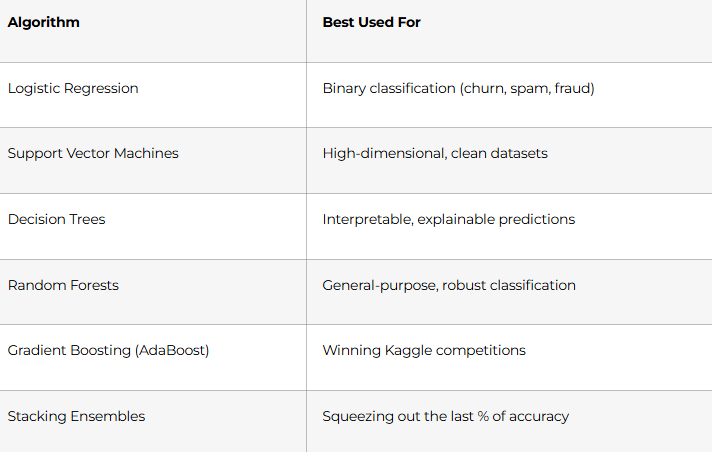
Week 7: Advanced ML Algorithms (Days 45–51)
💡 Career Tip: By Day 45, your GitHub should have at least 2 repositories with proper README files, documented notebooks, and result visualisations. Employers will check your GitHub before interviews.
Week 8: Unsupervised Learning, Neural Networks & Month Review (Days 52–60)
- K-Means clustering, DBSCAN, silhouette scores
- Introduction to neural networks and backpropagation
- Building MLPs with Keras — Sequential and Functional API
- Hyperparameter tuning — layers, neurons, learning rate, batch size
- Day 58 — Month 2 Capstone: End-to-end ML project solving a real business problem
- Day 59 — Resume workshop: quantify your projects, ATS keyword optimisation
- Day 60 — Portfolio website or GitHub Pages live + LinkedIn updated
Month 3: Deep Learning, GenAI & Career Launch (Days 61–90)
This is the section that separates Frontlines Edutech graduates from every other data science learner. You’re not just learning ML — you’re learning the technology that’s reshaping every industry.
Week 9: Deep Learning Mastery (Days 61–67)
- Vanishing/exploding gradients — Glorot, He, LeCun initialisation
- Batch normalisation, dropout, L1/L2 regularisation
- TensorFlow Data Pipeline — prefetching, shuffling, feature engineering
- Keras preprocessing layers — embeddings, one-hot encoding
- Computer Vision — CNNs, VGG, ResNet, EfficientNet, transfer learning
- NLP Basics — RNNs, LSTMs, sequence modelling
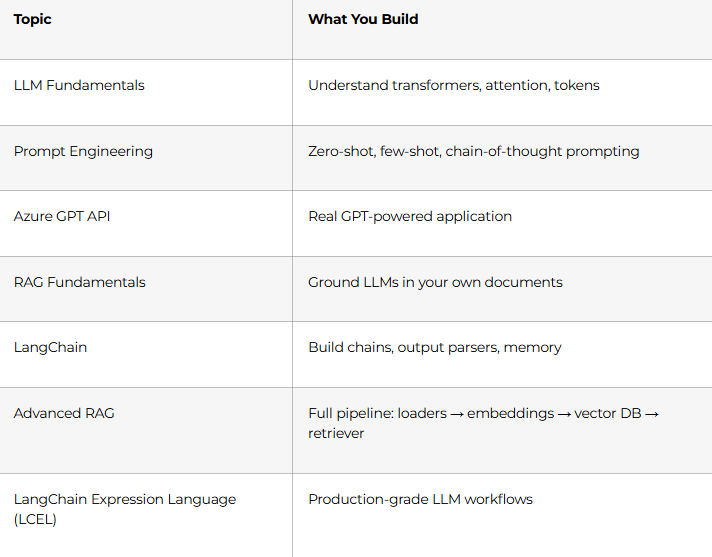
Week 10: Generative AI & LLMs (Days 68–74)
This is where every recruiter’s eyes light up on your resume.
Week 11: Advanced GenAI & Multimodal Models (Days 75–81)
- BERT, RoBERTa, T5 — fine-tune on custom data
- GANs (Generative Adversarial Networks) — StyleGAN, CycleGAN, DCGAN
- Diffusion Models — Stable Diffusion, DDPM, text-to-image
- Multimodal LLMs — text + image + audio integration
- Agentic AI — autonomous agents, multi-agent systems, tool-calling
- Day 81 Capstone — Build a customer support AI agent with tool-calling
💡 Career Tip: Record a 2-minute demo video of your GenAI project and post it on LinkedIn. A working app demo gets 10x more engagement than a static code screenshot — and it gets recruiters sliding into your DMs.
Week 12: Career Launch (Days 82–90)
This week is purely about getting hired. Here’s the action plan:
- Day 82 — Select top 5 portfolio projects; write business-impact descriptions
- Day 83 — ATS-optimised resume with keywords: Python, TensorFlow, LangChain, GenAI, RAG
- Day 84 — LinkedIn deep optimisation: headline, summary, featured projects
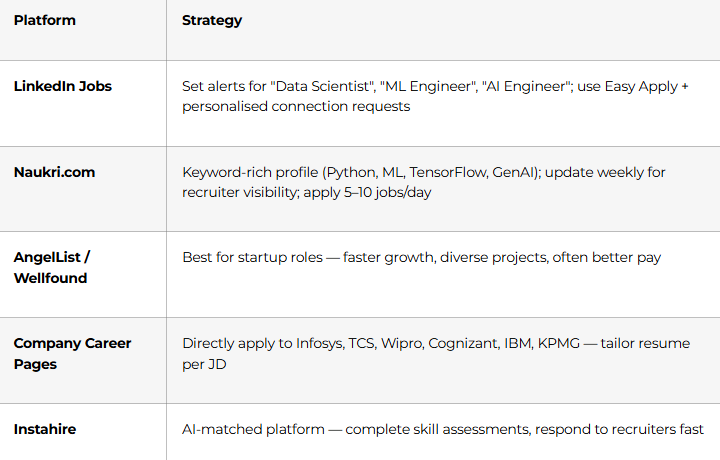
- Day 85 — Set up profiles on LinkedIn Jobs, Naukri, AngelList (Wellfound), Instahire
- Day 86 — Python + Statistics interview prep (50+ questions)
- Day 87 — Machine Learning interview prep (bias-variance, regularisation, algorithm trade-offs)
- Day 88 — Deep Learning + GenAI interview prep (transformers, RAG, prompt engineering)
- Day 89 — STAR method for behavioural rounds; practice explaining tech to non-tech people
- Day 90 — Full mock interview + finalise job search action plan (10+ applications/week)
Top Job Platforms for Data Science Roles in India
Crack Your Data Science GenAi Interview →
Why Choose Frontlines Edutech?
Frontlines Edutech, based in Hyderabad, bridges the gap between theory and industry — and does it in your language, your context, and at a price that makes sense for Indian students.
- Real mentors from top companies — not just recorded lectures
- Hands-on projects from Day 1 — not theory-heavy modules
- Career support — resume reviews, LinkedIn optimisation, mock interviews, placement updates
- Telugu-first teaching approach — complex topics explained in a way that actually clicks
- Affordable and transparent — no hidden fees, no surprises
Frequently Asked Questions (FAQs)
Q1.Can a complete beginner follow this 90-day data science roadmap?
A.Yes. This roadmap starts from Python basics on Day 1 — no prior coding or maths degree required. It’s designed specifically for beginners who want a structured, step-by-step path to their first data science job.
Q2.How many hours per day do I need to study to complete this roadmap?
A.Plan for 3–4 hours of focused study daily. Students balancing jobs or college can stretch it slightly but should not skip days, as each week builds directly on the previous one.
Q3..What tools and software will I need for this data science course?
A.You’ll need Python, Anaconda, PyCharm, Jupyter Notebook, TensorFlow, Keras, scikit-learn, LangChain, and Azure GPT API access. All are free to install or offer free tiers for students.
Q4.Will I get a job after completing the 90-day Data Science with GenAI program?
A.Completing this roadmap with Frontlines Edutech gives you a job-ready portfolio, ATS-optimised resume, and interview preparation. Placement support is part of the program, and alumni have been hired by Infosys, TCS, Wipro, Cognizant, and funded startups.
Q5.What is the difference between Data Science and GenAI, and why learn both?
A. Data Science focuses on analysing data and building predictive models using ML. GenAI involves building applications with Large Language Models (LLMs) like GPT and Gemini. In 2025, employers want professionals who can do both — that’s exactly what this course delivers.
Q6.Is this roadmap suitable for non-IT background students?
A.Absolutely. The curriculum is designed beginner-friendly, and Frontlines Edutech teaches in Telugu and English making it easier for students from engineering, commerce, and science backgrounds to follow along without getting lost.
Published by Frontlines Edutech | blog.frontlinesedutech.com
support@frontlinesedutech.com