Python Full Stack Developer Interview Preparation Guide
Table of Contents
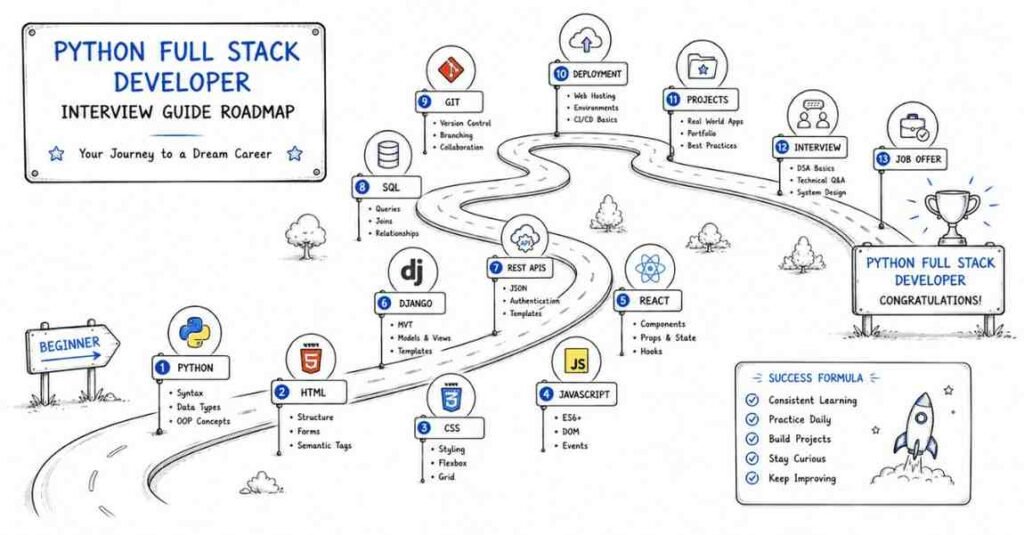
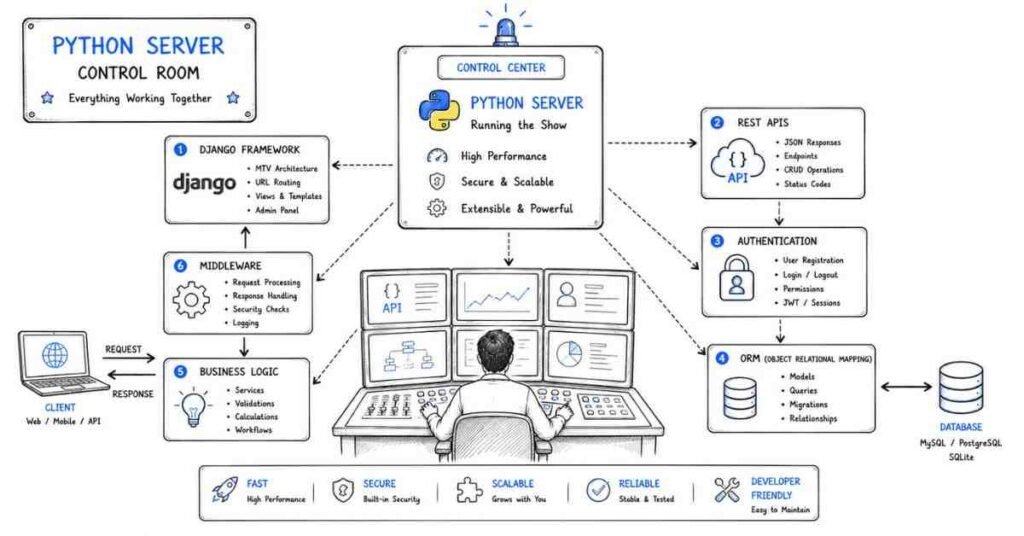
What Does a Python Full Stack Developer Do in 2026?
A Python Full Stack Developer builds complete web applications — both what users see (frontend) and everything that powers it behind the scenes (backend). In 2026, companies expect full stack developers to own the entire product lifecycle: from writing Python-powered APIs to deploying containerized applications on the cloud.
The modern Python full stack role covers:
- Backend: Python, Django, Flask, or FastAPI — building APIs, business logic, and database interactions
- Frontend: HTML, CSS, JavaScript, and React — building responsive, interactive user interfaces
- Database: PostgreSQL, MySQL, MongoDB, Redis — designing schemas and writing efficient queries
- DevOps basics: Git, Docker, NGINX, CI/CD, and cloud deployment (AWS / GCP / Azure)
- Security: Authentication, authorization, CORS, CSRF, SQL injection prevention
This guide was built from the ground up in June 2026 to cover exactly what interviewers at startups, product companies, and MNCs are testing today.
Who Is This Guide For?

Part 1: Introduction, Role Overview & 30-Day Study Plan
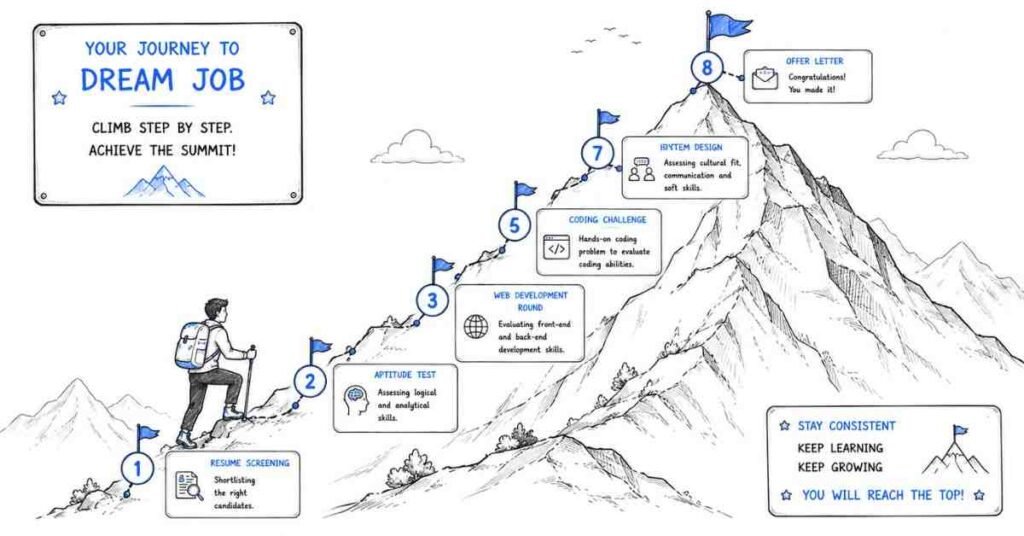
The 4 Interview Rounds You Will Face
Understanding the structure of a Python Full Stack interview removes half the anxiety. Most companies follow this flow:
Round 1 — Screening Call (HR / Recruiter)
Duration: 20–30 minutes
What they check: Communication, enthusiasm, basic background, tech stack familiarity, salary expectations, notice period
How to prepare: Have your 90-second “Tell me about yourself” ready. Know your resume and every project on it. Research the company’s product.
Round 2 — Technical Round 1: Core Fundamentals
Duration: 45–60 minutes
What they check: Python fundamentals, OOP concepts, basic Django/Flask questions, SQL queries, HTML/CSS/JS basics
Format: Live coding on CoderPad / screen share, or written code on whiteboard
How to prepare: Parts 2, 3, 5, and 7 of this guide
Round 3 — Technical Round 2: Full Stack & System Design
Duration: 60–90 minutes
What they check: REST API design, React components and state management, database design, DevOps awareness, and increasingly — system design for senior roles
Format: Build a mini feature, design an API, or whiteboard a system architecture
How to prepare: Parts 4, 6, 7, and 8 of this guide
Round 4 — HR / Managerial Round
Duration: 30–45 minutes
What they check: Behavioural responses, team fit, conflict resolution, career goals, problem-solving mindset
Format: Open-ended conversation guided by situational questions
How to prepare: Part 9 of this guide — STAR method + worked story templates
💡 Pro Tip (2026): Many product companies now add a take-home assignment — typically “build a small REST API with authentication and one React frontend page.” This is often weighted more than the live technical rounds. Always write clean, well-commented, documented code with a proper README.
Join the Python Full Stack Course →
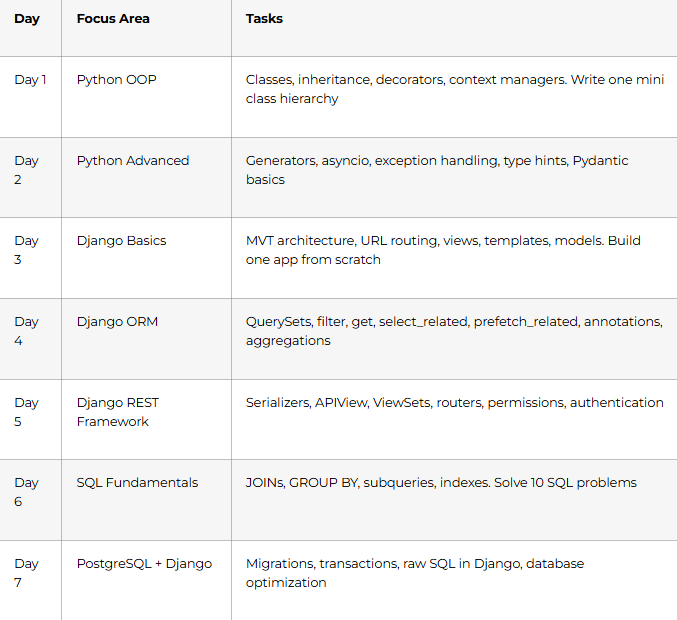
The 30-Day Python Full Stack Interview Prep Roadmap
This plan assumes 2–3 hours per day. Adjust the pace if you have more time available.
Week 1 (Days 1–7): Python, Django & Database Fundamentals
Goal: Be confident with Python OOP, Django ORM, and core SQL from memory.
Week 2 (Days 8–14): Frontend — HTML, CSS, JavaScript & React
Goal: Build a simple responsive page and a React component from memory.
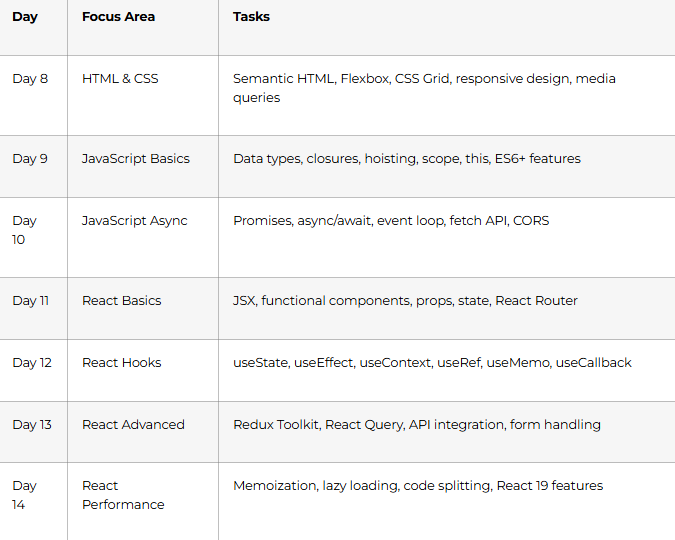
Week 3 (Days 15–21): APIs, DevOps & System Design
Goal: Design and deploy a full stack application end-to-end.
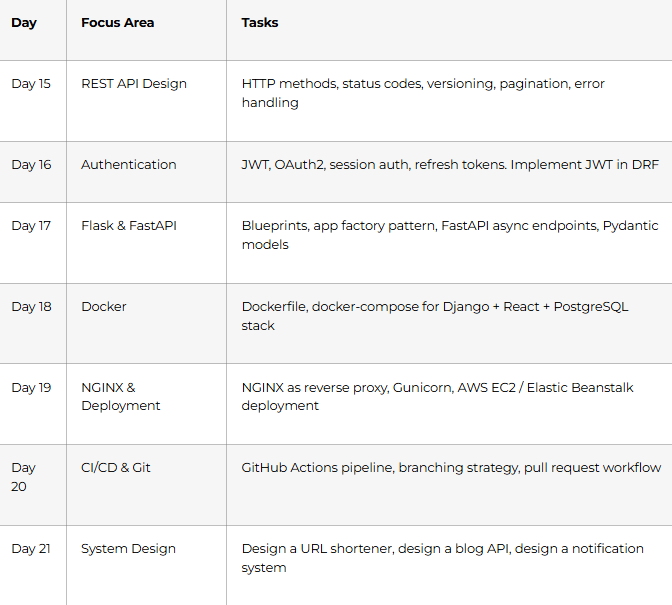
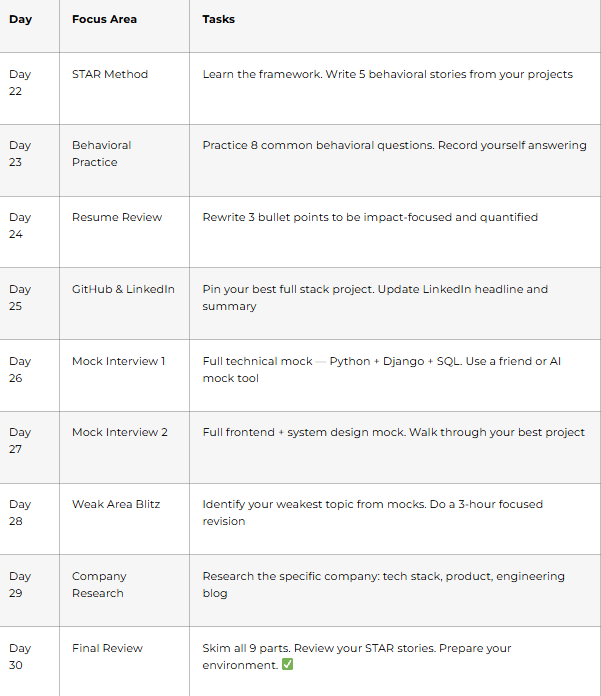
Week 4 (Days 22–30): Mock Interviews, Behavioral Prep & Career Strategy
Goal: Practice out loud. Polish your story. Be interview-ready — not just book-ready.
Python Full Stack Tech Stack Map (2026)
Understanding the full stack means knowing where each technology fits:
text
User’s Browser
│
▼
┌─────────────────────────────────┐
│ FRONTEND │
│ HTML + CSS + JavaScript │
│ React.js (with Redux / TanStack│
│ Query / React Router) │
└─────────────────────────────────┘
│ HTTP Requests (REST API)
▼
┌─────────────────────────────────┐
│ WEB SERVER / REVERSE PROXY │
│ NGINX │
└─────────────────────────────────┘
│
▼
┌─────────────────────────────────┐
│ BACKEND (WSGI/ASGI Server) │
│ Gunicorn / Uvicorn │
│ Django / Flask / FastAPI │
│ Django REST Framework │
└─────────────────────────────────┘
│
▼
┌─────────────────────────────────┐
│ DATABASE LAYER │
│ PostgreSQL (primary DB) │
│ Redis (caching + queues) │
│ MongoDB (if NoSQL needed) │
└─────────────────────────────────┘
│
▼
┌─────────────────────────────────┐
│ INFRASTRUCTURE │
│ Docker + Docker Compose │
│ AWS / GCP / Azure │
│ GitHub Actions (CI/CD) │
└─────────────────────────────────┘
Explore the Python Full Stack Roadmap →
Part 2: Core Python for Full Stack — 40 Interview Questions & Answers
Python Basics
Q1. What are Python’s key features that make it ideal for full stack development?
Python is beginner-friendly, has a clean and readable syntax, and supports multiple programming paradigms — procedural, object-oriented, and functional. Its massive ecosystem of frameworks like Django, Flask, and FastAPI makes it ideal for backend development, while its versatility with tools like Celery, Redis, and Docker integrations makes it production-ready. Python’s “batteries included” philosophy means most things you need are either built-in or one pip install away.
Q2. What is the difference between a list, tuple, set, and dictionary?
A list is an ordered, mutable collection that allows duplicate values. A tuple is ordered and immutable — once created, it cannot be changed, making it useful for fixed data like coordinates or configuration values. A set is an unordered collection of unique elements — ideal for deduplication and membership checks. A dictionary stores data as key-value pairs, is ordered (from Python 3.7+), and is mutable. Each serves a distinct purpose and choosing the right one affects both performance and code clarity.
Q3. What are Python’s mutable and immutable data types?
Immutable types cannot be changed after creation — they include integers, floats, strings, tuples, and frozensets. Mutable types can be modified in place — they include lists, dictionaries, and sets. This distinction matters in full stack development because passing mutable objects as default function arguments can cause unexpected bugs, and immutable objects are safe to use as dictionary keys or set elements.
Q4. What is the difference between is and == in Python?
== checks value equality — whether two objects have the same value. is checks identity equality — whether two variables point to the exact same object in memory. For example, two separate lists with identical elements will pass == but fail is. In web development, this matters when comparing against None — always use is None and never == None, which is the Python convention.
Q5. What are *args and **kwargs?
*args allows a function to accept any number of positional arguments, which are received as a tuple inside the function. **kwargs allows a function to accept any number of keyword arguments, which are received as a dictionary. They are widely used in Django’s class-based views, DRF serializers, and decorator utilities where flexibility in argument passing is needed.
Q6. What is the difference between deepcopy and shallowcopy?
A shallow copy creates a new object but populates it with references to the original object’s elements — changes to nested objects inside the copy will affect the original. A deep copy creates a completely independent copy — including all nested objects — so changes in the copy never affect the original. In web applications, this matters when duplicating configuration dictionaries or request data before modifying them.
Q7. What are Python’s built-in data structures and their time complexities?
Lists support O(1) append and O(n) search. Dictionaries and sets offer O(1) average time for insert, delete, and lookup thanks to hash tables. Tuples are slightly faster than lists for iteration because they are immutable and stored more compactly. Choosing the right structure — especially in Django views that process large datasets — directly impacts API response times.
Q8. What is the difference between range() and xrange()?
In Python 3, xrange() no longer exists — range() itself returns a lazy iterator, meaning it generates numbers on demand without storing the entire sequence in memory. This makes it memory-efficient for large loops. In Python 2, range() returned a list and xrange() was the lazy version. Since all modern web development uses Python 3, this distinction is historical but still comes up in interviews.
Object-Oriented Programming
Q9. What are the four pillars of OOP and how do they apply in Django?
The four pillars are Encapsulation (bundling data and methods — Django models encapsulate database fields and methods), Inheritance (Django class-based views use inheritance extensively — ListView, CreateView), Polymorphism (overriding methods in subclasses — customizing get_queryset() in different views), and Abstraction (hiding complexity — Django’s ORM abstracts raw SQL). Understanding OOP is not just theoretical in Django — the entire framework is built around it.
Q10. What is the difference between @staticmethod and @classmethod?
A @staticmethod does not receive any implicit first argument — it is a regular function that lives in a class’s namespace for organizational purposes. A @classmethod receives the class itself as the first argument (cls) and can access or modify class-level state. In Django, @classmethod is used in model methods like from_db() or custom manager methods, while @staticmethod is used for utility functions that belong logically to a class but do not need access to it.
Q11. What is method resolution order (MRO) in Python?
MRO defines the order in which Python searches for methods and attributes in a class hierarchy, particularly when multiple inheritance is involved. Python uses the C3 linearization algorithm to determine this order. You can inspect it using ClassName.__mro__. In Django, where class-based views use multiple mixins (like LoginRequiredMixin, PermissionRequiredMixin), understanding MRO helps you predict which method will be called and how to properly chain super() calls.
Q12. What are dunder (magic) methods in Python?
Dunder methods (double underscore methods) are special methods that Python calls implicitly in response to specific operations. __init__ initializes objects, __str__ defines the string representation, __repr__ defines the developer-facing representation, __len__ is called by len(), and __eq__ defines equality behavior. In Django, __str__ is defined on every model to control how objects appear in the admin panel and shell.
Q13. What is the difference between composition and inheritance?
Inheritance models an “is-a” relationship — a Dog is an Animal. Composition models a “has-a” relationship — a Car has an Engine. In modern Python web development, composition is often preferred because it avoids deep inheritance chains that become hard to maintain. Django REST Framework’s serializers use composition heavily — a serializer can contain other serializers as fields rather than inheriting from them.
Q14. What are abstract classes in Python and when do you use them?
Abstract classes are classes that cannot be instantiated directly — they define a common interface that all subclasses must implement. You create them using the ABC class and @abstractmethod decorator from the abc module. They are used when you want to enforce a contract across multiple implementations — for example, defining a base PaymentProcessor class that all payment gateway implementations (Stripe, Razorpay) must follow, ensuring all of them implement charge() and refund().
Decorators, Generators & Context Managers
Q15. What is a decorator in Python and how does it work?
A decorator is a function that takes another function as input, wraps it with additional behavior, and returns a new function. It uses the @ syntax as syntactic sugar. Decorators are used everywhere in web development — Django’s @login_required, @permission_required, DRF’s @api_view, and custom rate-limiting decorators all work on this principle. The key concept is that decorators run at import time, not call time, which makes them ideal for cross-cutting concerns like authentication and logging.
Q16. What is a generator in Python and why is it memory efficient?
A generator is a function that uses the yield keyword to return values one at a time, pausing execution between each yield. Unlike a list that stores all values in memory at once, a generator produces values lazily on demand. This is critical in web applications that process large datasets — for example, streaming through 500,000 database records for a CSV export without loading all of them into memory simultaneously would use a generator to avoid crashing the server.
Q17. What is a context manager and what problem does it solve?
A context manager manages resource allocation and cleanup using the with statement. It guarantees that the cleanup code runs even if an exception occurs. The classic examples are file handling and database connections — the with block ensures files are closed and transactions are committed or rolled back properly. In Django, database transactions are often managed using transaction.atomic() as a context manager, ensuring the entire operation succeeds or fails as a unit.
Q18. What is the difference between @property and a regular method?
A @property decorator allows a method to be accessed like an attribute — without calling it with parentheses. It is used to add computed attributes to a class without exposing internal logic. In Django models, @property is used for derived fields — for example, a full_name property that combines first_name and last_name. Unlike database fields, properties are computed in Python and are not stored in the database or available for ORM filtering.
Type Hints, Pydantic & Modern Python
Q19. What are type hints in Python and why do they matter for web development?
Type hints allow you to annotate variables and function signatures with their expected types using syntax like name: str or def get_user(id: int) -> User. They do not enforce types at runtime by default — but they enable IDEs to catch bugs early, make code self-documenting, and are used by tools like mypy for static analysis. In FastAPI, type hints are not optional — FastAPI uses them at runtime to automatically validate request data, serialize responses, and generate OpenAPI documentation.
Q20. What is Pydantic and how is it used in FastAPI?
Pydantic is a Python library for data validation using type annotations. You define a model as a class inheriting from BaseModel, and Pydantic automatically validates incoming data, converts types, and raises detailed errors when validation fails. FastAPI uses Pydantic models as request bodies — when a client sends a JSON payload, FastAPI automatically validates it against the Pydantic model, returning a 422 Unprocessable Entity error with detailed field-level messages if anything is wrong.
Q21. What is the difference between Python 3.10, 3.11, 3.12, and 3.13 features?
Python 3.10 introduced structural pattern matching (match/case statements). Python 3.11 brought significant performance improvements — up to 60% faster than 3.10 — along with more precise error messages that point exactly to the problem in a line. Python 3.12 added improved f-string syntax and better typing support. Python 3.13 (2024) brought a free-threaded mode (experimental) and continued performance improvements. For interviews in 2026, knowing that 3.11+ offers major speed gains is relevant for backend API performance discussions.
Exception Handling & File I/O
Q22. What is the difference between Exception and BaseException?
BaseException is the root of Python’s exception hierarchy — it includes system-exiting exceptions like SystemExit, KeyboardInterrupt, and GeneratorExit. Exception is a subclass of BaseException and is the base for all regular, recoverable exceptions that you should actually catch in your code. In web development, you should always catch specific exceptions (like ValueError, IntegrityError, DoesNotExist) rather than bare except: or even except Exception: in production code, as catching too broadly can swallow critical errors.
Q23. How do you handle exceptions in a Django REST API?
DRF has a built-in exception handler that catches APIException subclasses and returns appropriate HTTP responses automatically. You can customize this with a custom exception handler function that maps Python exceptions to HTTP status codes — for example, mapping a Django ObjectDoesNotExist to a 404 Not Found response. For global error handling in production, tools like Sentry are integrated to capture, log, and alert on unhandled exceptions in real time.
Q24. What is the finally block used for?
The finally block executes regardless of whether an exception was raised or not — even if the try block has a return statement. It is used for guaranteed cleanup — closing database connections, releasing locks, closing file handles. In the context of web development, this pattern is the foundation of context managers (with statements), which Django and DRF use internally for transactions, file handling, and test setup/teardown.
Concurrency & Performance
Q25. What is the GIL (Global Interpreter Lock) in Python?
The GIL is a mutex that allows only one Python thread to execute at a time, even on multi-core processors. This means Python threads do not achieve true parallelism for CPU-bound tasks. However, the GIL is released during I/O operations, so threads are still effective for I/O-bound tasks — like handling multiple simultaneous HTTP requests that are waiting on database queries. For CPU-bound parallelism, Python developers use multiprocessing, which spawns separate processes with their own GIL.
Q26. What is the difference between multithreading and multiprocessing in Python?
Multithreading runs multiple threads in the same process and is effective for I/O-bound tasks — like making multiple API calls simultaneously or handling concurrent database queries. However, the GIL prevents true CPU-level parallelism. Multiprocessing spawns separate processes, each with its own Python interpreter and GIL, enabling true CPU-level parallelism for compute-heavy tasks. In web development, Django and Gunicorn use multiple worker processes (not threads) to handle concurrent HTTP requests at scale.
Q27. What is asyncio and when would you use it in a web application?
asyncio is Python’s built-in library for writing asynchronous, non-blocking code using async/await syntax. It is ideal for I/O-bound tasks where you spend time waiting — making multiple external API calls, handling WebSockets, or reading from slow databases — and want to continue processing other tasks during the wait rather than blocking. FastAPI is built on asyncio, and Django supports async views since version 3.1. In 2026, async support is a must-know for any Python web developer.
Q28. What is the difference between async def and def in Django views?
A standard def view is synchronous — it blocks the thread until the response is returned. An async def view is asynchronous — it can await non-blocking operations (external API calls, async database queries using sync_to_async) without blocking the server thread. Async views in Django are served by ASGI servers like Uvicorn or Daphne instead of WSGI servers like Gunicorn. For most CRUD applications, sync views are sufficient — async views shine in high-concurrency scenarios with external I/O.
Modules, Packages & Python Internals
Q29. What is the difference between a module and a package in Python?
A module is a single .py file containing Python code. A package is a directory containing multiple modules and an __init__.py file that marks it as a package. In Django, your entire application is structured as a package — each Django app is a package with its own models.py, views.py, urls.py modules. Understanding this structure is fundamental to organizing large Django projects with multiple apps.
Q30. What is __init__.py and what does it do?
__init__.py makes a directory recognizable as a Python package so it can be imported. It can be empty or contain initialization code that runs when the package is first imported — like registering signal handlers or setting default configurations. In Django, __init__.py files in each app directory allow Django to discover and import app modules. As of Python 3.3+, “namespace packages” can exist without __init__.py, but explicit __init__.py files remain standard practice in Django projects.
Q31. What is the difference between import module and from module import something?
import module imports the entire module object — you access its contents using module.something. from module import something imports only the specified name directly into the current namespace. In Django, from django.db import models is used rather than import django.db followed by django.db.models everywhere — it is cleaner and more explicit. However, wildcard imports (from module import *) are considered bad practice as they pollute the namespace and make code harder to debug.
Q32. What is __name__ == “__main__” used for?
When Python runs a file directly, it sets __name__ to “__main__”. When the file is imported as a module, __name__ is set to the module’s name instead. The if __name__ == “__main__”: guard prevents certain code from running when the file is imported. In Django projects, this pattern is used in management command scripts and utility scripts that should only execute when run directly — not when imported by the Django framework.
Functional Programming
Q33. What are lambda functions and when should you use them?
Lambda functions are anonymous, single-expression functions defined with the lambda keyword. They are used for short, throwaway functions — most commonly as arguments to sorted(), map(), or filter(). In Django, they appear in admin configurations like list_display with custom column logic. However, lambdas are limited to a single expression and have no name, making them harder to test and debug — for anything beyond trivial use, a named function is preferred.
Q34. What is the difference between map(), filter(), and reduce()?
map() applies a function to every element in an iterable and returns a map object. filter() returns only the elements for which the function returns True. reduce() (from functools) applies a function cumulatively to reduce an iterable to a single value — like summing all numbers in a list. In modern Python, list comprehensions and generator expressions are generally preferred over map() and filter() for readability, but knowing these functions is expected in interviews.
Q35. What are list comprehensions and when should you use them?
List comprehensions provide a concise way to create lists from existing iterables, combining a for loop and optional if condition in a single line. They are generally faster than equivalent for loops because they are optimized at the C level in CPython. In Django views, they are commonly used for transforming querysets — for example, extracting a list of email addresses from a User queryset. For complex logic with multiple conditions or nested loops, a regular for loop is more readable.
Miscellaneous & Interview Favorites
Q36. What is the difference between __str__ and __repr__?
__str__ is meant for end-user-friendly output — it is called by print() and str(). __repr__ is meant for developer-facing output — it should ideally return a string that, when passed to eval(), recreates the object. When __str__ is not defined, Python falls back to __repr__. In Django models, defining __str__ is mandatory good practice — it determines how model instances appear in the admin panel, shell queries, and log messages.
Q37. What is pickling in Python?
Pickling is the process of serializing a Python object into a byte stream so it can be stored or transmitted, and unpickling is the reverse. Python’s pickle module handles this. In web development, pickling is used under the hood by Django’s cache framework when storing complex Python objects in Redis or Memcached. However, you should never unpickle data from untrusted sources — it is a known security vulnerability because unpickling can execute arbitrary code.
Q38. What is monkey patching and why is it risky in production?
Monkey patching means dynamically modifying a class or module at runtime — replacing or adding attributes and methods after the code is loaded. It is sometimes used in testing to mock external services. In production, it is risky because it makes code behaviour unpredictable, breaks IDE tooling and static analysis, and can cause extremely difficult-to-debug failures when framework updates change the code being patched. Django explicitly discourages monkey patching core framework components.
Q39. What is the difference between == and is for None comparisons?
Always use is None or is not None — never == None. This is because None is a singleton in Python — there is exactly one None object in memory, so identity comparison (is) is both more semantically correct and marginally faster. Using == with None works in practice but can be overridden by a custom __eq__ method, leading to subtle bugs. PEP 8 explicitly recommends is None for this reason.
Q40. How does Python manage memory, and what is garbage collection?
Python uses reference counting as its primary memory management strategy — every object tracks how many references point to it, and when the count reaches zero, the memory is freed immediately. However, reference counting cannot handle circular references (A points to B, B points to A) — for this, Python’s cyclic garbage collector periodically scans for and cleans up circular reference cycles. In long-running Django web servers, memory leaks from uncollected circular references or large in-memory caches are a real production concern.
Part 3: Django & Django REST Framework — 50 Interview Questions & Answers
Q1. What is Django?
Django is a high-level Python web framework used to build secure, scalable, and maintainable web applications quickly. It follows the “batteries included” philosophy, meaning it provides built-in tools for authentication, admin panels, ORM, routing, forms, and security.
Q2. What does MVT stand for in Django?
MVT stands for Model, View, Template. The Model handles data and database logic, the View handles business logic and request processing, and the Template handles the presentation layer shown to the user.
Q3. How is MVT different from MVC?
Django’s MVT is similar to MVC but with different naming. In Django, the View behaves like a controller, and the Template behaves like the view in MVC. The framework itself handles much of the controller logic internally.
Q4. What is a Django project?
A Django project is the full web application configuration container. It includes global settings, root URLs, middleware configuration, installed apps, and deployment-related configuration.
Q5. What is a Django app?
A Django app is a self-contained module that performs a specific function inside a project. For example, a blog app, authentication app, or payments app can all exist inside the same Django project.
Q6. What is manage.py in Django?
manage.py is Django’s command-line utility for administrative tasks. It is used to run the development server, create apps, apply migrations, open the shell, create superusers, and run tests.
Q7. What is the role of settings.py?
settings.py contains the configuration for the Django project. It defines installed apps, middleware, database settings, static files configuration, authentication options, and other environment-level settings.
Q8. What is urls.py used for?
urls.py maps incoming URLs to specific views. It acts as the routing layer of the application and tells Django which logic should run for each URL pattern.
Q9. What is a view in Django?
A view is a Python function or class that receives an HTTP request and returns an HTTP response. It contains the business logic of the application, such as fetching database records, validating input, or rendering templates.
Q10. What is a model in Django?
A model is a Python class that represents a database table. Each attribute in the model maps to a database column, and Django automatically generates SQL schema from the model definitions.
Q11. What is a template in Django?
A template is an HTML file that can include Django Template Language for dynamic content. It is used to display data sent from views in a structured and reusable way.
Q12. What is the Django ORM?
ORM stands for Object-Relational Mapper. Django ORM lets developers interact with the database using Python classes and methods instead of writing raw SQL for common database operations.
Q13. What is a QuerySet in Django?
A QuerySet is a collection of database queries built from a Django model. It represents a lazy database lookup, meaning the query is not executed until the data is actually needed.
Q14. What is the difference between get() and filter()?
get() returns exactly one object and raises an error if none or multiple objects are found. filter() returns a QuerySet and can return zero, one, or many matching objects.
Q15. What is the difference between select_related() and prefetch_related()?
select_related() is used for foreign key and one-to-one relationships and performs a SQL join to fetch related objects in one query. prefetch_related() is used for many-to-many and reverse foreign key relationships and performs separate queries, then combines the results in Python.
Q16. What is the N+1 query problem in Django?
The N+1 query problem happens when one query fetches a list of objects, and then one extra query is made for each related object. This causes major performance issues and is usually fixed with select_related() or prefetch_related().
Q17. What are migrations in Django?
Migrations are Django’s way of tracking and applying database schema changes. When models change, migrations generate the corresponding database changes in a controlled and versioned way.
Q18. What is the difference between makemigrations and migrate?
makemigrations creates migration files based on model changes. migrate applies those migration files to the actual database.
Q19. What is a primary key in Django models?
A primary key uniquely identifies each row in a database table. Django automatically adds an id primary key field unless a custom primary key is explicitly defined.
Q20. What is on_delete in a ForeignKey?
on_delete defines what should happen when the referenced parent object is deleted. Common options include CASCADE, SET_NULL, PROTECT, and DO_NOTHING, depending on the desired data integrity behavior.
Q21. What is __str__() used for in Django models?
__str__() returns a readable string representation of a model instance. It is especially useful in the Django admin panel, shell, and logs to identify objects clearly.
Q22. What is the Django admin panel?
The Django admin panel is a built-in interface for managing application data. It allows authorized users to create, update, delete, and search records without building a custom UI.
Q23. What is a superuser in Django?
A superuser is an admin account with full permissions across the Django project. It can access the admin panel and manage all models and users.
Q24. What is middleware in Django?
Middleware is a layer that processes requests and responses globally before they reach the view or before they are sent back to the client. It is used for tasks like authentication, session management, security, and logging.
Q25. What is the difference between session-based authentication and token-based authentication?
Session-based authentication stores user session data on the server and typically works well for traditional web apps with templates. Token-based authentication uses a token sent with each request and is more suitable for APIs, SPAs, and mobile apps.
Q26. What is CSRF in Django?
CSRF stands for Cross-Site Request Forgery. It is an attack where a malicious site tricks a user’s browser into making unwanted requests to another site, and Django protects against it using CSRF tokens in forms.
Q27. What is XSS and how does Django help prevent it?
XSS stands for Cross-Site Scripting, where malicious scripts are injected into web pages viewed by others. Django helps prevent XSS by escaping template output by default unless explicitly marked safe.
Q28. What is SQL injection and how does Django prevent it?
SQL injection is an attack where malicious SQL is inserted into user input to manipulate the database. Django ORM helps prevent this by parameterizing queries automatically instead of directly concatenating SQL strings.
Q29. What is Django REST Framework (DRF)?
Django REST Framework is a powerful toolkit for building Web APIs in Django. It provides serializers, authentication, permissions, pagination, browsable API support, and class-based utilities for API development.
Q30. What is a serializer in DRF?
A serializer converts complex data such as Django model instances into JSON or other formats, and also validates and converts incoming request data into Python objects. It plays a role similar to Django forms for APIs.
Q31. What is the difference between Serializer and ModelSerializer?
Serializer requires fields to be defined manually and gives more control. ModelSerializer automatically generates fields and validation rules based on a Django model, making it faster for standard CRUD APIs.
Q32. What is an APIView in DRF?
APIView is a class-based view in DRF that provides more control over request handling than standard Django views. It supports authentication, permissions, throttling, and different HTTP methods in a clean structure.
Q33. What is a ViewSet in DRF?
A ViewSet groups common API actions like list, create, retrieve, update, and delete into a single class. It reduces repetition and works well with routers for RESTful API design.
Q34. What is a router in DRF?
A router automatically generates URL patterns for ViewSets. Instead of manually writing multiple URLs for CRUD operations, the router maps standard actions to appropriate endpoints.
Q35. What is the difference between function-based views and class-based views in Django?
Function-based views are simple and easy to understand for small logic. Class-based views provide more structure, reusability, and extensibility, especially for large applications and repeated patterns.
Q36. What is the difference between authentication and authorization?
Authentication verifies who the user is, while authorization verifies what the user is allowed to do. For example, logging in is authentication, while checking if the user can delete a post is authorization.
Q37. What are permissions in DRF?
Permissions define whether a request should be allowed to access a view or action. DRF provides built-in permission classes like IsAuthenticated, IsAdminUser, and AllowAny, and also supports custom permission logic.
Q38. What is JWT authentication?
JWT stands for JSON Web Token. It is a token-based authentication method where the server issues a signed token after login, and the client includes that token in future requests for authentication.
Q39. What is pagination in DRF?
Pagination splits large sets of API results into smaller pages. This improves performance, reduces response size, and provides a better client experience when working with large datasets.
Q40. What is throttling in DRF?
Throttling limits how many requests a client can make in a given period. It helps protect APIs from abuse, accidental overuse, and denial-of-service style traffic spikes.
Q41. What is filtering in DRF?
Filtering allows API clients to request only the data they need by applying conditions such as category, date, or status. It improves usability and reduces unnecessary data transfer.
Q42. What is the difference between PUT and PATCH in DRF?
PUT is generally used to replace an entire resource, while PATCH is used to partially update only specific fields of a resource. In practice, PATCH is commonly used for small updates in APIs.
Q43. What are signals in Django?
Signals allow certain senders to notify receivers when specific actions occur, such as saving or deleting a model. They are useful for decoupled event handling, but overusing them can make code harder to trace and maintain.
Q44. What is Celery and why is it used with Django?
Celery is a distributed task queue used for background processing. It is commonly used in Django for sending emails, generating reports, processing uploads, and other tasks that should not block the main request-response cycle.
Q45. What is Redis commonly used for in Django projects?
Redis is commonly used for caching, session storage, rate limiting, and as a message broker for Celery. It is fast because it stores data in memory.
Q46. What is caching in Django?
Caching stores expensive or frequently accessed data temporarily so it can be served faster on future requests. Django supports per-site, per-view, template fragment, and low-level caching strategies.
Q47. What is Django Channels?
Django Channels extends Django to handle protocols beyond HTTP, especially WebSockets. It is used for real-time applications like chat apps, live notifications, and multiplayer features.
Q48. What is the difference between WSGI and ASGI?
WSGI is the traditional Python web server interface for synchronous applications. ASGI is the newer standard that supports asynchronous features like WebSockets, long-lived connections, and async views.
Q49. What is get_queryset() used for in Django class-based views?
get_queryset() is used to customize the set of objects returned by a class-based view. It is commonly overridden to filter records based on the current user, request parameters, or business rules.
Q50. How do you optimize a Django application for production?
A Django application is optimized by reducing database queries, using select_related() and prefetch_related(), enabling caching, serving static files efficiently, running behind Gunicorn or Uvicorn with NGINX, securing settings, monitoring errors, and using background workers for heavy tasks.
Explore Python Full Stack Career Guide→
Part 4: Flask & FastAPI — 30 Interview Questions & Answers
Q1. What is Flask?
Flask is a lightweight Python web framework used to build web applications and APIs. It is called a microframework because it provides the essentials for web development without forcing a large set of built-in tools like a full-stack framework does.
Q2. Why is Flask called a microframework?
Flask is called a microframework because it keeps the core small and flexible. It includes routing, request handling, and templating, but leaves choices like ORM, form handling, and authentication to extensions or the developer.
Q3. What is FastAPI?
FastAPI is a modern Python web framework designed for building APIs quickly with high performance. It is especially known for async support, automatic validation, and automatic API documentation.
Q4. What is the main difference between Flask and FastAPI?
Flask is more minimal and flexible, making it a good choice for custom lightweight applications. FastAPI is more opinionated for API development and provides built-in request validation, type-based documentation, and strong async capabilities.
Q5. When would you choose Flask over FastAPI?
Flask is a good choice when you want simplicity, full control over architecture, or when working on small to medium projects where you prefer choosing each component yourself. It is also common in legacy codebases and teams already familiar with its ecosystem.
Q6. When would you choose FastAPI over Flask?
FastAPI is a strong choice when building modern APIs, especially when performance, async support, automatic validation, and auto-generated docs are important. It is especially suitable for microservices, AI backends, and API-first products.
Q7. What is routing in Flask?
Routing in Flask maps a URL to a Python function. When a request comes to a specific path, Flask executes the associated function and returns a response.
Q8. What is routing in FastAPI?
Routing in FastAPI maps a path and HTTP method to a function. It supports path parameters, query parameters, headers, cookies, and request body handling in a structured way.
Q9. What is the application factory pattern in Flask?
The application factory pattern is a way of creating Flask apps using a function instead of a single global app instance. It makes the project easier to test, configure for different environments, and scale in a clean way.
Q10. What are Blueprints in Flask?
Blueprints are a way to organize a Flask application into reusable modules. They help split routes, templates, and logic into separate components so large applications remain maintainable.
Q11. How is project structure typically handled in Flask?
Flask gives developers flexibility in structure, but large projects usually separate routes, models, services, templates, static files, and configuration into different modules. Blueprints are often used to keep features isolated and modular.
Q12. What is Jinja2 in Flask?
Jinja2 is the template engine used by Flask to render dynamic HTML pages. It allows developers to insert variables, loops, conditions, and reusable blocks into templates.
Q13. What is request context in Flask?
Request context contains request-specific data such as headers, form data, query parameters, and session information. It exists only during the lifetime of a request and allows Flask to access request data cleanly.
Q14. What is application context in Flask?
Application context gives access to application-level objects like configuration and global application state. It allows code to use app-level resources without directly passing the app object everywhere.
Q15. What are request, session, and g in Flask?
request contains data about the current HTTP request. session stores data across requests for a specific user, and g is used to store temporary data during a single request, such as a database connection or current user info.
Q16. How is configuration managed in Flask?
Flask configuration is usually managed through configuration classes, environment variables, or separate files for development, testing, and production. This makes it easier to use different settings across environments.
Q17. How do you handle forms in Flask?
Forms in Flask can be handled using normal request parsing or with tools like Flask-WTF for validation and CSRF protection. For APIs, form handling is often replaced by JSON request body validation.
Q18. How is database integration typically done in Flask?
Flask does not include an ORM by default, so developers commonly use SQLAlchemy for database interaction and Flask-Migrate for schema migrations. This keeps the framework flexible but requires more setup than Django.
Q19. What is Flask-SQLAlchemy?
Flask-SQLAlchemy is an extension that integrates SQLAlchemy with Flask in a simpler and more convenient way. It helps manage database models, sessions, and queries inside a Flask application.
Q20. What is Flask-Migrate?
Flask-Migrate is an extension that handles database migrations in Flask applications. It works with SQLAlchemy models and helps track schema changes over time.
Q21. What is Pydantic and why is it important in FastAPI?
Pydantic is a data validation library that uses Python type hints to define schemas. In FastAPI, it is central to request validation, response formatting, and error handling for API data.
Q22. How does FastAPI use type hints?
FastAPI uses Python type hints to understand expected input and output types. It uses them to validate request data, generate API documentation, and improve editor support and code readability.
Q23. What are request models in FastAPI?
Request models in FastAPI define the structure and validation rules for incoming request data. They ensure that the client sends the correct fields and data types before the application processes the request.
Q24. What are response models in FastAPI?
Response models define the structure of the data returned to the client. They help ensure consistency, prevent accidental exposure of unwanted fields, and improve API documentation.
Q25. What is Depends in FastAPI?
Depends is FastAPI’s dependency injection mechanism. It is used to provide reusable logic such as authentication checks, database sessions, or shared services to route handlers in a clean and modular way.
Q26. How does FastAPI generate Swagger/OpenAPI docs automatically?
FastAPI reads route definitions, type hints, request models, response models, and metadata to automatically generate OpenAPI documentation. This documentation is then displayed through interactive Swagger UI and ReDoc interfaces.
Q27. What is the difference between def and async def in FastAPI?
def is used for synchronous route handlers, while async def is used for asynchronous handlers. Async handlers are useful when dealing with non-blocking I/O tasks such as external API calls, streaming, or async database operations.
Q28. What is middleware in FastAPI?
Middleware in FastAPI is code that runs before and after each request. It is used for tasks like logging, authentication, CORS handling, request timing, and modifying responses globally.
Q29. How are background tasks handled in FastAPI?
FastAPI supports background tasks for work that should run after sending the response, such as sending emails or logging events. This improves responsiveness by keeping the main request fast.
Q30. How do you compare Flask and FastAPI in production?
Flask is mature, stable, and flexible, making it suitable for many traditional web and API applications. FastAPI is often preferred for modern API-heavy systems because of its validation, async support, documentation, and strong developer experience, especially in microservice and AI-driven environments.
Part 5: HTML, CSS & JavaScript — 40 Interview Questions & Answers
Q1. What is HTML?
HTML stands for HyperText Markup Language. It is the standard markup language used to structure content on web pages such as headings, paragraphs, images, links, tables, and forms.
Q2. What is the difference between HTML and HTML5?
HTML5 is the modern version of HTML and introduced semantic tags, audio and video support, improved form controls, canvas, local storage, and better support for modern web applications. It also reduced the need for many third-party plugins.
Q3. What are semantic HTML tags?
Semantic HTML tags clearly describe the meaning of the content they contain. Examples include header, nav, main, section, article, aside, and footer, and they improve accessibility, SEO, and code readability.
Q4. Why is semantic HTML important?
Semantic HTML helps search engines understand page structure, improves accessibility for screen readers, and makes code easier for developers to maintain. It also supports better SEO and cleaner markup.
Q5. What is the difference between block-level and inline elements?
Block-level elements take the full available width and start on a new line, such as div, p, and section. Inline elements only take as much width as needed and do not start on a new line, such as span, a, and strong.
Q6. What is the difference between id and class in HTML?
An id uniquely identifies a single element on a page and should not be reused. A class can be shared by multiple elements and is mainly used for grouping elements for styling or JavaScript behavior.
Q7. What is the purpose of the alt attribute in images?
The alt attribute provides alternative text for an image if it cannot be displayed. It is also important for accessibility because screen readers use it to describe images to visually impaired users.
Q8. What are forms in HTML?
Forms are used to collect user input through elements like input fields, textareas, checkboxes, radio buttons, dropdowns, and buttons. They are essential for login pages, registrations, searches, and contact forms.
Q9. What is the difference between GET and POST in HTML forms?
GET sends data in the URL and is mainly used for retrieving data, such as search requests. POST sends data in the request body and is used for submitting sensitive or larger amounts of data, such as login or registration forms.
Q10. What is CSS?
CSS stands for Cascading Style Sheets. It is used to control the presentation of HTML elements, including colors, spacing, fonts, layout, responsiveness, and animations.
Q11. What is the CSS box model?
The CSS box model describes how every HTML element is represented as a box made of content, padding, border, and margin. Understanding this model is essential for layout and spacing.
Q12. What is the difference between margin and padding?
Padding is the space inside an element, between the content and the border. Margin is the space outside the element, separating it from neighboring elements.
Q13. What is the difference between display: none and visibility: hidden?
display: none removes the element completely from the layout, so it does not take up any space. visibility: hidden hides the element visually but still keeps its space reserved in the layout.
Q14. What is the difference between position: relative, absolute, fixed, and sticky?
relative positions an element relative to its normal position. absolute positions an element relative to the nearest positioned ancestor. fixed positions an element relative to the viewport, and sticky behaves like relative until a scroll threshold is reached, then sticks in place.
Q15. What is Flexbox in CSS?
Flexbox is a one-dimensional layout system used for arranging elements in a row or column. It makes it easy to align, distribute, and space items dynamically within a container.
Q16. What is CSS Grid?
CSS Grid is a two-dimensional layout system used for arranging items in rows and columns. It is ideal for more complex layouts where both horizontal and vertical alignment matter.
Q17. What is the difference between Flexbox and Grid?
Flexbox is best for one-dimensional layouts, such as a row of buttons or a vertical menu. Grid is better for two-dimensional layouts, such as dashboards, galleries, or full-page structures with both rows and columns.
Q18. What are media queries in CSS?
Media queries are used to apply different styles based on device properties such as screen width, height, or orientation. They are the foundation of responsive web design.
Q19. What is responsive design?
Responsive design is the practice of making web pages adapt smoothly to different screen sizes and devices. It ensures a site works well on desktops, tablets, and mobile phones.
Q20. What is CSS specificity?
CSS specificity determines which style rule is applied when multiple rules target the same element. Inline styles have the highest specificity, followed by IDs, then classes, attributes, and pseudo-classes, and finally element selectors.
Q21. What is JavaScript?
JavaScript is a programming language used to make web pages interactive. It can manipulate the DOM, handle events, perform validations, fetch data from APIs, and control dynamic user interfaces.
Q22. What is the difference between var, let, and const?
var is function-scoped and can be redeclared, which can lead to unexpected behavior. let is block-scoped and can be reassigned, while const is also block-scoped but cannot be reassigned after declaration.
Q23. What is hoisting in JavaScript?
Hoisting is JavaScript’s behavior of moving declarations to the top of their scope before execution. Function declarations are fully hoisted, while variables declared with var are hoisted but initialized as undefined, and let and const are hoisted but remain inaccessible until declared.
Q24. What is the difference between == and === in JavaScript?
== checks value equality after type coercion, which can lead to unexpected results. === checks both value and type equality, so it is safer and preferred in modern JavaScript.
Q25. What is a closure in JavaScript?
A closure is created when a function remembers variables from its outer scope even after that outer function has finished executing. Closures are commonly used for data privacy, callbacks, and maintaining state.
Q26. What is the DOM?
DOM stands for Document Object Model. It is the browser’s in-memory representation of an HTML page, allowing JavaScript to read, update, add, or remove elements dynamically.
Q27. What is event bubbling in JavaScript?
Event bubbling is the process where an event starts from the target element and then propagates upward through its parent elements. It is useful for event delegation and shared event handling.
Q28. What is event delegation?
Event delegation is a technique where a parent element handles events for its child elements using bubbling. It improves performance and works well for dynamically created elements.
Q29. What is the difference between synchronous and asynchronous JavaScript?
Synchronous JavaScript executes one statement at a time in sequence, blocking the next step until the current one finishes. Asynchronous JavaScript allows long-running tasks like API calls or timers to run without blocking the rest of the program.
Q30. What is a Promise in JavaScript?
A Promise is an object that represents the eventual completion or failure of an asynchronous operation. It helps manage async code more cleanly than deeply nested callbacks.
Q31. What is async/await in JavaScript?
async/await is a cleaner way to work with Promises. It makes asynchronous code look more like synchronous code, improving readability and error handling.
Q32. What is the JavaScript event loop?
The event loop is the mechanism that allows JavaScript to handle asynchronous operations even though it runs on a single thread. It monitors the call stack and callback queue and executes pending tasks when the stack is empty.
Q33. What is the difference between null and undefined in JavaScript?
undefined means a variable has been declared but not assigned a value. null is an intentional assignment representing the absence of a value.
Q34. What is the spread operator in JavaScript?
The spread operator expands elements from an array or properties from an object into another array or object. It is often used for copying, merging, and updating data in a clean way.
Q35. What is destructuring in JavaScript?
Destructuring is a shorthand syntax for extracting values from arrays or properties from objects into variables. It improves readability and is commonly used in modern frontend development.
Q36. What is CORS?
CORS stands for Cross-Origin Resource Sharing. It is a browser security mechanism that controls whether a web page from one origin can access resources from another origin.
Q37. What is localStorage and how is it different from sessionStorage?
localStorage stores data in the browser with no expiration until it is manually cleared. sessionStorage stores data only for the duration of the browser tab session and is cleared when the tab is closed.
Q38. What is the difference between cookies, localStorage, and sessionStorage?
Cookies are small pieces of data sent with HTTP requests and often used for authentication and session tracking. localStorage and sessionStorage store data only on the client side, with localStorage being persistent and sessionStorage temporary.
Q39. What is debouncing in JavaScript?
Debouncing is a technique that delays the execution of a function until a certain amount of time has passed since the last event. It is commonly used in search boxes, resize events, and form validation to improve performance.
Q40. What is throttling in JavaScript?
Throttling is a technique that limits how often a function can run within a given time period. It is useful for scroll events, mouse movement, and resize handling where too many rapid executions would hurt performance.
Part 6: React.js — 40 Interview Questions & Answers
Q1. What is React?
React is a JavaScript library for building user interfaces, especially single-page applications. It uses a component-based approach that helps developers build reusable and maintainable UI pieces.
Q2. What is a component in React?
A component is a reusable building block of a React application. It can represent a button, form, navbar, product card, or even an entire page.
Q3. What is the difference between functional components and class components?
Functional components are plain JavaScript functions that return UI and use hooks for state and lifecycle behavior. Class components are older, use this and lifecycle methods, and are now less common in modern React applications.
Q4. What is JSX?
JSX stands for JavaScript XML and is a syntax extension that allows developers to write HTML-like code inside JavaScript. React uses JSX to describe what the UI should look like in a readable way.
Q5. What are props in React?
Props are inputs passed from a parent component to a child component. They are read-only and are used to make components dynamic and reusable.
Q6. What is state in React?
State is data managed inside a component that can change over time. When state changes, React re-renders the component so the UI stays in sync with the data.
Q7. What is the difference between props and state?
Props are passed from parent to child and cannot be modified by the receiving component. State is managed within the component itself and can be updated over time.
Q8. What is the Virtual DOM?
The Virtual DOM is a lightweight in-memory representation of the real DOM. React uses it to detect changes efficiently and update only the parts of the real DOM that actually need to change.
Q9. What is reconciliation in React?
Reconciliation is the process React uses to compare the previous Virtual DOM with the new Virtual DOM after state or props change. It then updates the real DOM in the most efficient way possible.
Q10. What are hooks in React?
Hooks are special functions that let functional components use state, lifecycle behavior, context, refs, and other React features. They made functional components the standard in modern React development.
Q11. What is useState?
useState is a React hook used to add state to a functional component. It returns the current state value and a function to update that value.
Q12. What is useEffect?
useEffect is a hook used to handle side effects in functional components, such as API calls, subscriptions, timers, or manual DOM changes. It runs after rendering and can also perform cleanup when needed.
Q13. What is the dependency array in useEffect?
The dependency array controls when the effect runs. If it is empty, the effect runs once after the first render; if it contains values, the effect runs whenever one of those values changes; if omitted, it runs after every render.
Q14. What is cleanup in useEffect?
Cleanup is logic returned from useEffect that runs before the effect runs again or when the component unmounts. It is used to remove event listeners, cancel subscriptions, or clear timers to prevent memory leaks.
Q15. What is useRef?
useRef is a hook that stores a mutable value that persists across renders without causing re-renders. It is commonly used to reference DOM elements or store values like timer IDs and previous data.
Q16. What is useContext?
useContext is a hook used to access data from a React context. It helps avoid prop drilling by making shared data available to many components directly.
Q17. What is prop drilling?
Prop drilling happens when data is passed through several intermediate components just to reach a deeply nested child. It can make component trees harder to maintain and is often reduced using Context API or state management libraries.
Q18. What is the Context API?
The Context API is React’s built-in way to share data across components without manually passing props through every level. It is useful for global values like theme, authentication, language, or user preferences.
Q19. What is useMemo?
useMemo is a hook that memoizes the result of an expensive calculation so it is not recomputed on every render unless its dependencies change. It is used for performance optimization when calculations are costly.
Q20. What is useCallback?
useCallback is a hook that memoizes a function so the same function reference is reused between renders unless dependencies change. It is useful when passing callbacks to child components that rely on reference equality.
Q21. What is the difference between useMemo and useCallback?
useMemo memoizes a computed value, while useCallback memoizes a function. In simple terms, one stores a result and the other stores a function reference.
Q22. What is React.memo?
React.memo is a higher-order component that prevents a functional component from re-rendering if its props have not changed. It is useful for optimizing expensive components.
Q23. What are keys in React lists?
Keys are unique identifiers assigned to elements in a list. They help React track which items changed, were added, or were removed during reconciliation.
Q24. Why should array indexes usually not be used as keys?
Indexes can lead to incorrect UI updates when items are inserted, removed, or reordered. Stable unique IDs are preferred because they help React correctly identify list items over time.
Q25. What is a controlled component in React?
A controlled component is a form element whose value is managed by React state. This gives React full control over the form data and is useful for validation and dynamic behavior.
Q26. What is an uncontrolled component in React?
An uncontrolled component stores its value in the DOM rather than in React state. It is typically accessed using refs and is less common when full form control is needed.
Q27. What is lifting state up in React?
Lifting state up means moving shared state to the nearest common parent of the components that need it. This allows multiple child components to stay in sync using the same source of truth.
Q28. What is conditional rendering in React?
Conditional rendering means showing different UI elements based on a condition. It is commonly used for authentication states, loading screens, error messages, and feature toggles.
Q29. What is React Router?
React Router is a library used for client-side routing in React applications. It allows navigation between pages or views without refreshing the browser.
Q30. What is lazy loading in React?
Lazy loading means loading components only when they are needed instead of loading the entire app upfront. It improves performance by reducing the initial bundle size.
Q31. What is code splitting in React?
Code splitting is the process of breaking the application bundle into smaller chunks that can be loaded on demand. It helps improve initial page load speed and overall performance.
Q32. What is Redux?
Redux is a state management library used to manage global application state in a predictable way. It is useful in larger applications where many components need access to shared data.
Q33. What is Redux Toolkit?
Redux Toolkit is the recommended modern way to use Redux. It reduces boilerplate, simplifies store setup, and provides utilities for writing cleaner Redux logic.
Q34. When should you use Context API vs Redux?
Context API is suitable for simpler shared state like themes, user settings, or auth state. Redux is better when the application has complex global state, many updates, or needs better debugging and structure.
Q35. What is React Query or TanStack Query used for?
React Query, now called TanStack Query, is used for fetching, caching, synchronizing, and updating server data in React applications. It simplifies API state management compared to manually using useEffect and state.
Q36. What is a custom hook in React?
A custom hook is a reusable function that contains React hook logic. It allows developers to extract and reuse stateful behavior across multiple components.
Q37. What are portals in React?
Portals let a component render its output outside its normal parent DOM hierarchy. They are commonly used for modals, tooltips, and dropdowns that need to escape layout restrictions.
Q38. What are React 19 features commonly discussed in interviews?
React 19 discussions often include server components, actions, improved form handling, compiler-related optimizations, and new patterns that reduce the need for manual performance tuning in some cases. Interviewers mainly expect awareness of these trends rather than deep implementation details unless the role is frontend-heavy.
Q39. How do you optimize performance in a React application?
Performance is optimized by reducing unnecessary re-renders, using memoization carefully, splitting code, lazy loading components, optimizing state structure, and avoiding large expensive computations during render. Good API data handling and efficient list rendering also matter.
Q40. Why is React so popular in frontend development?
React is popular because it is flexible, component-based, backed by a strong ecosystem, and widely used in industry. It makes it easier to build complex interactive UIs while keeping code modular and maintainable.
Part 7: REST APIs, Databases & SQL — 40 Interview Questions & Answers
Q1. What is an API?
An API, or Application Programming Interface, is a way for different software systems to communicate with each other. In web development, APIs allow frontend applications, mobile apps, and other services to interact with backend systems.
Q2. What is a REST API?
A REST API is an API that follows REST principles and uses standard HTTP methods to perform operations on resources. It is designed around resources such as users, products, or orders, which are accessed using URLs.
Q3. What does REST stand for?
REST stands for Representational State Transfer. It is an architectural style for designing networked applications that emphasizes stateless communication and resource-based URLs.
Q4. What are HTTP methods commonly used in REST APIs?
The most common HTTP methods are GET for reading data, POST for creating data, PUT for replacing data, PATCH for partially updating data, and DELETE for removing data.
Q5. What is the difference between PUT and PATCH?
PUT is generally used to replace an entire resource, while PATCH is used to update only specific fields of a resource. PATCH is often preferred for partial updates because it avoids sending the full object again.
Q6. What does it mean for an API to be stateless?
A stateless API does not store client-specific session data between requests. Each request must contain all the information needed for the server to process it.
Q7. What is idempotency in REST APIs?
Idempotency means that making the same request multiple times produces the same effect as making it once. For example, repeated DELETE requests on the same resource should still leave it deleted.
Q8. Which HTTP methods are idempotent?
GET, PUT, DELETE, and usually PATCH are considered idempotent depending on implementation. POST is generally not idempotent because repeated requests may create multiple resources.
Q9. What are HTTP status codes?
HTTP status codes are numeric responses from the server that indicate the result of a request. They help clients understand whether a request succeeded, failed, or needs additional action.
Q10. What is the difference between 200, 201, 400, 401, 403, and 404?
200 means the request succeeded, 201 means a resource was created, 400 means a bad request, 401 means authentication is required or failed, 403 means access is forbidden even if authenticated, and 404 means the requested resource was not found.
Q11. What is pagination in APIs?
Pagination is the process of splitting large API results into smaller chunks or pages. It improves performance and makes it easier for clients to consume large datasets efficiently.
Q12. Why is filtering useful in APIs?
Filtering allows clients to request only the records they need, such as products in a category or users from a specific city. This reduces unnecessary data transfer and improves API usability.
Q13. What is API versioning?
API versioning is the practice of managing changes to an API without breaking existing clients. It is often done through the URL, headers, or query parameters.
Q14. What is authentication in APIs?
Authentication is the process of verifying who the client or user is. It ensures that only valid users or systems can access the API.
Q15. What is authorization in APIs?
Authorization determines what an authenticated user is allowed to do. For example, one user may only read data, while an admin user can create, update, and delete records.
Q16. What is JWT?
JWT stands for JSON Web Token. It is a compact token format used to securely transfer authentication information between client and server.
Q17. What are the advantages of JWT?
JWT is stateless, compact, and easy to use across web and mobile applications. It allows servers to validate user identity without storing session data on the server side.
Q18. What are the disadvantages of JWT?
JWTs are harder to revoke once issued unless a blacklist or short expiry strategy is used. They also need secure storage because a leaked token can be misused until it expires.
Q19. What is OAuth?
OAuth is an authorization framework that allows third-party applications to access user data without exposing the user’s password. It is commonly used for “Login with Google” or “Login with GitHub” flows.
Q20. What is the difference between JWT and OAuth?
JWT is a token format used to carry authentication or authorization data, while OAuth is a framework for delegated authorization. OAuth may use JWT internally, but they solve different problems.
Q21. What is CORS in APIs?
CORS stands for Cross-Origin Resource Sharing. It is a browser security feature that controls whether frontend applications from one origin can access resources from another origin.
Q22. What is rate limiting?
Rate limiting restricts how many requests a client can make in a given time period. It protects APIs from abuse, accidental overload, and denial-of-service style traffic spikes.
Q23. What is caching in APIs?
Caching stores previously generated responses so they can be reused instead of recomputing or refetching data every time. It improves performance and reduces server load.
Q24. What is SQL?
SQL stands for Structured Query Language. It is the standard language used to manage and query relational databases.
Q25. What is a relational database?
A relational database stores data in tables made of rows and columns, with relationships between tables defined using keys. Examples include PostgreSQL, MySQL, and SQL Server.
Q26. What is the difference between SQL and NoSQL databases?
SQL databases use structured tables and fixed schemas, making them strong for relationships and transactions. NoSQL databases are more flexible in schema design and are often used for document, key-value, or large-scale distributed workloads.
Q27. What is a primary key?
A primary key is a column or set of columns that uniquely identifies each row in a table. It ensures no duplicate rows exist for that identifier.
Q28. What is a foreign key?
A foreign key is a column in one table that references the primary key of another table. It is used to create relationships between tables and maintain referential integrity.
Q29. What is normalization?
Normalization is the process of organizing data to reduce redundancy and improve consistency. It usually involves splitting data into related tables based on logical structure.
Q30. What is denormalization?
Denormalization is the intentional addition of redundancy to improve read performance. It is often used when faster queries are more important than strict normalization.
Q31. What is a JOIN in SQL?
A JOIN combines rows from two or more tables based on a related column. It is used when data is split across tables and needs to be retrieved together.
Q32. What is the difference between INNER JOIN and LEFT JOIN?
INNER JOIN returns only matching records from both tables. LEFT JOIN returns all rows from the left table and the matching rows from the right table, filling missing matches with nulls.
Q33. What is GROUP BY in SQL?
GROUP BY is used to group rows that have the same values in specified columns. It is commonly used with aggregate functions like COUNT, SUM, AVG, MIN, and MAX.
Q34. What is the HAVING clause?
HAVING is used to filter grouped results after GROUP BY has been applied. It is different from WHERE, which filters rows before grouping.
Q35. What is an index in a database?
An index is a data structure that improves the speed of data retrieval operations on a table. It works like an index in a book, helping the database find rows faster.
Q36. What are the drawbacks of indexes?
Indexes improve read performance but consume extra storage and slow down write operations such as inserts, updates, and deletes. Too many indexes can hurt overall database performance.
Q37. What is a transaction in a database?
A transaction is a sequence of database operations treated as a single unit of work. Either all operations succeed together, or all of them are rolled back.
Q38. What does ACID stand for?
ACID stands for Atomicity, Consistency, Isolation, and Durability. These properties ensure transactions are reliable even in cases of errors, crashes, or concurrent access.
Q39. What is connection pooling?
Connection pooling is the practice of reusing a set of database connections instead of creating a new connection for every request. It improves performance and reduces the overhead of repeatedly opening and closing connections.
Q40. How do you optimize database performance in a backend application?
Database performance is optimized by writing efficient queries, using proper indexes, avoiding unnecessary joins, reducing N+1 query problems, paginating large datasets, reusing connections through pooling, and caching frequently accessed data when appropriate.
Part 8: DevOps, Deployment & System Design — 40 Interview Questions & Answers
Q1. What is DevOps?
DevOps is a set of practices and a culture that brings development and operations teams closer together. Its goal is to deliver software faster, more reliably, and with better collaboration through automation and continuous feedback.
Q2. What is CI/CD?
CI/CD stands for Continuous Integration and Continuous Delivery/Deployment. Continuous Integration focuses on regularly merging code changes and testing them automatically, while Continuous Delivery or Deployment focuses on releasing software quickly and safely.
Q3. What is the difference between Continuous Delivery and Continuous Deployment?
Continuous Delivery means code is always in a deployable state, but a human usually approves the final release. Continuous Deployment goes one step further and releases changes automatically to production once all checks pass.
Q4. What is Git and why is it important in DevOps?
Git is a distributed version control system used to track code changes and collaborate with other developers. In DevOps, it plays a central role because code, infrastructure, and pipeline configurations are all commonly stored and managed through Git.
Q5. What is the difference between git merge and git rebase?
git merge combines histories and creates a merge commit, preserving the branch history. git rebase rewrites commit history by placing one branch’s commits on top of another, creating a cleaner but less explicit history.
Q6. What is a pull request?
A pull request is a process used to review and discuss code before merging it into a shared branch. It helps teams maintain code quality through collaboration, comments, and approval workflows.
Q7. What is Docker?
Docker is a platform used to package applications and their dependencies into lightweight, portable containers. This helps ensure that the application runs the same way across development, testing, and production environments.
Q8. What is a container?
A container is a lightweight, isolated unit that includes an application and everything it needs to run. It shares the host operating system kernel but keeps processes and dependencies separated from other containers.
Q9. What is the difference between a container and a virtual machine?
A virtual machine includes a full guest operating system and uses more resources. A container is lighter because it shares the host OS kernel, which makes it faster to start and more efficient for deployment.
Q10. What is a Docker image?
A Docker image is a read-only blueprint used to create containers. It contains the application code, dependencies, environment settings, and startup instructions needed to run the app.
Q11. What is a Dockerfile?
A Dockerfile is a text file that defines how to build a Docker image. It contains step-by-step instructions such as choosing a base image, copying files, installing dependencies, and defining the startup command.
Q12. What is Docker Compose?
Docker Compose is a tool used to define and run multi-container applications. It is commonly used in full stack projects to start services like the backend, frontend, database, and Redis together.
Q13. Why is Docker useful in full stack development?
Docker makes environments consistent across machines and reduces “it works on my machine” problems. It also simplifies local development, testing, deployment, and onboarding for teams.
Q14. What is NGINX?
NGINX is a high-performance web server and reverse proxy. It is commonly used to serve static files, forward requests to backend application servers, and improve performance and security.
Q15. What is a reverse proxy?
A reverse proxy sits in front of one or more backend servers and forwards client requests to them. It is used for load balancing, SSL termination, caching, security, and hiding internal server details.
Q16. What is Gunicorn?
Gunicorn is a Python WSGI HTTP server used to run Python web applications such as Django and Flask in production. It manages worker processes that handle incoming requests.
Q17. What is the difference between Gunicorn and Uvicorn?
Gunicorn is commonly used for WSGI-based synchronous Python apps. Uvicorn is an ASGI server used for asynchronous applications such as FastAPI and async Django setups.
Q18. What is the difference between WSGI and ASGI?
WSGI is the standard interface for synchronous Python web applications. ASGI is the newer interface that supports asynchronous features such as WebSockets, long-lived connections, and async request handling.
Q19. What are environment variables and why are they used?
Environment variables are external configuration values used by an application at runtime. They are commonly used for secrets, API keys, database URLs, and environment-specific settings so that sensitive or changing values are not hardcoded.
Q20. What is a .env file?
A .env file is a file that stores environment variables in a simple key-value format. It is often used in local development but should be handled carefully and usually not committed to public repositories if it contains secrets.
Q21. What is GitHub Actions?
GitHub Actions is a CI/CD automation tool built into GitHub. It allows teams to automate workflows such as testing, building, linting, and deploying applications whenever code changes are pushed.
Q22. What is a CI/CD pipeline?
A CI/CD pipeline is an automated sequence of steps that takes code from commit to testing and deployment. It reduces manual work and helps ensure that changes are consistently validated before release.
Q23. What is cloud deployment?
Cloud deployment is the process of hosting applications on cloud platforms such as AWS, Azure, or GCP instead of running them only on local or on-premise machines. It provides scalability, availability, and managed infrastructure services.
Q24. What is AWS EC2?
AWS EC2 is a cloud service that provides virtual servers for running applications. Developers use it to host backend services, deploy Docker containers, and manage web servers in the cloud.
Q25. What is AWS S3?
AWS S3 is an object storage service used to store files such as images, videos, backups, static assets, and documents. It is commonly used in web applications for scalable file storage.
Q26. What is AWS RDS?
AWS RDS is a managed relational database service that supports engines like PostgreSQL and MySQL. It simplifies tasks such as backups, updates, scaling, and maintenance compared to self-managed databases.
Q27. What is load balancing?
Load balancing is the process of distributing incoming traffic across multiple servers so that no single server becomes overloaded. It improves performance, fault tolerance, and availability.
Q28. What is horizontal scaling vs vertical scaling?
Vertical scaling means increasing the resources of a single server, such as CPU or RAM. Horizontal scaling means adding more servers to handle increased load.
Q29. What is caching in system design?
Caching stores frequently accessed data closer to the application or user so it can be retrieved faster. It reduces repeated database or service calls and improves response time.
Q30. What is Redis commonly used for in system design?
Redis is commonly used for caching, session storage, rate limiting, pub/sub messaging, and as a message broker for background job systems. It is popular because it is fast and in-memory.
Q31. What is a message queue?
A message queue is a system that allows services to communicate asynchronously by sending messages through a queue. It helps decouple systems and is useful for background jobs, notifications, and event-driven workflows.
Q32. Why are message queues useful?
Message queues improve scalability and reliability by allowing slow or heavy tasks to run separately from the main user request. They also help systems recover more gracefully under load.
Q33. What is a monolith?
A monolith is an application where all major features and components are part of a single codebase and deployment unit. It is often easier to start with but can become harder to scale and maintain as complexity grows.
Q34. What are microservices?
Microservices are an architectural style where an application is split into smaller, independently deployable services. Each service handles a specific business capability and can be developed, deployed, and scaled separately.
Q35. What is the difference between monolith and microservices?
A monolith is simpler to develop and deploy initially because everything is in one place. Microservices provide better flexibility and scaling for large systems, but they introduce more operational complexity, networking concerns, and coordination challenges.
Q36. What is system design in interviews?
System design in interviews is the process of explaining how to build a scalable, reliable, and maintainable software system. Interviewers look for clear thinking around architecture, trade-offs, scalability, databases, caching, and reliability.
Q37. How would you approach a system design interview?
Start by clarifying requirements, scale, and constraints. Then identify core components, data flow, database choice, API design, scaling strategy, caching, background processing, and trade-offs before discussing bottlenecks and improvements.
Q38. What are common system design problems asked in interviews?
Common problems include designing a URL shortener, chat application, notification system, file upload service, e-commerce backend, rate limiter, social feed, or blog platform. The goal is not only correctness but also reasoning about trade-offs.
Q39. What is high availability?
High availability means designing a system so it remains operational even when some components fail. This is achieved using redundancy, load balancing, failover strategies, health checks, and resilient infrastructure.
Q40. How do you make a full stack application production-ready?
A production-ready application should use version control, automated testing, CI/CD, environment-based configuration, secure secret management, containerization, reverse proxying, proper logging, monitoring, caching where appropriate, database optimization, and scalable deployment architecture.
Part 9: Behavioral, Communication & Career Strategy — Complete Interview Guide
The STAR Method: Your Framework for Every Behavioral Question
The STAR method is the most reliable way to answer behavioral interview questions in software roles because it keeps answers structured, relevant, and measurable. STAR stands for Situation, Task, Action, Result, and interviewers use it to understand not just what happened, but how you think and work under pressure.
Use this structure for every story you prepare:
- S — Situation: Briefly explain the background, project, company context, and challenge.
- T — Task: Describe your exact responsibility, not just the team’s overall goal.
- A — Action: Explain what you specifically did, step by step; this should be the longest part.
- R — Result: End with the outcome, ideally with numbers such as faster response time, reduced bugs, faster delivery, or higher reliability.
A strong STAR answer is usually 60 to 120 seconds long and focuses more on your actions than on setup. Well-prepared candidates often reuse 8 to 10 versatile stories across many behavioral questions by slightly changing the framing.
20 Behavioral Questions with STAR Answer Frameworks
Q1. Tell me about yourself.
This is usually the opening question, and a strong answer should cover your current role or background, your main Python full stack skills, one or two notable projects, and why this role is the logical next step for you. Keep it concise, professional, and under 90 seconds.
Q2. Tell me about a time you worked on a project with a tight deadline.
STAR Framework:
- S: A sprint, release, client delivery, or urgent production change with limited time
- T: Your responsibility in delivering backend, frontend, or integration work on time
- A: How you prioritized tasks, broke work into smaller units, communicated trade-offs, and avoided gold-plating
- R: The feature shipped on time, a client deadline was met, or production impact was reduced
Q3. Describe a time you fixed a bug that was difficult to diagnose.
STAR Framework:
- S: A bug affecting users, production, or a critical internal system
- T: Your job was to identify the cause and restore stability
- A: How you reproduced the issue, checked logs, isolated components, tested assumptions, and validated the fix
- R: Downtime was reduced, the issue was permanently fixed, and you improved debugging or monitoring afterward
Q4. Tell me about a time you disagreed with a teammate.
STAR Framework:
- S: A disagreement over architecture, code style, framework choice, deadline, or implementation approach
- T: You needed to handle the conflict professionally without slowing the team down
- A: How you listened, used evidence, compared options, and focused on the best outcome instead of being “right”
- R: A better decision was made, a compromise was reached, or the team aligned more clearly
Q5. Describe a time you had to learn a new technology quickly.
STAR Framework:
- S: You were assigned something involving React, FastAPI, Docker, AWS, or another unfamiliar tool
- T: You needed to become productive fast enough to support the project
- A: How you used docs, tutorials, prototypes, pair programming, or internal guidance to ramp up
- R: You delivered the feature successfully and became confident enough to use the technology going forward
Q6. Tell me about a time your code caused a problem.
STAR Framework:
- S: A deployment issue, regression, broken feature, or production incident related to your change
- T: You needed to take responsibility and fix the issue quickly
- A: How you acknowledged the mistake, investigated the root cause, rolled back or patched the issue, and updated your process
- R: The system recovered, users were protected, and you improved testing or review practices
Q7. Describe a time you improved application performance.
STAR Framework:
- S: A slow API, heavy frontend rendering, poor database query performance, or server bottleneck
- T: Your job was to make the system faster without breaking functionality
- A: How you profiled the issue, optimized queries, added caching, reduced bundle size, or improved API response flow
- R: Response time improved, infrastructure cost dropped, or user experience became smoother
Q8. Tell me about your most impactful full stack project.
STAR Framework:
- S: What product or business problem the project addressed
- T: Your role across backend, frontend, API design, or deployment
- A: How you designed the solution, built the features, integrated the stack, tested it, and launched it
- R: Mention clear impact such as user growth, saved time, reduced manual work, or improved stability
Q9. Describe a time you dealt with unclear requirements.
STAR Framework:
- S: A project where stakeholders were vague or requirements kept changing
- T: You had to move forward without waiting for perfect clarity
- A: How you asked clarifying questions, documented assumptions, proposed an MVP, and validated your direction early
- R: The team aligned faster and the project moved forward with fewer misunderstandings
Q10. Tell me about a time you worked with a non-technical stakeholder.
STAR Framework:
- S: A product manager, founder, operations lead, client, or support team needed your help
- T: You had to explain technical limitations or gather requirements clearly
- A: How you translated technical details into business language, asked the right questions, and set expectations
- R: Better decisions were made and communication became smoother
Q11. Tell me about a time you had to prioritize multiple tasks.
STAR Framework:
- S: You had several bugs, features, meetings, or deployment tasks happening at once
- T: You needed to decide what to do first without dropping important work
- A: How you weighed business impact, urgency, dependencies, and communicated realistic timelines
- R: Critical items were delivered first and stakeholders stayed informed
Q12. Describe a time you received critical feedback.
STAR Framework:
- S: Feedback on code quality, communication, deadlines, ownership, or collaboration
- T: You needed to respond professionally and improve
- A: How you listened without becoming defensive, clarified the feedback, and changed your behavior or process
- R: Your work improved measurably and the feedback made you stronger
Q13. Tell me about a time you went beyond your assigned role.
STAR Framework:
- S: A situation where the team needed help beyond your normal responsibilities
- T: You stepped in to support design, documentation, testing, deployment, or mentoring
- A: Explain what you did proactively and why it mattered
- R: The project moved faster, the team avoided risk, or stakeholders benefited
Q14. Describe a time you handled a production issue.
STAR Framework:
- S: A real outage, broken API, server issue, deployment failure, or data-related incident
- T: You had to restore service and reduce damage
- A: How you diagnosed the incident, coordinated with others, communicated updates, and stabilized the system
- R: Service was restored and you put preventive steps in place such as monitoring, alerts, or rollback procedures
Q15. Tell me about a time you improved team productivity.
STAR Framework:
- S: A repeated pain point like manual deployment, unclear handoff, duplicated work, or inconsistent environments
- T: You wanted to make the team’s process faster or more reliable
- A: How you introduced automation, documentation, templates, reusable components, or CI/CD improvements
- R: The team saved time, reduced bugs, or shipped more consistently
Q16. Why do you want to work at this company?
A strong answer should mention a specific product, problem space, engineering culture, or stack that genuinely interests you. Avoid generic answers like “I want to grow” and instead show that you understand why this particular company is a good fit.
Q17. What is your greatest strength as a full stack developer?
Pick one real strength such as end-to-end ownership, debugging ability, clean API design, frontend-backend integration, or fast learning. Then support it with one brief example that proves it.
Q18. What is your greatest weakness?
Choose a real but non-fatal weakness and explain how you are actively improving it. Good answers show self-awareness and concrete action rather than fake strengths disguised as weaknesses.
Q19. Where do you see yourself in 3 years?
A good answer should sound ambitious but grounded. It should show growth in technical depth, ownership, system design ability, or product thinking, while still aligning with the role you are applying for.
Q20. Do you have any questions for us?
Always say yes. Strong questions include: what the first 90 days look like, how the team handles code reviews and deployment, what the current scaling challenges are, how backend and frontend teams collaborate, and what success looks like in the role.
40 ChatGPT / AI Self-Preparation Prompts (2026 Edition)
Use these prompts with ChatGPT, Claude, Gemini, or any strong AI tool to practice more efficiently.
Technical Practice Prompts (1–15)
- “Ask me 10 Python full stack interview questions one by one and evaluate my answers.”
- “Give me 5 Django ORM interview questions with concise model answers.”
- “Quiz me on Flask and FastAPI differences like a backend interviewer.”
- “Ask me JavaScript interview questions focused on closures, event loop, and async/await.”
- “Test me on React hooks one question at a time and tell me what I missed.”
- “Give me 10 SQL interview questions for backend developers with increasing difficulty.”
- “Act like a hiring manager and ask me REST API design questions.”
- “Ask me Docker and deployment interview questions for a Python full stack role.”
- “Give me one system design problem for a mid-level full stack engineer and critique my answer.”
- “Ask me debugging-based interview questions related to Django, React, and production issues.”
- “Test my understanding of JWT, OAuth, sessions, and authentication flows.”
- “Ask me frontend performance optimization questions for React applications.”
- “Give me scenario-based database optimization questions for PostgreSQL.”
- “Interview me on full stack architecture trade-offs, one question at a time.”
- “Ask me 5 production incident questions and grade my troubleshooting approach.”
Behavioral Practice Prompts (16–28)
- “Ask me behavioral interview questions using the STAR format for software engineers.”
- “I will paste my answer to ‘Tell me about yourself’; improve it for a Python full stack interview.”
- “Help me prepare 8 STAR stories from my project experience.”
- “Give feedback on my answer to ‘Tell me about a time you handled a difficult bug.'”
- “Role-play a full behavioral round for a full stack developer role.”
- “Ask me a conflict-resolution interview question and critique my answer.”
- “Help me make my project story more quantified and impactful.”
- “Tell me if my answer uses too much ‘we’ and not enough ‘I’.”
- “Help me answer ‘Why do you want to work here?’ for a product company.”
- “Give me 10 tricky behavioral questions software companies ask in 2026.”
- “Help me create a strong answer for ‘Tell me about a failure.'”
- “Review my answer to ‘What is your greatest weakness?’ and make it sound honest.”
- “Ask me manager-round questions for a full stack role.”
Career Strategy Prompts (29–40)
- “Rewrite this resume bullet point to sound stronger and more measurable: [paste bullet]”
- “Create a one-line LinkedIn headline for a Python full stack developer.”
- “Help me write a strong About section for LinkedIn as a fresher full stack developer.”
- “Review my GitHub project description and make it recruiter-friendly.”
- “Give me a cold outreach message to send to a software engineer on LinkedIn.”
- “Write a post-interview thank-you email for a Python full stack role.”
- “Help me tailor my resume for a Django + React developer job.”
- “What project ideas will impress recruiters hiring Python full stack developers in 2026?”
- “Help me compare two job offers beyond just salary.”
- “Create a salary negotiation message for a software developer role in India.”
- “Review my portfolio project and tell me what recruiters will like or dislike.”
- “Give me a 30-day mock interview plan for Python full stack preparation.”
Resume Optimization for Python Full Stack Developers in 2026
The 6 Resume Sections That Matter
- Headline / Title
Use a clear role title such as Python Full Stack Developer | Django | React | REST APIs | PostgreSQL. Avoid vague phrases like “software enthusiast” or “looking for opportunities.” - Professional Summary
Keep it under three lines. Mention your experience level, core stack, and one proof point such as a project delivered, API performance improvement, or deployment experience. - Skills Section
Group skills by category for easier scanning:
- Languages: Python, JavaScript, SQL
- Backend: Django, DRF, Flask, FastAPI
- Frontend: HTML, CSS, JavaScript, React
- Database: PostgreSQL, MySQL, MongoDB, Redis
- Tools: Git, Docker, GitHub Actions, Postman
- Cloud/Deployment: AWS, NGINX, Gunicorn, Linux
- Experience / Projects
Each bullet should follow this structure: Action + tool/technology + scope + result.
Example: “Built and deployed a Django + React inventory dashboard used by 5 internal teams, reducing manual reporting time by 60%.” - Education
Include degree, college, graduation year, and relevant certifications if useful. If you are a fresher, relevant coursework or strong academic achievements can also help. - Projects
Freshers should treat projects like experience. Include stack used, what problem the project solved, and one measurable or practical outcome.
ATS Keywords to Include in 2026
Django, Flask, FastAPI, REST API, React, JavaScript, PostgreSQL, SQL, Docker, Git, CI/CD, AWS, HTML, CSS, Authentication, JWT, Redis, Deployment, API Integration, System Design, Debugging.
Join the Python Full Stack Course →
LinkedIn Profile Optimization
Headline:
Use something specific like:
Python Full Stack Developer | Django · React · REST APIs · PostgreSQL · Docker
About Section:
Write in first person, keep it practical, and mention what you build, the technologies you use, and what kind of roles you are targeting. Avoid generic motivational lines.
Featured Section:
Pin your best GitHub project, live deployed app, resume, or technical post. Recruiters often check this quickly to judge whether your profile has proof behind it.
Experience & Projects:
Use the same impact-focused bullets as your resume. Numbers, technologies, and outcomes make a big difference.
Activity:
Post about what you build, what you learned, or deployment and debugging lessons from real projects. Consistent activity helps recruiters and hiring managers notice you.
GitHub Portfolio Strategy
A strong GitHub profile is better than a large one. Three to five polished repositories are far more valuable than twenty unfinished ones.
Every good project README should include:
- Problem statement
- Tech stack
- Features
- Project structure
- Setup instructions
- Screenshots or demo link
- Future improvements
Project ideas that impress in 2026:
- Django + React full stack CRUD application with authentication
- FastAPI backend with JWT, PostgreSQL, and Docker deployment
- E-commerce or booking app with admin dashboard
- Real-time notification or chat feature using WebSockets
- CI/CD-enabled deployment project using Docker and GitHub Actions
What to avoid:
- Incomplete repositories
- No README or poor documentation
- Projects with copied tutorials and no customization
- Very basic clone projects with no original feature or deployment
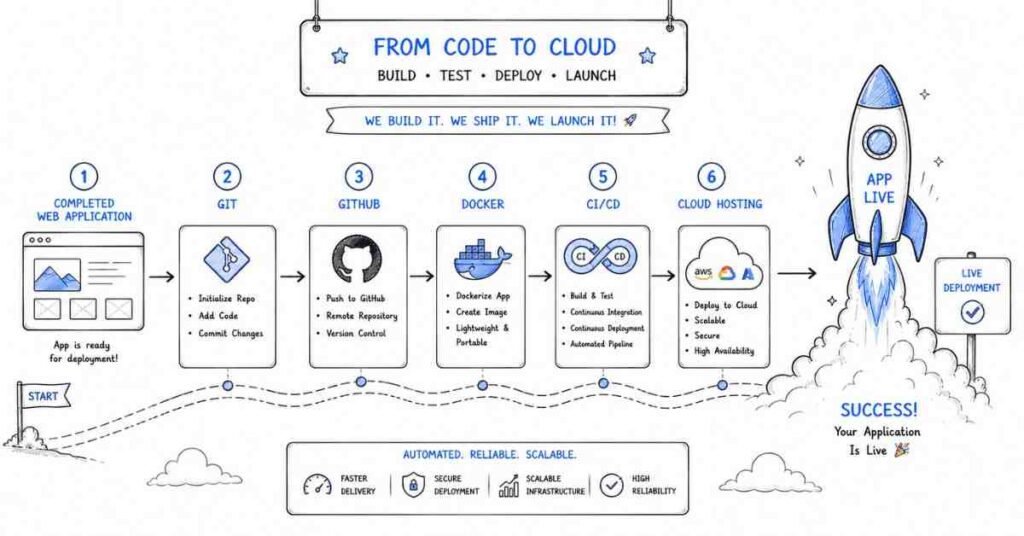
Salary Negotiation in 2026
Salary data for full stack roles in India varies widely by city, company type, and experience, but reported figures show a broad spread from entry-level packages in the low single-digit lakhs to significantly higher compensation in stronger markets and companies. Reported averages and examples on major salary platforms show that generic full stack and Python full stack compensation can range substantially depending on experience and employer, so candidates should benchmark against role, city, and stack rather than relying on one single number.
Practical range to discuss in interviews:
- Fresher / 0–1 year: roughly ₹3.5–6 LPA
- 1–3 years: roughly ₹6–12 LPA
- Strong product companies / top offers: can go meaningfully higher depending on stack depth, React + Django strength, deployment experience, and interview performance
Negotiation script:
“Thank you for the offer — I’m genuinely excited about the role. Based on my skills in Python full stack development, including Django, React, APIs, and deployment, I was expecting something closer to [target number]. Is there flexibility on the compensation?”
Also negotiate beyond base salary:
- Joining bonus
- Remote or hybrid flexibility
- Learning budget
- Early appraisal cycle
- Equipment reimbursement
- Variable pay structure
Explore Python Full Stack Career Path→
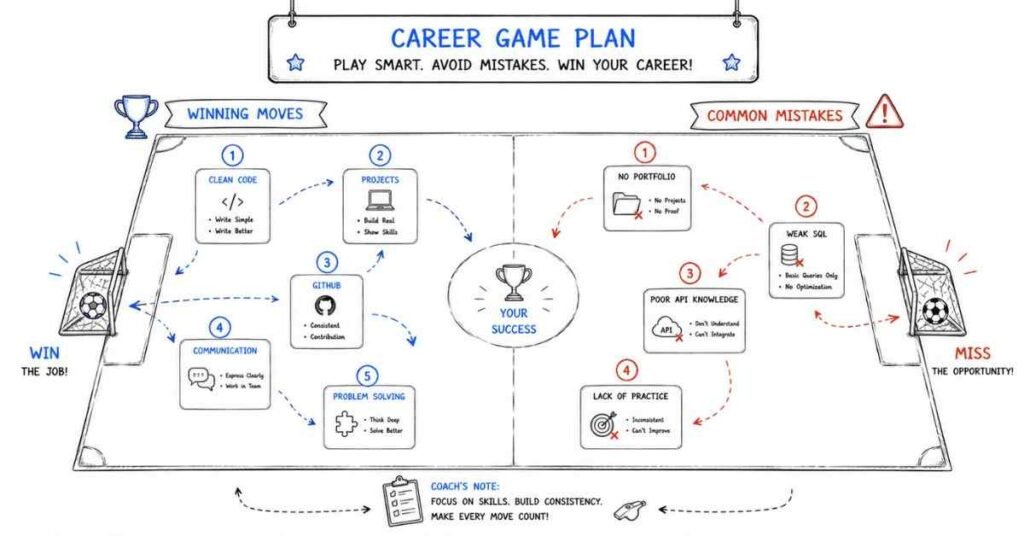
Post-Interview Follow-Up Templates
Thank You Email:
Subject: Thank You — Python Full Stack Developer Interview
Hi [Interviewer Name],
Thank you for taking the time to speak with me today about the Python Full Stack Developer role. I enjoyed our discussion, especially around [specific topic discussed].
The conversation increased my interest in the role, particularly because of the opportunity to work on [specific team challenge, product, or tech stack]. I believe my experience with [relevant skill] would allow me to contribute effectively.
Thank you again for your time and consideration.
Best regards,
[Your Name]
Follow-Up Email After 5–7 Business Days:
Subject: Following Up — Python Full Stack Developer Interview
Hi [Recruiter/Interviewer Name],
I hope you are doing well. I wanted to follow up regarding my interview for the Python Full Stack Developer role. I remain very interested in the opportunity and wanted to check if there are any updates on the hiring timeline.
Thank you for your time.
Best regards,
[Your Name]
Your 30-Day Final Checklist Before Interview Day
Technical readiness:
- ☐ Completed all 9 parts of this guide
- ☐ Practiced Python, Django, React, SQL, and REST API questions
- ☐ Reviewed Docker, deployment, and basic system design
- ☐ Can explain your project architecture clearly
- ☐ Can describe authentication, database design, and API flow confidently
Behavioral readiness:
- ☐ Prepared 8–10 STAR stories
- ☐ Practiced “Tell me about yourself”
- ☐ Prepared answers for conflict, failure, deadlines, and unclear requirements
- ☐ Prepared 3 thoughtful questions for the interviewer
Career readiness:
- ☐ Resume tailored for the target role
- ☐ LinkedIn updated
- ☐ GitHub profile cleaned up
- ☐ Strong README on your best project
- ☐ Salary expectation and negotiation number prepared
Day-before readiness:
- ☐ Interview time and format confirmed
- ☐ Internet, camera, mic, and IDE tested
- ☐ Resume and portfolio links ready
- ☐ Company research completed
- ☐ Slept well and avoided last-minute panic revision