Python Full Stack Developer Interview Preparation Guide
This guide provides a Python Interview Questions & comprehensive framework for both fresh graduates and experienced professionals to excel in Python Full Stack Developer interviews. The material is structured for step-by-step progression through all critical interview preparation aspects.

🎓 Want to master Python beyond interview questions?
Learn hands-on projects, REST APIs, and deployment in our Python Full Stack Developer Course in Telugu.
1.Technical Interview Questions & Answers
345+ questions and answers across the following domains:
- Core Python Programming (50 questions): Fundamentals, data types, functions, decorators, generators, exception handling
- Object-Oriented Programming (25 questions): Classes, inheritance, polymorphism, encapsulation, special methods
- Frontend Technologies (50 questions): HTML, CSS, JavaScript, React including hooks, lifecycle, state management
- Backend Frameworks – Flask (35 questions): Routing, templates, extensions, RESTful APIs, authentication
- Backend Frameworks – Django (25 questions): MVT architecture, ORM, migrations, admin panel, authentication
- RESTful API Design (25 questions): HTTP methods, status codes, authentication, versioning, documentation
- Database Management – SQL (30 questions): Queries, joins, normalization, transactions, optimization
- Database Management – NoSQL/MongoDB (25 questions): Documents, collections, aggregation, sharding, replication
- System Design (25 questions): Scalability, caching, load balancing, microservices, CAP theorem
- Testing & Quality Assurance (15 questions): Unit testing, integration testing, automation, pytest, Selenium
- Version Control – Git (15 questions): Repositories, commits, branching, merging, workflows
- Containerization – Docker (15 questions): Containers, images, Dockerfile, Docker Compose, orchestration
- Best Practices (10 questions): Code reviews, security, performance, CI/CD, SOLID principlesThis guide prepares candidates for both technical interviews and practical scenario-based questions, suitable for freshers and experienced professionals targeting Python Full Stack Developer roles.
Part 1: Core Python Programming (50 Questions)
Python Fundamentals
- What are the key differences between Python 2 and Python 3?
Python 3 brought significant improvements including print() as a function instead of statement, modified integer division behaviour where / returns float and // returns integer, Unicode string handling by default, and enhanced syntax features like f-strings for formatting. Python 3 also eliminated implicit type conversions and improved exception handling syntax.
- What are Python’s built-in data types?
Python provides numeric types (int, float, complex), sequence types (str, list, tuple, range), mapping type (dict), set types (set, frozenset), and boolean type (bool). Lists are mutable ordered collections, tuples are immutable ordered collections, dictionaries store key-value pairs, and sets contain unique unordered elements.
- What is the difference between mutable and immutable objects?
Mutable objects like lists, dictionaries, and sets can be modified after creation without changing their memory address. Immutable objects like integers, strings, tuples, and frozen sets cannot be changed once created; any modification creates a new object. Understanding mutability is crucial for avoiding unintended side effects in functions.
- How does Python handle exceptions?
Exception handling uses try-except blocks to catch and manage errors gracefully. The structure includes a try block for code that might raise exceptions, except blocks for handling specific exception types, an optional else block that executes when no exception occurs, and a finally block for clean up operations that always execute.
- What is the difference between is and == operators?
The == operator compares values for equality performing type conversion if needed, while is checks if two references point to the same object in memory. For example, ‘5’ == 5 returns False but two variables pointing to the same list object will return True with is.
- What are decorators in Python?
Decorators are functions that modify the behaviour of other functions or methods without permanently altering their structure. They use the @decorator_name syntax placed above function definitions and are commonly used for logging, authentication, timing, and caching operations. Decorators accept a function as an argument, add functionality, and return a modified function.
- What are generators and how do they differ from regular functions?
Generators are special functions that use the yield keyword instead of return to produce a sequence of values lazily, one at a time. They maintain state between calls, consume minimal memory since values are generated on-demand rather than stored, and automatically implement iterator protocol. Generators are ideal for processing large datasets or infinite sequences.
- What is the difference between deep copy and shallow copy?
Shallow copy creates a new object but references the original nested objects, while deep copy creates independent copies of all nested objects. Use the copy module’s copy() function for shallow copying and deepcopy() for deep copying. Deep copying is essential when working with complex data structures to prevent unintended side effects.
- What are lambda functions?
Lambda functions are anonymous functions created using the lambda keyword that can accept multiple arguments but are limited to a single expression. They are commonly used with map(), filter(), reduce(), and sorted() functions. Example: lambda x: x * 2 creates a function that doubles its input.
- What is list comprehension?
List comprehension provides a concise way to create lists using the syntax [expression for item in iterable if condition]. Example: [x * 2 for x in range(5)] results in [^0][^2][^4][^6][^8]. List comprehensions are more readable and often faster than equivalent for-loops.
- Explain the difference between append() and extend() in lists.
The append() method adds one element to the end of a list as a single item, while extend() adds all elements from an iterable to the end of the list individually. For example, list.append([^1][^2]) adds [^1][^2] as one element, while list.extend([^1][^2]) adds 1 and 2 as separate elements.
- What is the difference between remove(), del, and pop() in lists?
remove() deletes the first occurrence of a specific value and raises Value Error if not found, del removes an element by index or slices and can delete entire variables, and pop() removes and returns an element at a given index (default last). All three modify the list in-place but serve different use cases.
- What are *args and **kwargs?
*args allows a function to accept any number of positional arguments as a tuple, while **kwargs allows any number of keyword arguments as a dictionary. They provide flexibility in function definitions: def func(*args, **kwargs) can accept any combination of arguments. Both are convention names; the asterisks are what matter.
- What is the purpose of __init__ method?
The __init__ method is Python’s constructor that initializes object attributes when a new instance is created. It receives self as the first parameter representing the instance and additional parameters for initialization values. This method runs automatically upon object instantiation and sets up the initial state.
- What is the difference between @staticmethod and @classmethod?
A @staticmethod doesn’t receive an implicit first argument and works like a regular function within the class namespace. A @classmethod receives the class cls as its first argument and can access/modify class state, often used for factory methods. Static methods can’t access instance or class attributes.
- What does the pass statement do?
The pass statement is a null operation placeholder used where syntax requires a statement but no action is needed. It’s commonly used in empty function definitions, class declarations, or conditional blocks during development. Pass allows syntactically correct code that can be filled in later.
- How does Python’s garbage collection work?
Python uses automatic memory management with reference counting and a cyclic garbage collector. Reference counting tracks how many references point to each object, deallocating memory when the count reaches zero. The garbage collector handles circular references that reference counting cannot resolve using generational collection.
- What is a namespace in Python?
A namespace is a container holding identifier names ensuring they’re unique within a certain scope. Python has local (function), enclosing (nested functions), global (module), and built-in namespaces following the LEGB rule. Namespaces prevent naming conflicts and determine variable visibility.
- What are Python’s comparison operators?
Comparison operators include == (equal), != (not equal), < (less than), > (greater than), <= (less than or equal), and >= (greater than or equal). They return boolean values and can be chained: x < y < z is equivalent to x < y and y < z. Python also supports membership (in, not in) and identity (is, is not) operators.
- What is the difference between break, continue, and pass?
break terminates the loop entirely and transfers control to the next statement, continue skips the current iteration and moves to the next loop iteration, while pass does nothing and is just a placeholder. These control flow statements are used in loops for different purposes.
- What are dictionary comprehensions?
Dictionary comprehensions create dictionaries using concise syntax: {key_expr: value_expr for item in iterable if condition}. Example: {x: x*x for x in range(5)} creates {0:0, 1:1, 2:4, 3:9, 4:16}. They’re more readable than loops for creating dictionaries.
- What is the global keyword?
The global keyword declares that a variable inside a function refers to a global variable in the module scope. Without global, assigning to a variable creates a new local variable. Example: global counter allows modifying the global counter variable inside a function.
- What is the nonlocal keyword?
The nonlocal keyword allows a nested function to modify variables from the enclosing (but not global) scope. It’s used in closures to maintain state: nonlocal count in an inner function modifies the outer function’s count variable. Without nonlocal, assignment creates a new local variable.
- What are Python’s logical operators?
Logical operators include and (returns True if both operands are True), or (returns True if either operand is True), and not (returns the opposite boolean value). They use short-circuit evaluation: and stops at the first False, or stops at the first True. These operators return actual values, not just True/False.
- What is the enumerate() function?
enumerate() adds a counter to an iterable, returning tuples of (index, value) pairs. It’s commonly used in loops: for i, value in enumerate(items) provides both index and value. You can specify a starting index: enumerate(items, start=1) begins counting from 1.
- What is the zip() function?
zip() combines multiple iterables element-wise, creating tuples of corresponding elements. It stops when the shortest iterable is exhausted: zip([^1][^2][^3], [‘a’,’b’]) returns [(1,’a’), (2,’b’)]. Use zip(*zipped) to unzip paired data.
- What are Python’s membership operators?
Membership operators in and not in check whether a value exists in a sequence (list, tuple, string, dictionary keys). They return boolean values: ‘a’ in ‘abc’ returns True. For dictionaries, membership tests check keys by default, not values.
- What is the map() function?
map() applies a function to every item in an iterable, returning a map object (iterator). Usage: map(function, iterable) or list(map(lambda x: x*2, [^1][^2][^3])) returns [^2][^4]. It’s memory-efficient for large datasets since it generates results lazily.
- What is the filter() function?
filter() constructs an iterator from elements of an iterable for which a function returns True. Usage: filter(function, iterable) or list(filter(lambda x: x>0, [-1,0,1,2])) returns [^1][^2]. It’s useful for selective data extraction without loops.
- What is the reduce() function?
reduce() from the functools module applies a function cumulatively to items of an iterable, reducing it to a single value. Usage: reduce(lambda x,y: x+y, [^1][^2][^3][^4]) returns 10 by computing ((1+2)+3)+4. It’s powerful for aggregation operations.
- What are sets and their operations?
Sets are unordered collections of unique elements supporting mathematical set operations. Operations include union() or |, intersection() or &, difference() or –, and symmetric_difference() or ^. Sets are useful for removing duplicates and membership testing with O(1) complexity.
- What is the difference between remove() and discard() in sets?
remove() deletes a specified element from a set and raises KeyError if the element doesn’t exist. discard() also removes an element but doesn’t raise an error if the element is absent. Use discard() when you’re unsure if the element exists.
- What are frozensets?
Frozensets are immutable versions of sets that can be used as dictionary keys or elements of other sets. Created using frozenset(iterable), they support all set operations except modification methods like add() or remove(). They’re hashable unlike regular sets.
- What is string formatting in Python?
String formatting includes old-style % formatting, str.format() method, and f-strings (formatted string literals). F-strings (Python 3.6+) offer the most readable syntax: f”Hello {name}, you are {age} years old”. They support expressions and formatting specifications.
- What are string methods split() and join()?
split() divides a string into a list based on a delimiter: “a,b,c”.split(‘,’) returns [‘a’,’b’,’c’]. join() combines list elements into a string with a separator: ‘,’.join([‘a’,’b’,’c’]) returns ‘a,b,c’. They’re inverses of each other.
- What is slicing in Python?
Slicing extracts portions of sequences using [start:stop:step] syntax. Examples: list[2:5] gets elements 2-4, list[::2] gets every second element, list[::-1] reverses the sequence. Negative indices count from the end: list[-3:] gets the last three elements.
- What are context managers and the with statement?
Context managers manage resources using __enter__() and __exit__() methods, ensuring proper setup and cleanup. The with statement simplifies resource management: with open(‘file.txt’) as f: automatically closes the file. You can create custom context managers using contextlib module.
- What is the try-except-else-finally block structure?
try contains code that might raise exceptions, except handles specific exceptions, else executes if no exception occurs, and finally always executes for cleanup regardless of exceptions. This structure provides comprehensive error handling and resource management. Multiple except blocks can handle different exception types.
- What are Python’s built-in exceptions?
Common exceptions include ValueError (invalid value), TypeError (wrong type), KeyError (missing dictionary key), IndexError (invalid index), FileNotFoundError (file doesn’t exist), ZeroDivisionError (division by zero), and AttributeError (invalid attribute). All exceptions inherit from BaseException.
- How do you create custom exceptions?
Create custom exceptions by inheriting from Exception class: class CustomError(Exception): pass. Add custom behavior by overriding __init__() and __str__() methods. Custom exceptions improve error clarity: raise CustomError(“Descriptive message”).
- What is the assert statement?
assert checks if a condition is True and raises AssertionError if False, useful for debugging. Syntax: assert condition, “error message”. Assertions can be disabled globally with Python’s -O optimization flag, so don’t use them for input validation.
- What are Python’s bitwise operators?
Bitwise operators include & (AND), | (OR), ^ (XOR), ~ (NOT), << (left shift), and >> (right shift). They operate on integer binary representations: 5 & 3 (101 & 011) returns 1 (001). Useful for low-level operations and optimization.
- What is the all() function?
all() returns True if all elements in an iterable are True (or if the iterable is empty). Usage: all([True, True, False]) returns False. It’s useful for validation: all(x > 0 for x in numbers) checks if all numbers are positive.
- What is the any() function?
any() returns True if at least one element in an iterable is True. Usage: any([False, False, True]) returns True. It short-circuits, stopping at the first True value for efficiency.
- What are Python’s identity operators?
Identity operators is and is not check if two variables reference the same object in memory. Unlike == which compares values, is compares memory addresses. Example: a is b checks if a and b point to the same object.
- What is the difference between range() and xrange()?
In Python 2, range() returns a list while xrange() returns an iterator, making xrange more memory-efficient. Python 3 only has range() which behaves like Python 2’s xrange, returning an iterator. This change improves memory efficiency in Python 3.
- What are Python modules and packages?
Modules are single Python files containing definitions and statements, while packages are directories containing multiple modules and an __init__.py file. Import modules using import module or from module import item. The __name__ variable helps determine if a module is run directly or imported.
- What is the __name__ variable?
__name__ is a built-in variable that equals “__main__” when a script is executed directly, or the module name when imported. The pattern if __name__ == “__main__”: ensures code runs only when executed directly, not when imported. This enables modules to be both imported and executable.
- What are Python’s ternary operators?
Python’s ternary operator uses the syntax value_if_true if condition else value_if_false. Example: max_val = a if a > b else b assigns the larger value. It provides a concise way to write simple if-else statements.
- What is the isinstance() function?
isinstance() checks if an object is an instance of a specified class or tuple of classes. Usage: isinstance(obj, (int, float)) returns True if obj is int or float. It’s preferred over type() because it respects inheritance.
Part 2: Object-Oriented Programming in Python (25 Questions)
- What is Object-Oriented Programming (OOP)?
OOP is a programming paradigm based on objects containing data (attributes) and code (methods). Python supports four pillars of OOP: encapsulation, inheritance, polymorphism, and abstraction. OOP promotes code reusability, modularity, and maintainability.
- What are classes and objects in Python?
A class is a blueprint defining attributes and methods, while an object is an instance of a class. Classes are defined using the class keyword: class MyClass: followed by methods and attributes. Objects are created by calling the class: obj = MyClass().
- What is encapsulation?
Encapsulation bundles data and methods within a class and restricts direct access to some components. Python uses naming conventions: public (no prefix), protected (single underscore _), and private (double underscore __). Encapsulation prevents external interference and misuse.
- What is inheritance in Python?
Inheritance allows classes to derive properties and methods from parent classes, promoting code reusability. Python supports single inheritance (one parent), multiple inheritance (multiple parents), and multilevel inheritance (chain). Child classes override parent methods using the same method name.
- What is the super() function?
super() provides access to methods of parent classes, commonly used in __init__() to call parent constructors. Syntax: super().__init__() in Python 3 or super(ChildClass, self).__init__() in Python 2. It handles method resolution order (MRO) in multiple inheritance.
- What is polymorphism?
Polymorphism allows objects of different classes to be treated through a common interface. Python implements polymorphism through method overriding (child class redefines parent method) and duck typing (if it walks like a duck…). Operator overloading is another form using special methods.
- What is abstraction?
Abstraction hides complex implementation details and shows only essential features. Python uses abstract base classes (ABC) from abc module with @abstractmethod decorator. Abstract classes cannot be instantiated and force child classes to implement abstract methods.
- What are special methods (magic methods) in Python?
Special methods are surrounded by double underscores (__method__) and provide built-in functionality. Examples include __init__ (constructor), __str__ (string representation), __len__ (length), __add__ (addition operator). They enable operator overloading and customize object behavior.
- What is the difference between __str__() and __repr__()?
__str__() returns a user-friendly string representation for end users, while __repr__() returns an unambiguous developer-focused representation. repr() should ideally allow recreating the object: eval(repr(obj)) == obj. __str__() is called by str() and print(), __repr__() by repr() and interactive interpreter.
- What is method overriding?
Method overriding occurs when a child class provides a specific implementation of a method already defined in its parent class. The child method must have the same name and parameters as the parent method. Use super() to call the parent method from the overridden child method.
- What is method overloading?
Python doesn’t support traditional method overloading (same name, different parameters) like Java. Instead, use default arguments or variable-length arguments (*args, **kwargs) to achieve similar functionality. The last defined method with the same name replaces previous definitions.
- What are class variables vs instance variables?
Class variables are shared among all instances and defined directly in the class body. Instance variables are unique to each instance and defined in __init__() using self. Class variables are accessed via the class name or self, while instance variables require self.
- What are class methods?
Class methods are defined using @classmethod decorator and receive the class (cls) as the first argument instead of instance (self). They can access and modify class state, useful for factory methods. Example: @classmethod def from_string(cls, string): creates instances from strings.
- What are static methods?
Static methods use @staticmethod decorator and don’t receive implicit first argument (self or cls). They belong to the class namespace but can’t access instance or class state. Use them for utility functions related to the class but not requiring access to class/instance data.
- What is multiple inheritance?
Multiple inheritance allows a class to inherit from multiple parent classes: class Child(Parent1, Parent2):. Python uses C3 linearization for Method Resolution Order (MRO) to determine which parent method is called. Check MRO with ClassName.__mro__ or ClassName.mro().
- What is the Method Resolution Order (MRO)?
MRO defines the order in which Python searches for methods in a class hierarchy, especially important with multiple inheritance. Python 3 uses C3 linearization algorithm ensuring a consistent, predictable order. View MRO with Class.__mro__ or Class.mro() method.
- What are property decorators?
Property decorators (@property) convert methods into managed attributes, providing getter, setter, and deleter functionality. They enable attribute access control while maintaining simple dot notation: obj.attribute instead of obj.get_attribute(). Use @attribute.setter and @attribute.deleter for setting and deleting.
- What is the __new__() method?
__new__() is responsible for creating a new instance of a class before initialization. It’s a static method receiving the class as first argument and returns the new instance. __new__() is called before __init__() and is often overridden when subclassing immutable types.
- What is the __del__() method?
__del__() is a destructor method called when an object is about to be destroyed. It’s used for cleanup operations like closing files or network connections. However, relying on __del__() is discouraged; use context managers instead.
- What are descriptors in Python?
Descriptors are objects defining __get__(), __set__(), and/or __delete__() methods that control attribute access. They implement the descriptor protocol used by properties, methods, static methods, and class methods. Descriptors enable fine-grained control over attribute behaviour.
- What is the __call__() method?
__call__() makes an instance callable like a function. When defined, obj() executes obj.__call__(). Useful for creating function-like objects with state, like decorators or callbacks.
- What are slots in Python?
__slots__ is a class attribute that restricts instance attributes to a fixed set, reducing memory overhead. Defined as __slots__ = [‘attr1’, ‘attr2’], it prevents dynamic attribute creation. Slots improve performance for classes with many instances but sacrifice flexibility.
- What is composition in Python?
Composition is a design pattern where a class contains instances of other classes as attributes rather than inheriting from them. It follows the “has-a” relationship versus inheritance’s “is-a” relationship. Composition is often preferred over inheritance for better flexibility and loose coupling.
- What are metaclasses?
Metaclasses are classes whose instances are classes themselves, controlling class creation behavior. The default metaclass is type, but custom metaclasses can enforce coding standards or modify class behavior. Define with class MyClass(metaclass=MyMetaClass):.
- What is duck typing?
Duck typing is a programming concept where an object’s suitability is determined by the presence of methods and properties rather than its type. The phrase “if it walks like a duck and quacks like a duck, it’s a duck” captures the essence. Python’s dynamic typing enables duck typing naturally.
Part 3: Frontend Technologies (50 Questions)
HTML
- What is HTML?
HTML (HyperText Markup Language) is the standard markup language for creating web pages, defining structure and content. HTML consists of elements represented by tags enclosed in angle brackets like <tag>. HTML5 is the latest version introducing semantic elements, multimedia support, and improved APIs.
- What is the difference between HTML and HTML5?
HTML5 supports audio and video without Flash using `<audio>` and `<video>` tags, adds local and session storage replacing cookies, allows JavaScript to run in background via Web Workers API. HTML5 includes native vector graphics (SVG, canvas), drag-and-drop functionality, and semantic elements like `<header>`, `<footer>`, `<article>`.[^7][^6]
- What is the <!DOCTYPE> declaration?
The <!DOCTYPE> declaration tells the browser which HTML version is used, ensuring proper rendering. For HTML5, use <!DOCTYPE html> (case-insensitive). It must be the first line before the <html> tag and is not an HTML element.
- What are semantic HTML elements?
Semantic elements clearly describe their meaning to both browser and developer, like `<header>`, `<nav>`, `<main>`, `<article>`, `<section>`, `<aside>`, `<footer>`. They improve SEO, accessibility, and code readability compared to generic `<div>` elements. Semantic HTML helps screen readers and search engines understand content structure.[^7][^6]
- What is the difference between block and inline elements?
Block elements take full width available and start on new lines (e.g., `<div>`, `<p>`, `<h1>-<h6>`, `<section>`). Inline elements take only necessary width and stay in the same line (e.g., `<span>`, `<a>`, `<strong>`, `<em>`). Block elements can contain inline elements but not vice versa.[^7][^6]
- What are HTML attributes?
Attributes provide additional information about elements using name-value pairs inside opening tags. Common attributes include id (unique identifier), class (grouping selector), href (link destination), src (resource location), alt (alternative text). Attributes customize element behavior and styling.
- What is the difference between id and class attributes?
id must be unique per page and is used to identify a specific element, written in CSS with #. class can be applied to multiple elements for grouping, written in CSS with .. IDs have higher CSS specificity than classes.
- What are meta tags?
Meta tags provide metadata about HTML documents in the `<head>` section, invisible to users. They define character set, viewport settings, description, keywords, and author information. Meta tags are crucial for SEO and responsive design: `<meta name=”viewport” content=”width=device-width, initial-scale=1.0″>`.[^6][^7]
- What is the difference between <div> and <span>?
`<div>` is a block-level element used for grouping larger content sections, while `<span>` is an inline element for styling small text portions. `<div>` accepts align attribute; `<span>` doesn’t. Use `<div>` for structural grouping and `<span>` for inline styling.[^7][^6]
- What are HTML forms?
Forms collect user input using the `<form>` element containing input elements like `<input>`, `<textarea>`, `<select>`, `<button>`. Forms have attributes like `action` (where to send data), `method` (GET or POST), and `enctype` (encoding type). Input types include text, password, email, number, date, checkbox, radio, file.[^6][^7]
CSS
- What is CSS?
CSS (Cascading Style Sheets) is a stylesheet language that describes presentation of HTML documents, controlling layout, colors, fonts, and spacing. CSS enables separation of content from presentation, making maintenance easier. CSS selectors target HTML elements to apply styles.
- How can CSS be added to HTML?
Three methods exist: inline CSS (style attribute in HTML tags), internal CSS (embedded in `<style>` tag in `<head>`), and external CSS (separate .css file linked via `<link>` tag). External CSS is preferred for reusability and maintainability. Inline CSS has highest priority, then internal, then external.[^6][^7]
- What is the CSS box model?
The box model describes how elements are rendered: content (actual content), padding (space around content), border (surrounds padding), and margin (space outside border). Total element width = content width + left padding + right padding + left border + right border + left margin + right margin. box-sizing: border-box includes padding and border in total width.
- What are CSS selectors?
Selectors target HTML elements for styling: element selector (p), class selector (.classname), ID selector (#idname), attribute selector ([type=”text”]), pseudo-class (:hover), pseudo-element (::before). Combinators include descendant (space), child (>), adjacent sibling (+), general sibling (~). Universal selector (*) targets all elements.
- What is CSS specificity?
Specificity determines which CSS rule applies when multiple rules target the same element. Calculation: inline styles (1000), IDs (100), classes/attributes/pseudo-classes (10), elements/pseudo-elements (1). Higher specificity wins; equal specificity uses the last declared rule.
JavaScript
- What is JavaScript?
JavaScript is a high-level, interpreted programming language for creating interactive web pages. It runs in browsers, manipulates DOM, handles events, and communicates with servers asynchronously. JavaScript is single-threaded with event loop for asynchronous operations.
- What is the difference between == and ===?
== compares values with type coercion (e.g., ‘5’ == 5 returns true), while === strictly compares both value and type without coercion (e.g., ‘5’ === 5 returns false). Always use === to avoid unexpected type conversions. == can lead to subtle bugs.
- What are JavaScript data types?
Primitive types: string, number, bigint, boolean, undefined, symbol, null. Reference type: object (including arrays, functions, dates). typeof operator checks types but typeof null returns “object” (known quirk).
- What is the difference between var, let, and const?
var has function scope, is hoisted, and can be redeclared. let has block scope, is hoisted but not initialized (temporal dead zone), cannot be redeclared in same scope. const has block scope, must be initialized at declaration, cannot be reassigned (but object properties can change).
- What is hoisting in JavaScript?
Hoisting moves variable and function declarations to the top of their scope before code execution. var variables are hoisted and initialized with undefined; let and const are hoisted but not initialized (temporal dead zone). Function declarations are fully hoisted; function expressions are not.
- What are arrow functions?
Arrow functions provide shorter syntax: (param) => expression or (param) => { statements }. They don’t have their own this binding (lexical this), cannot be used as constructors, and don’t have arguments object. Arrow functions are ideal for callbacks and array methods.
- What is the difference between null and undefined?
undefined means a variable has been declared but not assigned a value. null is an intentional assignment representing absence of value. typeof undefined returns “undefined”; typeof null returns “object” (legacy bug).
- What are JavaScript closures?
Closures are functions that have access to variables from their outer (enclosing) scope even after the outer function has returned. They enable data privacy and function factories. Example: inner functions accessing outer function variables.
- What is event bubbling and capturing?
Event bubbling propagates events from target element up to parent elements (innermost to outermost). Event capturing propagates from outermost to innermost element. Use addEventListener(event, handler, useCapture) where useCapture=true enables capturing phase.
- What is the event loop?
The event loop handles asynchronous operations in single-threaded JavaScript. It monitors call stack and callback queue, moving callbacks to stack when stack is empty. This enables non-blocking I/O despite JavaScript being single-threaded.
React
- What is React?
React is an open-source JavaScript library for building user interfaces, developed by Facebook. It uses component-based architecture, virtual DOM, and unidirectional data flow. React supports server-side rendering and is widely used for single-page applications.
- What is JSX?
JSX (JavaScript XML) allows writing HTML-like syntax inside JavaScript that gets transpiled to React.createElement() calls. It makes code more readable: `<div>Hello</div>` instead of `React.createElement(‘div’, {}, ‘Hello’)`. JSX supports expressions in curly braces: `{variable}`.[^9][^10][^8]
- What is the Virtual DOM?
Virtual DOM is a lightweight JavaScript representation of actual DOM maintained by React for optimization. When state changes, React creates new virtual DOM, compares with previous (diffing), and updates only changed elements in real DOM (reconciliation). This minimizes expensive DOM manipulations.
- What are React components?
Components are reusable, independent pieces of UI that can be functional (JavaScript functions) or class-based (ES6 classes). Components accept props and return React elements. Functional components with hooks are now preferred over class components.
- What is the difference between functional and class components?
Functional components are JavaScript functions returning JSX, simpler and use hooks for state/lifecycle. Class components are ES6 classes extending React.Component, use this.state and lifecycle methods like componentDidMount. Functional components are the modern standard.
- What are props in React?
Props (properties) are read-only inputs passed from parent to child components. They enable data flow and component reusability: <Child name=”John” />. Props are accessed via props.name in functional components or this.props.name in class components.
- What is state in React?
State is a built-in object storing component’s dynamic data that can change over time. State changes trigger re-renders. In functional components, use useState hook: const [count, setCount] = useState(0).
- What are React hooks?
Hooks are functions that enable functional components to use state and lifecycle features. Common hooks include useState (state management), useEffect (side effects), useContext (context), useRef (DOM access). Hooks must be called at the top level, not inside loops or conditions.
- What is the useState hook?
useState adds state to functional components, returning current state and updater function: const [state, setState] = useState(initialValue). Calling setState triggers re-render with new state. State updates may be asynchronous and batched.
- What is the useEffect hook?
useEffect performs side effects in functional components (data fetching, subscriptions, DOM manipulation). It runs after render: useEffect(() => { effect }, [dependencies]). Empty dependency array runs once on mount, no array runs after every render, dependencies trigger on their change.
- What are React lifecycle methods?
Lifecycle methods execute at specific stages: componentDidMount (after first render), componentDidUpdate (after updates), componentWillUnmount (before removal). Functional components use useEffect to replicate lifecycle behavior. Class components have more lifecycle methods but are less common now.
- What is React Router?
React Router is the standard library for client-side routing in single-page applications. It uses components like BrowserRouter, Route, Link, useNavigate to manage navigation without page reloads. Routes map URLs to components.
- What are controlled vs uncontrolled components?
Controlled components have form values controlled by React state via value and onChange props. Uncontrolled components store values in DOM accessed via refs. Controlled components provide better control and validation.
- What are React keys?
Keys are special attributes helping React identify which items changed, added, or removed in lists. Use unique, stable identifiers: `items.map(item => <li key={item.id}>{item.name}</li>)`. Never use array indices as keys if list can reorder.[^9][^10][^8]
- What is prop drilling?
Prop drilling passes data through multiple intermediate components that don’t need it to reach deeply nested children. Solutions include Context API, Redux, or component composition. Context API provides global state without drilling.
- What is React Context?
Context provides a way to share values between components without passing props through every level. Create with React.createContext(), provide with <Context.Provider value={}>, consume with useContext(Context). Use for global data like themes, user authentication.
- What are higher-order components (HOC)?
HOCs are functions that take a component and return a new enhanced component. They enable code reuse and logic abstraction: const EnhancedComponent = higherOrderComponent(WrappedComponent). Common use cases include authentication, logging, data fetching.
- What is React.memo()?
React.memo() is a higher-order component that memoizes functional components, preventing unnecessary re-renders when props haven’t changed. Usage: const MemoizedComponent = React.memo(Component). Useful for performance optimization of expensive render operations.
- What are React fragments?
Fragments let you group multiple elements without adding extra DOM nodes: <React.Fragment> or shorthand <>. Useful when returning multiple elements: <><div>A</div><div>B</div></>. Fragments can have keys when mapping: <Fragment key={id}>.
- What is error boundary in React?
Error boundaries are components catching JavaScript errors in child component tree, logging errors, and displaying fallback UI. Implement using static getDerivedStateFromError() and componentDidCatch() in class components. Error boundaries don’t catch errors in event handlers or async code.
- What is useRef hook?
useRef creates a mutable reference persisting across renders without causing re-renders. Common uses: accessing DOM elements (inputRef.current.focus()), storing mutable values. Unlike state, changing ref.current doesn’t trigger re-render.
- What is useCallback hook?
useCallback returns a memoized callback function, preventing recreation on every render: const memoizedCallback = useCallback(() => { doSomething(a, b) }, [a, b]). Useful for passing callbacks to optimized child components using React.memo. Dependencies determine when callback is recreated.
- What is useMemo hook?
useMemo memoizes expensive computed values, recomputing only when dependencies change: const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]). Improves performance by avoiding unnecessary calculations. Don’t overuse; premature optimization can harm readability.
- What is useReducer hook?
useReducer manages complex state logic using reducer pattern: const [state, dispatch] = useReducer(reducer, initialState). Reducers are pure functions: (state, action) => newState. Useful when state transitions depend on previous state or involve multiple sub-values.
- What is code splitting in React?
Code splitting breaks bundle into smaller chunks loaded on demand, improving initial load time. Use React.lazy() and Suspense: const Component = React.lazy(() => import(‘./Component’)). Wrap lazy components in <Suspense fallback={<Loading />}>.
Part 4: Backend Frameworks – Flask (35 Questions)
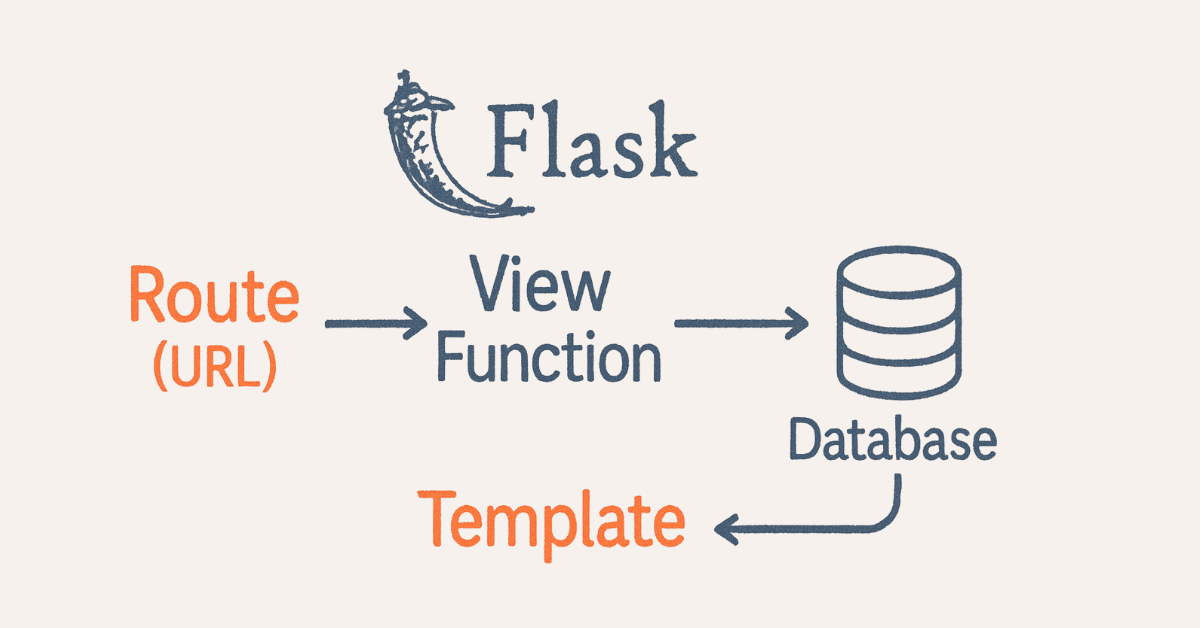
- What is Flask?
Flask is a lightweight Python microframework based on WSGI (Web Server Gateway Interface) toolkit and Jinja2 template engine. It provides minimal core functionality with extensive customization through extensions, making it flexible for building simple to complex web applications. Flask includes built-in development server, debugger, integrated unit testing support, and RESTful request dispatching.
- What are the main features of Flask?
Flask features include a built-in development server and debugger, compatibility with modern technologies, high scalability for simple applications, integrated unit testing support, secure cookies in client-side sessions, RESTful request dispatching, Google App Engine compatibility, Unicode support, and WSGI compliance. Flask also supports visual debugging and multiple database types.
- What is the difference between Flask and Django?
Flask is a WSGI microframework with diversified working style and arbitrary structure, while Django is a full-stack framework with monolithic working style and conventional project structure. Flask allows multiple database types and uses SQLAlchemy, whereas Django has built-in ORM and limited database support. Flask has RESTful URL dispatcher and supports visual debugging, while Django offers robust documentation and built-in bootstrapping with django-admin.
- What is the default host and port of Flask?
The default localhost of Flask is 127.0.0.1 and the default port is 5000. These can be changed by passing arguments to the app.run() method: app.run(host=’0.0.0.0′, port=8080).
- Which databases are compatible with Flask?
Flask supports SQLite and MySQL as backend databases using DbAdapters. Flask-SQLAlchemy enables connections to MySQL, Oracle, PostgreSQL, SQLite, Sybase, Firebird and other SQL databases. Flask-MongoEngine allows connecting to MongoDB databases.
- Why do we use Flask(name)?
The __name__ parameter is a Python built-in variable set to the current module name. Passing __name__ to Flask class constructor helps Flask determine where to locate resources like templates and static files. It sets the root path for the application.
- What is routing in Flask?
App routing maps URLs to specific functions that handle the logic for those URLs. Modern web frameworks use meaningful URLs to help users remember them and simplify navigation. Routes are defined using the @app.route() decorator: @app.route(‘/hello’) maps to www.example.org/hello.
- What is template inheritance in Flask?
Template inheritance is a powerful Jinja templating feature allowing reusable base templates. It eliminates creating identical footers, navigation bars, and headers on each webpage separately. Create common elements once in a base template and extend them in child templates, reducing code duplication.
- What does url_for() do in Flask?
The url_for() method generates URLs to specific functions dynamically. It accepts the function name as first argument, then keyword arguments matching URL variables: url_for(‘get_post_id’, post_id=post.id). This function allows creating URLs dynamically instead of hard-coding them in templates.
- How do you handle cookies in Flask?
The set_cookie() method on the response object sets cookies. Use make_response() method to create the response object in view functions. Cookies are stored as text files on client machines, tracking user actions and providing recommendations based on preferences.
- How does file uploading work in Flask?
File uploading sends binary or regular files to the server using HTML forms with multipart/form-data encryption. Server-side Flask scripts use the request.files[] object to get files from request objects. Save files to chosen server locations after successful upload: request.files[‘file’].filename.
- What is Flask-WTF and its characteristics?
Flask-WTF (WTForms) is a built-in module for creating forms in Flask applications. Features include integration with WTForms, CSRF tokens for security, global CSRF protection, internationalization support, Captcha integration, and file upload functionality with Flask Uploads.
- What HTTP methods does Flask support?
Flask supports GET (retrieve data), POST (submit form data), PUT (upload/replace content), DELETE (remove resources), and HEAD (retrieve headers without content). Each method is defined in route decorators: @app.route(‘/endpoint’, methods=[‘GET’, ‘POST’]).
- What are template engines in Flask?
Template engines build web applications split into different components for server-side applications. They render server-side data quickly including body, navigation, footer, and dashboard. Popular engines include Jinja2 (Flask default), EJS, Jade, Pug, Mustache, and HandlebarsJS.
- What is the use of jsonify() in Flask?
jsonify() converts data to JSON and wraps it in a response object with application/JSON mime-type. It automatically sets correct response headers and content type for JSON responses. Use jsonify() instead of json.dumps() for proper Flask JSON responses with appropriate headers.
- How can you access sessions in Flask?
Sessions store data between client login and logout using Flask’s session object. Configure session type: app.config[“SESSION_TYPE”] = “filesystem” and use Session(app). Access session data as dictionary: session[“name”] = value.
- Explain request database connections in Flask.
Flask provides three decorators for database connections: before_request() (called before making request with no parameters), after_request() (called after initiating request with response sent to client), and teardown_request() (called when exception is raised or everything succeeds).
- What is the g object in Flask?
g is a global namespace holding data for a single application context. It stores temporary data accessible across the request lifecycle: g.user can be set in one handler and accessed in others. Unlike session, g data doesn’t persist across requests.
- How do you enable debugging in Flask?
Enable debugging by setting the flag on the application object: app.debug = True or passing it to run method: app.run(debug=True). Debug mode reloads server when code changes, eliminating manual restarts. Debug support provides visual error messages with stack traces.
- What is a thread-local object in Flask?
Thread-local objects connect to the current thread ID and are stored in specialized structures. Flask uses them internally so users don’t transmit objects between functions within requests to maintain thread safety. This design ensures each request has isolated context.
- How is memory managed in Flask?
Memory allocation is managed by Python’s memory management system. Flask has an inbuilt garbage collector recycling unused memory to save heap space. The Python interpreter tracks everything, though users can access tools via core API.
- What types of applications can you create with Flask?
Flask can create Single Page Apps, RESTful API-based Apps, SaaS Apps, small to medium websites, static websites, Machine Learning applications, Microservices, and Serverless Apps. Flask’s flexibility allows integration with NodeJS serverless, AWS Lambda, and third-party services.
- How to create RESTful applications in Flask?
Use Flask-RESTful extension to create REST APIs. Steps include importing modules, creating API endpoints, defining request methods, implementing endpoint handlers, serializing data, error handling, and testing with tools like Postman. Flask-RESTful provides Resource classes for organizing related endpoints.
- What is Flask-Sijax?
Flask-Sijax is a Python/jQuery library making AJAX easy in Flask applications. It provides simple ways to send JSON data between server and client. Install with: pip install flask-sijax.
- Why is Flask called a microframework?
Flask is termed “micro” because its core feature set is limited to routing, request processing, and blueprints. Many features like ORM, caching, and authentication are available as optional extensions rather than included by default. The “small core + extensions” design makes it easier to start and scale.
- How to get visitor IP address in Flask?
Use request.remote_addr method to get visitor IP addresses. Example: visitor_ip = request.remote_addr returns the client’s IP address. This is useful for logging, analytics, and security features.
- Which extension connects Flask to databases?
Flask-SQLAlchemy is the primary extension for database connections. It provides ORM functionality eliminating the need for raw SQL queries. Flask-SQLAlchemy supports PostgreSQL, SQLite, MySQL and other RDBMSs.
- What is logging in Flask?
Flask logging provides event-logging systems for applications using Python’s standardized logging framework. It enables developers to create sophisticated logging systems tracking events, errors, and debugging information. Python modules can communicate and contribute during logging.
- Explain application context and request context in Flask.
Application context is created when the application starts and destroyed when it shuts down, storing configuration and global state. Request context is created when a request comes in and destroyed when completed, storing current request information like method, URL, headers, and form data.
- What is Flask-SocketIO?
Flask-SocketIO is a Flask extension providing real-time communication between clients and servers using WebSockets. It enables bidirectional, event-based communication for chat applications, live updates, and real-time dashboards.
- What is Flask-Bcrypt?
Flask-Bcrypt provides password hashing and verification functionality for Flask applications. It uses the bcrypt algorithm for secure password storage. Use it to hash passwords before storing and verify passwords during authentication.
- What is Flask-JWT?
Flask-JWT provides JSON Web Token (JWT) authentication and authorization functionality. JWTs are compact, URL-safe tokens representing claims between parties. Use Flask-JWT to implement token-based authentication for APIs.
- What is Flask-Assets?
Flask-Assets provides tools for managing and compiling static assets like CSS and JavaScript files. It bundles, minifies, and optimizes frontend assets. Flask-Assets improves page load times and simplifies asset management.
- What is Flask-Migrate?
Flask-Migrate provides database migration functionality using Alembic. It tracks database schema changes through migration scripts. Commands include flask db init, flask db migrate, and flask db upgrade.
- What is Flask-Admin?
Flask-Admin creates administrative interfaces for Flask applications. It provides simple CRUD (Create, Read, Update, Delete) interfaces for models and data. Flask-Admin offers customizable dashboards and data management tools.

Part 5: Backend Frameworks – Django (25 Questions)
- What is Django?
Django is a high-level Python web framework following the Model-View-Template (MVT) architecture. It’s a full-featured, opinionated framework with built-in ORM, admin panel, authentication system, and template engine. Django emphasizes rapid development and clean, pragmatic design.
- What is Django’s MVT architecture?
MVT separates applications into Models (database structure using Python classes), Views (business logic processing requests and returning responses), and Templates (presentation logic rendering HTML with dynamic data). This separation promotes maintainability and follows separation of concerns.
- What is Django ORM?
Django ORM (Object-Relational Mapping) translates Python code to SQL queries, allowing database interactions without writing raw SQL. It provides a high-level API for database operations: Model.objects.filter(), Model.objects.create(). Django ORM supports multiple databases and handles relationships automatically.
- How does Django handle database migrations?
Django’s migration system tracks database schema changes through Python files. makemigrations generates migration files from model changes, while migrate applies changes to the database. Migrations enable version control for schemas, support rollbacks, and facilitate team collaboration.
- What are Django models?
Models are Python classes defining database structure, each model class representing a database table. Fields are defined as class attributes: CharField, IntegerField, ForeignKey. Models include methods for business logic and validation.
- What are Django views?
Views are Python functions or classes that receive web requests and return responses. Function-based views use simple functions, while class-based views use Python classes for complex logic. Views contain business logic and coordinate between models and templates.
- What are Django templates?
Templates are HTML files with Django Template Language (DTL) for dynamic content. DTL includes variables ({{ variable }}), tags ({% for %}), filters ({{ value|filter }}), and template inheritance. Templates separate presentation from business logic.
- What is Django middleware?
Middleware is a framework of hooks into Django’s request/response processing. It’s a lightweight plugin system for globally altering input/output. Common middleware includes authentication, CSRF protection, session management, and caching.
- What is Django admin panel?
Django admin is an automatically generated administrative interface for managing application data. It reads metadata from models to provide production-ready CRUD interfaces. Customize admin by registering models and defining ModelAdmin classes.
- What are Django forms?
Django forms handle form rendering, validation, and processing. Form classes define fields, validation rules, and cleaning methods. Django provides Form for general forms and ModelForm for forms tied to models.
- What is Django REST framework?
Django REST framework (DRF) is a powerful toolkit for building Web APIs. It provides serializers, viewsets, routers, authentication, and permission classes. DRF includes browsable API interface and supports various authentication schemes.
- What are Django signals?
Signals allow decoupled applications to get notified when actions occur elsewhere in the framework. Built-in signals include pre_save, post_save, pre_delete, post_delete. Custom signals enable event-driven architectures.
- What is Django QuerySet?
QuerySets are lazy collections of database queries that aren’t executed until evaluated. Chain QuerySet methods: Model.objects.filter().exclude().order_by(). QuerySets support slicing, caching, and optimization methods like select_related() and prefetch_related().
- What is Django’s CSRF protection?
CSRF (Cross-Site Request Forgery) protection prevents unauthorized commands from trusted users. Django generates unique tokens for each session and validates them on POST requests. Use {% csrf_token %} in templates to include the token.
- What are Django’s built-in authentication features?
Django provides user authentication system including User model, login/logout views, password hashing, permissions, and groups. Authentication backend supports various authentication methods. Extend User model with custom fields using AbstractUser or AbstractBaseUser.
- What is Django’s URL routing?
URL routing maps URL patterns to view functions using URLconf (URL configuration). Define patterns in urls.py using path() or re_path() functions. URL patterns support parameters, namespaces, and include() for modular routing.
- What are Django class-based views?
Class-based views (CBVs) use Python classes providing reusable, extensible view logic. Generic views include ListView, DetailView, CreateView, UpdateView, DeleteView. CBVs use mixins for adding functionality and support method-based dispatching.
- What is Django’s template inheritance?
Template inheritance creates base templates extended by child templates using {% extends %} and {% block %}. Base templates define structure and blocks, child templates override specific blocks. This promotes DRY (Don’t Repeat Yourself) principle.
- What are Django static files?
Static files include CSS, JavaScript, and images served separately from dynamic content. Configure with STATIC_URL and STATIC_ROOT settings. Use collectstatic command to gather static files for production deployment.
- What is Django’s caching framework?
Django’s caching framework stores expensive calculations to avoid repetition. Supports multiple cache backends: Memcached, Redis, database, filesystem. Cache entire site, specific views, template fragments, or arbitrary data.
- What are Django managers?
Managers are interfaces for database query operations on models. Default manager is objects: Model.objects.all(). Create custom managers by subclassing models.Manager to encapsulate common queries.
- What is Django’s session framework?
Sessions store arbitrary data per site visitor using cookies and backend storage. Configure session engine: database, cache, file-based, or cookie-based. Access session data via request.session dictionary-like object.
- What are Django’s generic views?
Generic views are class-based views for common patterns like displaying lists, details, forms. They reduce code duplication: ListView, DetailView, FormView, CreateView. Configure with attributes or override methods for customization.
- What is Django’s testing framework?
Django’s testing framework extends Python’s unittest module with additional features. Provides TestCase class, test client for simulating requests, fixtures for test data. Run tests with python manage.py test command.
- What are Django decorators?
Django decorators modify view behavior: @login_required, @permission_required, @require_http_methods. They provide reusable functionality like authentication checks and HTTP method restrictions. Create custom decorators for application-specific logic.
Part 6: RESTful API Design (25 Questions)
- What is REST?
REST (Representational State Transfer) is an architectural style for networked applications using stateless communication and standard HTTP methods. Core principles include client-server separation, statelessness, cacheability, uniform interface, and layered system architecture. RESTful APIs represent resources through URLs and manipulate them using HTTP verbs.
- What are REST constraints?
REST constraints include client-server architecture (separation of concerns), stateless (each request contains all necessary information), cacheable (responses explicitly indicate cacheability), layered system (hierarchical layers), uniform interface (standardized resource interaction), and optional code-on-demand.
- What is a resource in REST?
Resources are any information that can be named: documents, images, collections, services. Resources are identified by URIs (Uniform Resource Identifiers). Resources have representations in formats like JSON, XML, HTML.
- What are HTTP methods in REST?
GET retrieves resources, POST creates new resources, PUT updates entire resources, PATCH partially updates resources, DELETE removes resources. HEAD retrieves headers only, OPTIONS describes communication options. Each method has specific semantics and idempotency characteristics.
- What is idempotency in REST?
Idempotent methods produce the same result regardless of how many times they’re executed. GET, PUT, DELETE, and HEAD are idempotent; POST and PATCH are not. Idempotency ensures safe retry logic for failed requests.
- What are HTTP status codes?
Status codes indicate request outcomes: 1xx (informational), 2xx (success – 200 OK, 201 Created, 204 No Content), 3xx (redirection – 301 Moved, 304 Not Modified), 4xx (client errors – 400 Bad Request, 401 Unauthorized, 404 Not Found), 5xx (server errors – 500 Internal Server Error). Proper status codes enable clients to handle responses correctly.
- What is API versioning?
API versioning manages changes without breaking existing clients. Strategies include URL path versioning (/api/v1/resource), header versioning (custom headers), query parameter versioning (?version=1), media type versioning (Accept header). Versioning enables backward compatibility and gradual migration.
- What is content negotiation?
Content negotiation allows clients to specify preferred response formats using Accept header. Servers respond with appropriate Content-Type (application/json, application/xml, text/html). Enables same API to serve multiple representation formats.
- What are REST API authentication methods?
Methods include Basic Authentication (username/password in headers), Token Authentication (bearer tokens), OAuth 2.0 (delegated authorization), API Keys (unique identifiers), JWT (JSON Web Tokens). Implement authentication middleware validating credentials before processing requests.
- What is JWT (JSON Web Token)?
JWT is a compact, URL-safe token for securely transmitting information between parties as JSON objects. Structure includes header (algorithm/type), payload (claims), signature (verification). JWTs are self-contained, stateless, and enable distributed authentication.
- What is OAuth 2.0?
OAuth 2.0 is an authorization framework enabling applications to obtain limited access to user accounts. Flow includes authorization request, user consent, authorization code, token exchange. Common grant types: authorization code, implicit, client credentials, password.
- What is CORS (Cross-Origin Resource Sharing)?
CORS is a mechanism allowing restricted resources on web pages to be requested from different domains. Browsers send preflight OPTIONS requests checking allowed origins, methods, headers. Configure CORS headers: Access-Control-Allow-Origin, Access-Control-Allow-Methods.
- What is rate limiting in APIs?
Rate limiting restricts the number of requests clients can make within a timeframe. Implements using sliding window, token bucket, or fixed window algorithms. Returns 429 Too Many Requests status when limits exceeded.
- What is API pagination?
Pagination divides large result sets into manageable chunks. Types include offset-based (?offset=20&limit=10), cursor-based (opaque identifiers), page-based (?page=2&size=10). Include pagination metadata in responses: total count, next/previous links.
- What is HATEOAS?
HATEOAS (Hypermedia As The Engine Of Application State) provides links in API responses guiding clients to available actions. Clients discover capabilities dynamically without hardcoding URLs. Enables self-documenting APIs and loose coupling.
- What is API documentation?
API documentation describes endpoints, request/response formats, authentication, error codes. Tools include Swagger/OpenAPI, Postman, API Blueprint. Good documentation includes examples, use cases, and interactive testing.
- What is OpenAPI Specification?
OpenAPI (formerly Swagger) is a standard format for describing RESTful APIs. YAML or JSON file defines endpoints, operations, parameters, authentication. Tools generate documentation, client SDKs, server stubs from specifications.
- What are API gateways?
API gateways are single entry points for multiple backend services. Handle cross-cutting concerns: authentication, rate limiting, logging, transformation. Examples include Kong, AWS API Gateway, Azure API Management.
- What is GraphQL vs REST?
REST uses multiple endpoints for different resources, GraphQL uses single endpoint with flexible queries. REST over-fetches/under-fetches data, GraphQL requests exact fields needed. GraphQL provides strongly-typed schema and real-time subscriptions.
- What are webhooks?
Webhooks are HTTP callbacks enabling real-time event notifications from servers to clients. Clients register callback URLs to receive POST requests when events occur. Useful for payment notifications, Git hooks, social media updates.
- What is API throttling?
Throttling controls API request rate to prevent abuse and ensure fair usage. Implements using leaky bucket or token bucket algorithms. Different tiers provide varying rate limits based on subscription levels.
- What is API caching?
Caching stores responses to reduce server load and improve performance. Cache headers include Cache-Control, ETag, Last-Modified. Strategies include client-side caching, CDN caching, server-side caching.
- What are API security best practices?
Use HTTPS for encryption, implement authentication/authorization, validate input, sanitize output, use rate limiting, log security events, keep dependencies updated. Apply principle of least privilege and defense in depth.
- What is API monitoring?
Monitoring tracks API performance, availability, errors, usage patterns. Metrics include response time, error rate, throughput, uptime. Tools include New Relic, Datadog, Prometheus, CloudWatch.
- What are microservices APIs?
Microservices architecture splits applications into small, independent services with dedicated APIs. Each service owns its data and communicates via APIs. Benefits include scalability, independent deployment, technology diversity.

Part 7: Database Management – SQL (30 Questions)
- What is SQL?
SQL (Structured Query Language) is a standard programming language for managing relational databases. It handles data manipulation, retrieval, definition, and control operations. SQL enables querying, updating, inserting, and deleting records in database tables.
- What is normalization?
Normalization organizes database structure to reduce redundancy and improve data integrity through progressive normal forms. First Normal Form (1NF) eliminates repeating groups, Second Normal Form (2NF) removes partial dependencies, Third Normal Form (3NF) eliminates transitive dependencies. Boyce-Codd Normal Form (BCNF) ensures every determinant is a candidate key.
- What is denormalization?
Denormalization is the inverse process of normalization, where normalized schemas are converted to schemas with redundant information. Performance improves by using redundancy and keeping data consistent. Denormalization reduces the overheads produced by over-normalized structures.
- What are SQL constraints?
Constraints specify rules for data in tables: NOT NULL (restricts NULL values), CHECK (verifies conditions), DEFAULT (assigns default values), UNIQUE (ensures unique values), INDEX (indexes fields for faster retrieval), PRIMARY KEY (uniquely identifies records), FOREIGN KEY (ensures referential integrity).
- What is a primary key?
A primary key uniquely identifies each row in a table and must contain UNIQUE values with an implicit NOT NULL constraint. A table can have only one primary key, comprised of single or multiple fields. Primary keys ensure data integrity and enable efficient indexing.
- What is a foreign key?
A foreign key comprises single or multiple fields in a table that reference the primary key in another table. The foreign key constraint ensures referential integrity between related tables. The table with the foreign key is the child table; the referenced table is the parent table.
- What are SQL joins?
SQL joins combine records from two or more tables based on related columns. INNER JOIN retrieves matching records, LEFT JOIN retrieves all left table records plus matches, RIGHT JOIN retrieves all right table records plus matches, FULL OUTER JOIN retrieves all records where there’s a match in either table. Self-joins join a table to itself.
- What is the difference between UNION and UNION ALL?
UNION combines result sets from multiple SELECT statements and removes duplicates. UNION ALL also combines result sets but retains all duplicates. UNION ALL is faster since it doesn’t perform duplicate elimination.
- What are aggregate functions in SQL?
Aggregate functions perform operations on collections of values returning single scalar values. Common functions include AVG() (calculates mean), COUNT() (counts records), MIN() (finds minimum), MAX() (finds maximum), SUM() (calculates sum), FIRST() (first element), LAST() (last element). All aggregate functions ignore NULL values except COUNT().
- What is the difference between WHERE and HAVING clauses?
WHERE filters records before grouping and cannot use aggregate functions. HAVING filters records after grouping and works with aggregate functions. WHERE is used with SELECT, UPDATE, DELETE; HAVING is used with GROUP BY.
- What is a subquery?
A subquery is a query nested within another query, also called inner query or nested query. It restricts or enhances data queried by the main query. Correlated subqueries reference columns from outer queries; non-correlated subqueries are independent.
- What are indexes in SQL?
Indexes are data structures that speed up data retrieval operations at the cost of additional writes and memory. Unique indexes maintain data integrity by ensuring no duplicate key values. Clustered indexes modify physical storage order; non-clustered indexes create separate structures.
- What is the difference between DELETE, TRUNCATE, and DROP?
DELETE removes specific rows based on conditions and can be rolled back; the structure remains. TRUNCATE removes all rows quickly, frees space, but cannot be rolled back; the structure remains. DROP removes the entire table including structure, relationships, constraints, and privileges; cannot be rolled back.
- What are SQL transactions?
Transactions are sequences of SQL operations treated as single units of work. They follow ACID properties: Atomicity (all or nothing), Consistency (valid states only), Isolation (concurrent transactions don’t interfere), Durability (committed changes persist). Transaction commands include BEGIN, COMMIT, ROLLBACK.
- What are SQL views?
Views are virtual tables based on result sets of SQL statements. They contain rows and columns like real tables but don’t store data physically. Views simplify complex queries, provide security through restricted access, and present data in different formats.
- What is a stored procedure?
Stored procedures are subroutines stored in database data dictionaries. They encapsulate reusable business logic, accept parameters, and return results. Stored procedures improve performance through precompilation, enhance security through controlled access, and centralize business logic.
- What are triggers in SQL?
Triggers are special stored procedures that execute automatically when specific database events occur. They can fire BEFORE or AFTER INSERT, UPDATE, or DELETE operations. Triggers enforce business rules, maintain audit trails, and ensure data integrity.
- What is SQL injection?
SQL injection is a security vulnerability where attackers insert malicious SQL code into application queries. It occurs when user inputs aren’t properly sanitized. Prevention methods include parameterized queries, prepared statements, input validation, and stored procedures.
- What are common SQL string functions?
String functions include CONCAT() (concatenates strings), SUBSTRING() (extracts substrings), LENGTH() (returns string length), UPPER() (converts to uppercase), LOWER() (converts to lowercase), TRIM() (removes whitespace), REPLACE() (replaces substrings).
- What are window functions in SQL?
Window functions perform calculations across sets of table rows related to the current row. They include ROW_NUMBER() (assigns row numbers), RANK() (assigns ranks with gaps), DENSE_RANK() (assigns ranks without gaps), LEAD() (accesses following row), LAG() (accesses preceding row). Window functions use OVER clause with PARTITION BY and ORDER BY.
- What is the difference between CHAR and VARCHAR?
CHAR is a fixed-length character data type that pads spaces to the specified length. VARCHAR is a variable-length character data type storing only actual characters. CHAR is faster for fixed-length data; VARCHAR saves storage for variable-length data.
- What are SQL date functions?
Date functions include NOW() (current date and time), CURDATE() (current date), CURTIME() (current time), DATE_ADD() (adds intervals), DATE_SUB() (subtracts intervals), DATEDIFF() (calculates difference), DATE_FORMAT() (formats dates).
- What is a cursor in SQL?
Cursors are control structures for traversing database records. They facilitate processing like retrieval, addition, and deletion of individual records. Cursor lifecycle includes DECLARE (define cursor), OPEN (initialize result set), FETCH (retrieve rows), CLOSE (deactivate), DEALLOCATE (release resources).
- What are common SQL numeric functions?
Numeric functions include ROUND() (rounds numbers), FLOOR() (rounds down), CEIL() (rounds up), ABS() (absolute value), POWER() (exponentiation), SQRT() (square root), MOD() (modulo operation).
- What is OLTP vs OLAP?
OLTP (Online Transaction Processing) handles high-volume transactional operations with fast response times and simple queries. OLAP (Online Analytical Processing) handles complex analytical queries with aggregations on historical data. OLTP focuses on data integrity; OLAP focuses on data analysis.
- What are common SQL clauses?
Common clauses include SELECT (specifies columns), FROM (specifies tables), WHERE (filters rows), GROUP BY (groups rows), HAVING (filters groups), ORDER BY (sorts results), LIMIT (limits result count), JOIN (combines tables).
- What is the difference between INNER JOIN and OUTER JOIN?
INNER JOIN returns only matching records from both tables. OUTER JOINs (LEFT, RIGHT, FULL) return matching records plus non-matching records from one or both tables. OUTER JOINs fill non-matching fields with NULL values.
- What are SQL set operators?
Set operators combine results from multiple queries: UNION (combines and removes duplicates), UNION ALL (combines with duplicates), INTERSECT (returns common records), EXCEPT/MINUS (returns records in first query not in second).
- What is a composite key?
A composite key is a primary key composed of multiple columns that together uniquely identify records. Composite keys are used when single columns cannot uniquely identify records. They enforce uniqueness constraints across multiple columns.
- What are SQL wildcards?
Wildcards are special characters used with LIKE operator for pattern matching. % (percent) matches zero or more characters, _ (underscore) matches exactly one character, [] (brackets) match any single character within the set. Wildcards enable flexible search queries.
Part 8: Database Management – NoSQL/MongoDB (25 Questions)
- What is MongoDB?
MongoDB is the most popular open-source, document-oriented NoSQL database holding over 45% NoSQL market share. It stores data in flexible BSON format (Binary JSON) enabling faster storage and retrieval. MongoDB supports horizontal scaling through sharding and high availability through replica sets.
- How does MongoDB differ from relational databases?
MongoDB uses document-oriented model storing data in flexible JSON/BSON documents, while relational databases use table-based models with fixed schemas. MongoDB is schema-less allowing different document structures; relational databases require predefined schemas. MongoDB scales horizontally using sharding; relational databases typically scale vertically.
- What is BSON?
BSON (Binary JSON) is a binary-encoded serialization format used by MongoDB to store documents. It extends JSON by adding data types like dates, binary data, ObjectId, and timestamps. BSON is designed for efficient storage space and scan speed.
- What are collections in MongoDB?
Collections are groups of documents in MongoDB, similar to tables in relational databases but schema-less. All documents in a collection are stored together and can be queried collectively. Collections don’t enforce uniform structure across documents.
- What is the role of _id in MongoDB?
The _id field uniquely identifies each document within a collection, acting as the default primary key. MongoDB automatically generates ObjectId values for _id if not provided. ObjectId includes timestamp, machine identifier, process id, and counter.
- What are replica sets in MongoDB?
Replica sets are groups of mongod instances maintaining identical data sets. A replica set consists of one primary node receiving all writes and multiple secondary nodes replicating the primary’s data. If the primary fails, automatic election selects a new primary ensuring high availability.[6][5]
- What is sharding in MongoDB?
Sharding distributes data across multiple servers for horizontal scaling. Data is partitioned into shards based on shard keys, with each shard holding a portion of data. MongoDB’s balancer automatically distributes data evenly across shards.
- What are MongoDB indexes?
Indexes improve query performance by creating fast lookup paths to data. MongoDB supports single field indexes, compound indexes, multikey indexes (for arrays), text indexes (for text search), and geospatial indexes. Indexes speed up reads but slow down writes.
- What are MongoDB aggregation pipelines?
Aggregation pipelines are frameworks for data processing through multi-stage transformations. Documents pass through pipeline stages performing operations like $match (filter), $group (group by), $sort (sort), $project (reshape), $lookup (join). Pipelines enable complex data analytics within MongoDB.
- What is the CAP theorem?
CAP theorem states distributed systems can guarantee only two of three properties: Consistency (all nodes see same data), Availability (system responds to requests), Partition tolerance (system functions despite network failures). MongoDB prioritizes consistency and partition tolerance (CP), though it can be configured for different trade-offs.
- What are the advantages of MongoDB?
MongoDB advantages include flexible schema design, horizontal scalability, high performance, rich query language, automatic sharding, replication for high availability, native JSON support, strong community support. It handles unstructured data efficiently and supports rapid development.
- What is GridFS?
GridFS is a specification for storing and retrieving files exceeding the 16 MB BSON document size limit. It splits large files into smaller chunks stored in separate documents within fs.files and fs.chunks collections. GridFS enables efficient storage and retrieval of large files like images and videos.
- How does MongoDB handle transactions?
MongoDB supports multi-document ACID transactions since version 4.0. Transactions ensure series of operations succeed or fail together maintaining data consistency. Use sessions to start, commit, or abort transactions: session.startTransaction(), session.commitTransaction(), session.abortTransaction().
- What are TTL indexes?
TTL (Time To Live) indexes automatically remove documents from collections after specified time periods. They’re used for data that expires like sessions, logs, or temporary data. Create TTL index: db.collection.createIndex({createdAt: 1}, {expireAfterSeconds: 3600}).
- What is the difference between embedding and referencing?
Embedding stores related data within a single document, while referencing stores related data in separate documents linked by reference. Embedding provides better read performance and atomic updates; referencing provides better write performance and reduces data duplication. Choose based on data access patterns and update frequency.
- What are capped collections?
Capped collections are fixed-size collections that overwrite oldest documents when size limit is reached. They maintain insertion order and are useful for logging, caching, or monitoring data. Create capped collection: db.createCollection(“logs”, {capped: true, size: 100000}).
- What is MongoDB Compass?
MongoDB Compass is a graphical user interface (GUI) tool for visualizing, exploring, and manipulating data. Features include schema visualization, query building, aggregation pipeline construction, index management, performance monitoring, data import/export. Compass provides an intuitive interface for database operations.
- What is MongoDB Atlas?
MongoDB Atlas is a fully managed cloud database service automating deployment, scaling, and management. It offers automated backups, monitoring, security features, global distribution, and cloud provider integration (AWS, Azure, Google Cloud). Atlas eliminates infrastructure management overhead.
- How do you perform CRUD operations in MongoDB?
Create: insertOne(), insertMany() insert documents. Read: find(), findOne() retrieve documents. Update: updateOne(), updateMany(), replaceOne() modify documents. Delete: deleteOne(), deleteMany() remove documents.
- What are MongoDB data types?
MongoDB supports String, Number (Int, Long, Double, Decimal128), Boolean, Date, Array, Object/Embedded Document, ObjectId, Null, Binary Data, Regular Expression, Timestamp, JavaScript code.
- What is write concern in MongoDB?
Write concern specifies the level of acknowledgment requested for write operations. Levels include unacknowledged (fastest), acknowledged (default), journaled (written to journal), majority (replicated to majority). Higher write concern ensures durability but impacts performance.
- What are change streams?
Change streams allow applications to listen for real-time data changes in collections, databases, or clusters. They capture insert, update, replace, and delete operations. Change streams enable event-driven architectures: db.collection.watch().
- What is hashed sharding?
Hashed sharding distributes data using hashed values of shard keys ensuring even distribution. It avoids issues with monotonically increasing values like timestamps. Useful when even data distribution is more important than range queries: sh.shardCollection(“db.collection”, {_id: “hashed”}).[5][6]
- How do you optimize MongoDB queries?
Optimization strategies include creating appropriate indexes, using projections to return only needed fields, analyzing queries with explain(), optimizing aggregation pipeline stages, using covered queries where indexes contain all queried fields.
- What is the difference between WiredTiger and MMAPv1?
WiredTiger is the modern default storage engine with document-level concurrency, compression support, better performance, and write-ahead logging. MMAPv1 is the legacy engine with collection-level concurrency, no compression, and basic journaling. WiredTiger is recommended for all new deployments.
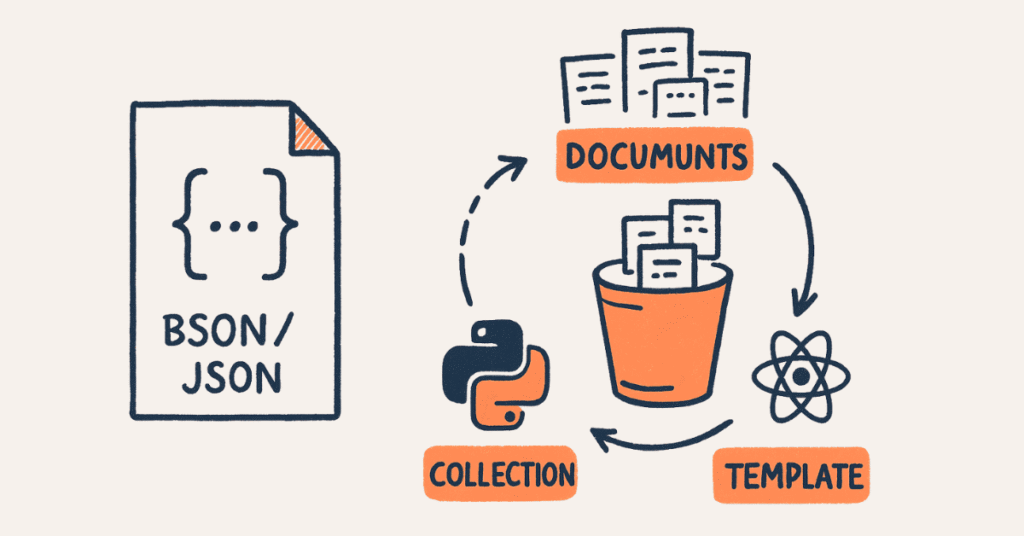
Part 9: System Design (25 Questions)
- What is system design?
System design is the process of defining architecture, components, modules, interfaces, and data for systems to satisfy specified requirements. It involves breaking down complex problems into manageable components and designing their interactions. System design interviews test ability to build scalable, robust, maintainable systems.[
- What is scalability?
Scalability is a system’s ability to handle increasing load without performance degradation. Vertical scaling adds resources to existing machines; horizontal scaling adds more machines. Horizontal scaling is preferred for large-scale systems due to better fault tolerance.
- What is load balancing?
Load balancing distributes incoming network traffic across multiple servers. Algorithms include round-robin, least connections, IP hash, and weighted distribution. Load balancers prevent single server overload and improve availability.
- What is caching?
Caching stores frequently accessed data in fast-access storage to reduce latency and database load. Cache layers include client-side, CDN, application-level, and database query caching. Cache invalidation strategies include TTL, write-through, write-back, and cache-aside.
- What is the difference between SQL and NoSQL databases?
SQL databases use structured schemas with ACID transactions and vertical scaling. NoSQL databases offer flexible schemas, eventual consistency, and horizontal scaling. SQL suits complex queries and relationships; NoSQL suits unstructured data and massive scale
- What is CAP theorem?
CAP theorem states distributed systems can guarantee only two of three: Consistency (all nodes see same data), Availability (system responds to requests), Partition tolerance (functions despite network failures). Most systems choose AP or CP based on requirements.
- What is database sharding?
Sharding partitions data across multiple databases based on shard keys. It enables horizontal scaling for large datasets. Shard key selection impacts data distribution and query performance.
- What is a microservices architecture?
Microservices architecture splits applications into small, independent services with dedicated APIs. Benefits include scalability, independent deployment, technology diversity, and fault isolation. Challenges include complexity, distributed transactions, and inter-service communication.
- What is service communication?
Service communication methods include REST (HTTP-based), gRPC (binary protocol), message queues (Kafka, RabbitMQ), and WebSockets (bidirectional). Synchronous communication blocks until response; asynchronous enables non-blocking operations.
- What is eventual consistency?
Eventual consistency is a consistency model where data replicas converge to same state eventually without guaranteeing immediate consistency. It enables higher availability and partition tolerance. Suitable for systems prioritizing availability over immediate consistency.
- What is a message queue?
Message queues enable asynchronous communication between services by storing messages until consumers process them. Popular message queues include Kafka, RabbitMQ, AWS SQS. Message queues decouple services, enable load leveling, and improve fault tolerance.
- What is rate limiting?
Rate limiting controls the number of requests clients can make within timeframes to prevent abuse. Algorithms include token bucket, leaky bucket, fixed window, sliding window. Rate limiting protects systems from overload and ensures fair resource usage.
- What is CDN?
Content Delivery Networks (CDNs) are geographically distributed servers caching content closer to users. CDNs reduce latency, improve load times, and decrease origin server load. Popular CDNs include Cloudflare, Akamai, AWS CloudFront.
- What is database replication?
Database replication copies data across multiple database servers for redundancy and high availability. Master-slave replication has one master (writes) and multiple slaves (reads). Multi-master replication allows multiple nodes to accept writes.
- What is an API gateway?
API gateways are single entry points for multiple backend services handling cross-cutting concerns. They manage authentication, rate limiting, logging, request routing, and transformation. Examples include Kong, AWS API Gateway, Azure API Management.
- What is database indexing?
Indexing creates data structures for fast data retrieval at the cost of write performance and storage. Indexes should be created on frequently queried columns. Too many indexes slow down write operations.
- What is a reverse proxy?
Reverse proxies sit between clients and servers, forwarding client requests to backend servers. Benefits include load balancing, caching, SSL termination, security, compression. Examples include Nginx, Apache, HAProxy.
- What is high availability?
High availability ensures systems remain operational with minimal downtime. Techniques include redundancy, failover mechanisms, health checks, auto-recovery, multi-region deployment. Measured by uptime percentage (e.g., 99.99% = 52 minutes downtime/year).
- What is fault tolerance?
Fault tolerance is a system’s ability to continue operating despite component failures. Techniques include redundancy, graceful degradation, circuit breakers, retry mechanisms, fallback options. Fault-tolerant systems isolate failures preventing cascading effects.
- What is idempotency?
Idempotent operations produce the same result regardless of execution count. Important for retry logic and distributed systems. GET, PUT, DELETE are idempotent; POST is not.
- What is database connection pooling?
Connection pooling maintains a cache of database connections for reuse rather than creating new connections per request. It improves performance by reducing connection overhead. Pool size should be tuned based on workload.
- What is horizontal vs vertical scaling?
Vertical scaling adds more resources (CPU, RAM) to existing machines; limited by hardware constraints. Horizontal scaling adds more machines to distribute load; enables linear scaling. Horizontal scaling provides better fault tolerance and cost-effectiveness.
- What are webhooks?
Webhooks are HTTP callbacks enabling real-time event notifications from servers to clients. Clients register callback URLs to receive POST requests when events occur. Useful for payment notifications, CI/CD pipelines, real-time integrations.
- What is a circuit breaker pattern?
Circuit breaker pattern prevents cascading failures by stopping requests to failing services. States include closed (normal operation), open (requests fail immediately), half-open (test recovery). Improves system resilience and user experience.
- What is database denormalization?
Denormalization adds redundant data to improve read performance at the cost of write complexity and storage. Common in read-heavy systems and data warehouses. Trade-off between query performance and data consistency.
Part 10: Testing & Quality Assurance (15 Questions)
- What is software testing?
Software testing is the process of evaluating and verifying that software applications function as intended. It involves executing test cases to identify bugs, ensure quality, validate requirements, and verify that the software meets user expectations. Testing can be manual or automated depending on project requirements.
- What is the difference between manual and automated testing?
Manual testing involves human testers executing test cases without automation tools, suitable for exploratory and usability testing. Automated testing uses software tools to execute tests repeatedly and consistently, ideal for regression testing and repetitive tasks. Automation testing increases efficiency, speed, and accuracy while reducing human error.
- What is unit testing?
Unit testing involves testing individual components or functions in isolation to verify they work correctly. Each unit test focuses on a single piece of functionality, typically written by developers during development. Python frameworks for unit testing include unittest, pytest, and nose2.
- What is integration testing?
Integration testing verifies that different modules or services work together correctly. It tests interfaces between components, data flow across modules, and interaction with external services. Integration testing identifies issues in component interactions that unit tests might miss.
- What is regression testing?
Regression testing ensures that new code changes haven’t broken existing functionality. It involves re-running previous test cases after modifications to verify stability. Automated regression testing is preferred for efficiency in continuous integration environments.
- What testing frameworks are available in Python?
Python testing frameworks include unittest (built-in standard library), pytest (feature-rich with fixtures and plugins), nose2 (extends unittest), doctest (tests code examples in documentation), and Robot Framework (keyword-driven acceptance testing). Pytest is the most popular due to its simplicity and powerful features.
- What is test-driven development (TDD)?
TDD is a development approach where tests are written before code implementation. The cycle follows: write failing test, write minimal code to pass test, refactor code while keeping tests passing. TDD improves code quality, reduces bugs, and ensures testable code design.
- What is Selenium for automation testing?
Selenium is an open-source framework for automating web browser interactions. It supports multiple browsers (Chrome, Firefox, Safari) and programming languages including Python. Selenium WebDriver enables automated testing of web applications by simulating user actions.
- What are the types of automation testing frameworks?
Framework types include Modular (dividing test scripts into modules), Data-Driven (separating test data from scripts), Keyword-Driven (using keywords for test actions), Hybrid (combining multiple approaches), Behavior-Driven Development (BDD using Gherkin syntax), and Test-Driven Development (TDD).
- How do you handle dynamic elements in Selenium?
Handle dynamic elements using explicit waits with WebDriverWait class that waits until specific conditions are met. Use Expected Conditions like element_to_be_clickable(), presence_of_element_located(), and visibility_of_element_located(). This ensures elements are ready before performing actions.
- What is data-driven testing?
Data-driven testing stores test data and expected results in separate data sources like spreadsheets or databases rather than hardcoding in test cases. This approach enables running multiple iterations of the same test with different input values. It improves test coverage and maintainability.
- What is pytest and its advantages?
Pytest is a Python testing framework providing simple syntax, powerful fixtures, parametrized testing, plugin architecture, and detailed assertion introspection. Advantages include less boilerplate code than unittest, better error messages, support for fixtures and mocking, and parallel test execution.
- What are pytest fixtures?
Fixtures are reusable setup and teardown functions providing test data, database connections, or configured objects to tests. Defined using @pytest.fixture decorator, fixtures enable dependency injection and resource management. Fixtures support scope levels: function, class, module, session.
- What is mocking in testing?
Mocking replaces real objects with simulated versions to isolate code under test from external dependencies. Python’s unittest.mock module provides Mock and MagicMock objects for creating mocks. Mocking enables testing code that depends on databases, APIs, or external services without actual connections.
- What are common challenges in automation testing?
Challenges include maintaining tests as code changes, handling dynamic elements, working with multi-threaded and asynchronous systems, test performance and stability with large datasets, managing test data, dealing with flaky tests, and cross-browser compatibility.
Part 11: Version Control – Git (15 Questions)
- What is Git?
Git is a distributed version control system enabling developers to track and manage code changes. It allows multiple developers to collaborate simultaneously without interfering with each other’s work. Git records every modification with author and timestamp information.
- What is the difference between Git and GitHub?
Git is a version control tool for tracking source code changes locally. GitHub is a cloud-based hosting service for managing Git repositories with additional features like permissions, issue tracking, and collaboration tools. GitHub provides a web interface for Git operations.
- What is a Git repository?
A Git repository is a storage location containing project files and complete change history. It can exist locally on a computer or remotely on platforms like GitHub. Repositories include all files, branches, commits, and metadata.
- What are the main Git commands?
Essential commands include git init (initialize repository), git clone (copy repository), git add (stage changes), git commit (save changes), git push (upload to remote), git pull (download and merge), git branch (manage branches), git merge (combine branches).
- What is a commit in Git?
A commit is a snapshot recording the current state of staged changes with metadata including author, timestamp, and unique SHA-1 hash identifier. Commits create version history enabling tracking and reverting changes. Each commit should represent a logical unit of work.
- What is branching in Git?
Branching creates separate development lines allowing work on features, fixes, or experiments independently without affecting the main codebase. Branches enable parallel development and isolated testing. Common branches include main/master, develop, feature branches, and hotfix branches.
- What is the difference between git pull and git fetch?
git fetch downloads updates from remote repository without integrating them into local branches. git pull performs fetch followed by automatic merge into the current branch. Fetch allows reviewing changes before merging; pull combines both operations.
- How do you resolve merge conflicts?
Resolve conflicts by editing affected files to choose which changes to keep, marking conflicts with <<<<<<<, =======, and >>>>>>> markers. After manual resolution, use git add to stage resolved files and git commit to complete the merge. Communication with team members helps resolve complex conflicts.
- What is git rebase?
git rebase rewrites commit history by moving commits from one branch onto another, creating linear history. It transfers changes by replaying commits on top of the target branch. Rebasing creates cleaner history but should not be used on public branches.
- What is the difference between git merge and git rebase?
git merge preserves branch history by creating a merge commit combining two branches. git rebase rewrites history by placing commits from one branch atop another, creating linear progression. Merge is safer for shared branches; rebase creates cleaner history for local branches.
- What is a .gitignore file?
A .gitignore file specifies intentionally untracked files that Git should ignore. It typically includes build artifacts, local configuration files, dependencies, and sensitive data. Patterns match files and directories to exclude from version control.
- What is git stash?
git stash temporarily saves uncommitted changes allowing clean working directory for switching branches. Stashed changes can be reapplied later using git stash pop or git stash apply. Multiple stashes can be maintained in a stack.
- What are Git workflows?
Git workflows define branching strategies and collaboration patterns including Git Flow (master, develop, feature, release, hotfix branches), GitHub Flow (main branch with feature branches), and GitLab Flow (environment branches). Workflows standardize team collaboration and release management.
- What is a remote in Git?
A remote is a shared repository hosted on servers or cloud platforms for team collaboration. Common remote operations include git remote add, git remote -v (list remotes), git push, and git pull. Origin is the default remote name for cloned repositories.
- What is git cherry-pick?
git cherry-pick applies changes from specific commits to the current branch without merging entire branches. It’s useful for applying bug fixes from one branch to another selectively. Use with caution to avoid duplicate commits.
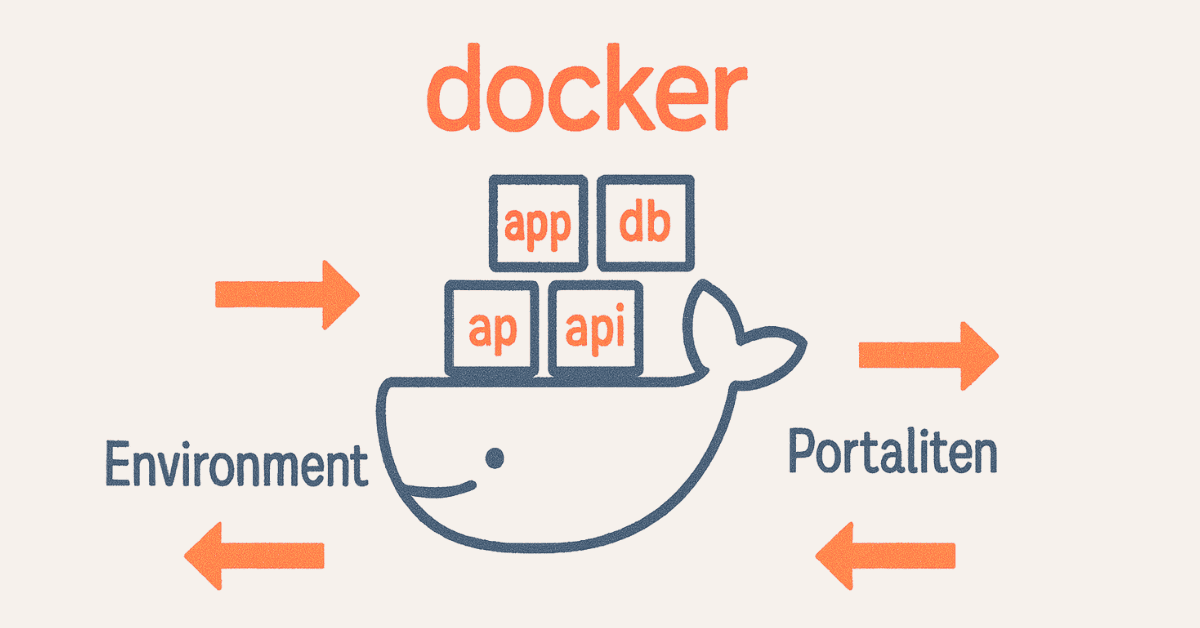
Part 12: Containerization – Docker (15 Questions)
- What is Docker?
Docker is an open-source platform for building, deploying, and managing containerized applications. It packages applications with dependencies into standardized containers ensuring consistency across environments. Docker accelerates development from building to scaling without environment configuration.
- What is a Docker container?
A Docker container is a lightweight, standalone executable package containing code, runtime, libraries, system tools, and settings. Containers provide isolated environments enabling consistent application execution across different platforms. They boot in seconds and use less memory than virtual machines.
- How does Docker differ from virtual machines?
Docker uses execution engines and shares the host OS kernel, boots in seconds, requires less memory, and creates lightweight containers. Virtual machines use hypervisors, run complete operating systems, take minutes to boot, consume more memory, and provide stronger isolation. Docker is more efficient for microservices; VMs provide better security isolation.
- What is a Docker image?
Docker images are read-only templates containing instructions for creating containers. They’re built from Dockerfiles and include application code, dependencies, libraries, and configurations. Images are shareable, portable, and stored in registries like Docker Hub.
- What is a Dockerfile?
A Dockerfile is a text document containing commands to assemble Docker images. Commands include FROM (base image), COPY (copy files), RUN (execute commands), EXPOSE (expose ports), CMD (default command). Dockerfiles must begin with FROM instruction.
- What is Docker Hub?
Docker Hub is a cloud-based registry service for storing, sharing, and distributing Docker images. It provides public repositories (open access) and private repositories (restricted access) with verified, secure images. Docker Hub enables image version management and automated builds.
- What is Docker Compose?
Docker Compose is a tool for defining and running multi-container applications using YAML configuration files. It manages multiple services, volumes, and networks from a single docker-compose.yml file. Compose works across all environments: development, staging, production, testing.
- How do you create a Docker network?
Create Docker networks using docker network create [OPTIONS] NETWORK command. Docker networks connect services running in separate containers enabling communication while maintaining decoupling. Networks provide isolation, security, automatic service discovery, and dynamic scaling.
- What are Docker volumes?
Docker volumes are persistent storage mechanisms for containers created with docker volume create command. They enable data persistence beyond container lifecycle, sharing data between containers, and work on both Linux and Windows. Volumes are managed through Docker CLI or API.
- What is the difference between docker run and docker start?
docker run creates and starts a new container from a specific image, executing the main process. docker start begins a previously stopped container, resuming the main process. Run is for new containers; start is for existing stopped containers.
- What is a multi-stage build?
Multi-stage builds optimize Dockerfiles by dividing image building into multiple stages using multiple FROM statements. They include only necessary dependencies in the final image, reducing size while maintaining readability. Each stage can copy artifacts from previous stages.
- What is container orchestration?
Container orchestration automates deployment, scaling, networking, and availability of containerized applications. Docker Swarm and Docker Compose are built-in tools; Kubernetes is the most popular external orchestration platform. Orchestration manages service discovery, load balancing, rolling updates, and replica counts.
- What are Docker namespaces?
Namespaces provide isolated workspaces for containers through Linux kernel features. Types include user namespace (user isolation), network namespace (network isolation), PID namespace (process isolation), IPC namespace (interprocess communication isolation). Namespaces enable container isolation and resource separation.
- What is the role of cgroups in Docker?
Control groups (cgroups) limit and allocate system resources like CPU and memory for Docker containers. They prevent “noisy neighbor” issues where one container consumes excessive resources. Cgroups enable resource management and container isolation.
- How does Docker improve Continuous Delivery?
Docker streamlines deployment by creating consistent images automatically when code is submitted. It integrates with source control and CI/CD tools, enables parallel building and testing, reduces deployment time, and minimizes errors. Docker containers ensure environment consistency from development to production.
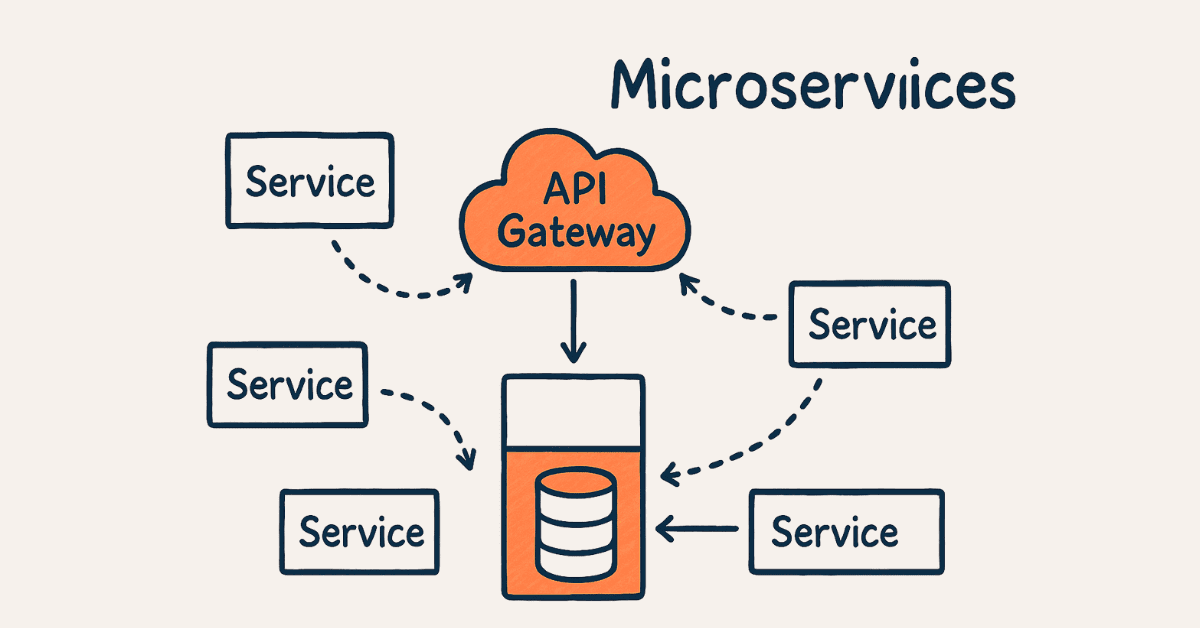
Part 13: Best Practices & Professional Skills (10 Questions)
- What are REST API design best practices?
Best practices include using nouns for resource URLs not verbs, implementing proper HTTP methods, using appropriate status codes, versioning APIs, implementing authentication and authorization, providing comprehensive documentation, using pagination for large datasets, implementing rate limiting, and ensuring error messages are descriptive.
- What are database optimization techniques?
Optimization techniques include creating appropriate indexes, using query execution plans, normalizing data structure, implementing connection pooling, using caching layers, optimizing queries with proper JOINs, avoiding N+1 query problems, partitioning large tables, using database replication for read scaling, and regular maintenance operations.
- What is the importance of code reviews?
Code reviews improve code quality, share knowledge across teams, catch bugs early, ensure adherence to coding standards, facilitate mentorship, improve security by identifying vulnerabilities, promote best practices, and enhance collaboration. Reviews should be constructive and focus on code quality not personal criticism.
- What are microservices best practices?
Best practices include designing services around business capabilities, implementing independent deployment, using API gateways, implementing circuit breakers for fault tolerance, using containerization, implementing distributed tracing, maintaining service independence, using event-driven architecture, implementing health checks, and documenting service contracts.
- What is CI/CD?
CI/CD (Continuous Integration/Continuous Deployment) is a practice where code changes are automatically tested, integrated, and deployed. Continuous Integration merges code frequently with automated testing; Continuous Deployment automatically releases to production. CI/CD reduces manual errors, accelerates delivery, and improves software quality.
- What are security best practices for web applications?
Security practices include validating and sanitizing all inputs, using HTTPS everywhere, implementing proper authentication and authorization, protecting against SQL injection using parameterized queries, preventing XSS attacks by escaping output, implementing CSRF protection, using secure password hashing, keeping dependencies updated, implementing rate limiting, and following principle of least privilege.
- What is the importance of logging and monitoring?
Logging and monitoring enable debugging production issues, tracking application performance, identifying bottlenecks, detecting security incidents, understanding user behavior, ensuring SLA compliance, and proactive issue resolution. Implement structured logging with appropriate log levels (DEBUG, INFO, WARNING, ERROR, CRITICAL).
- What are performance optimization strategies?
Strategies include implementing caching at multiple layers, optimizing database queries, using CDNs for static content, implementing lazy loading, minimizing HTTP requests, compressing assets, optimizing images, using asynchronous operations, implementing connection pooling, and load balancing.
- What is technical debt?
Technical debt refers to implied cost of future rework caused by choosing quick solutions over better approaches. It accumulates through shortcuts, outdated dependencies, poor documentation, and neglected refactoring. Managing technical debt requires balancing feature development with code improvement efforts.
- What are SOLID principles?
SOLID principles are object-oriented design guidelines: Single Responsibility (classes should have one reason to change), Open/Closed (open for extension, closed for modification), Liskov Substitution (derived classes must be substitutable for base classes), Interface Segregation (many specific interfaces better than one general), Dependency Inversion (depend on abstractions not concretions). These principles improve code maintainability and flexibility.
🗺️ Not sure what to learn next?
Follow our Python Developer Roadmap to prepare module-by-module from beginner to pro.

2. Self-Preparation Prompts Using ChatGPT
Coding Problem Practice Prompts
- Data Structures Implementation Practice
“I’m preparing for Python full stack interviews. Generate a medium-difficulty problem that requires implementing [specific data structure like binary tree, linked list, hash map]. Include the problem statement, example inputs/outputs, constraints, and edge cases to consider. After I submit my solution, analyze its time and space complexity and suggest optimizations.
- Algorithm Pattern Recognition
“Explain the [sliding window/two pointers/dynamic programming] algorithm pattern with a step-by-step breakdown. Then provide 3 progressively difficult practice problems that use this pattern. For each problem, wait for my solution before revealing the optimal approach.”
- Code Optimization Challenge
“Review the following Python code I wrote: [paste your code]. Analyze its time complexity, space complexity, and suggest optimizations. Explain why your suggested approach is more efficient and provide refactored code with detailed comments explaining the improvements.”
- Debugging Skill Enhancement
“Generate a Python function with 3-5 subtle bugs related to [data types/edge cases/logic errors]. Don’t reveal the bugs initially. Let me identify and fix them, then provide feedback on what I missed and explain the correct debugging approach for each issue.”
- Full Stack Problem Solving
“Create a real-world full stack scenario where I need to design both frontend and backend components. Include requirements for React components, REST API endpoints, database schema, and authentication flow. Guide me through the implementation step-by-step, asking clarifying questions along the way.”
Technical Concept Clarification Prompts
- Deep Dive into Complex Topics
“I’m confused about [async/await in Python, React hooks lifecycle, database indexing]. Explain this concept as if teaching a developer with 1 year of experience. Use analogies, code examples, and real-world use cases. Then quiz me with 3 scenario-based questions to test my understanding.”
- Comparative Analysis
“Compare [Django vs Flask / SQL vs NoSQL / Class components vs Functional components] for full stack development. Create a comparison table covering use cases, pros/cons, performance characteristics, and learning curve. Then provide a decision-making framework for choosing between them based on project requirements.”
- System Design Fundamentals
“Explain how to design a [URL shortener/social media feed/e-commerce cart] system from scratch. Break down the explanation into: database schema, API endpoints, frontend architecture, scalability considerations, and potential bottlenecks. Ask me questions to verify my understanding at each stage.”
- Framework-Specific Deep Dive
“I need to master [Django ORM/React Context API/Flask-SQLAlchemy]. Provide a comprehensive learning path starting from basics to advanced features. Include practical examples, common pitfalls, best practices, and 5 challenging exercises that progressively build on each other.”
- Error Handling Scenarios
“Generate 5 different error scenarios in Python full stack applications (database connection failures, API timeouts, validation errors, etc.). For each scenario, explain proper error handling strategies, appropriate HTTP status codes, user-facing messages, and logging practices.”
Mock Interview Simulation Prompts
- Technical Screening Round
“Act as a technical interviewer for a Python Full Stack Developer position at a mid-sized tech company. Conduct a 45-minute technical screening covering Python fundamentals, React basics, and REST API design. Ask one question at a time, evaluate my answer before proceeding, and provide a detailed assessment at the end with areas for improvement.”
- Live Coding Interview
“Simulate a live coding interview. Present a medium-difficulty algorithm problem and give me 30 minutes to solve it. As I explain my approach, ask clarifying questions like a real interviewer would. After submission, critique my solution’s efficiency, code quality, communication clarity, and suggest optimizations.”
- System Design Interview
“Conduct a system design interview for designing [Netflix-like video streaming platform/Twitter clone/food delivery app]. Guide me through requirements gathering, capacity estimation, API design, database schema, caching strategy, and scalability considerations. Challenge my decisions with follow-up questions and trade-off discussions.”
- Debugging Session Interview
“Present a full stack application with multiple bugs across frontend (React), backend (Django/Flask), and database layers. Give me 20 minutes to identify issues, explain root causes, and propose fixes. Evaluate my debugging methodology, tool usage, and problem-solving approach.”
- Architecture Review Interview
“Show me a poorly designed full stack application architecture. Ask me to identify architectural flaws, security vulnerabilities, performance bottlenecks, and scalability issues. Then have me propose an improved architecture with justifications for each design decision.”
Code Review and Feedback Prompts
- Code Quality Assessment
“Review the following code I wrote for [specific functionality]. Evaluate it based on: code readability, adherence to Python PEP 8 standards, proper use of design patterns, error handling, documentation quality, and test coverage. Provide actionable feedback with specific examples of improvements.”
- Security Vulnerability Analysis
“Analyze this API endpoint/React component for security vulnerabilities including SQL injection, XSS attacks, CSRF, authentication bypass, and sensitive data exposure. Explain each vulnerability found, its potential impact, and provide secure code alternatives.”
- Performance Optimization Review
“I’ve implemented [feature/component/API endpoint]. Review it for performance issues including N+1 queries, unnecessary re-renders, inefficient algorithms, memory leaks, and improper caching. Suggest specific optimizations with before/after performance metrics.”
- Best Practices Validation
“Evaluate whether my code follows full stack development best practices for: RESTful API design, React component structure, database normalization, error handling, logging, testing, and documentation. Highlight violations and explain the correct approach for each.”
- Refactoring Guidance
“This code works but needs refactoring. Guide me through improving: separation of concerns, reducing code duplication, applying SOLID principles, improving naming conventions, and enhancing maintainability. Show the refactored version with explanatory comments.”
Problem-Solving Strategy Prompts
- Approach Development
“I’m stuck on [specific problem]. Don’t give me the solution yet. Instead, ask me guiding questions to help me develop the problem-solving approach myself. If I’m still stuck after 3 hints, reveal the approach step-by-step.”
- Multiple Solution Exploration
“For this problem: [problem statement], generate 3 different solution approaches (brute force, optimized, and highly optimized). For each approach, explain the thought process, trade-offs, time/space complexity, and when to use that particular approach.”
- Edge Case Identification
“I’ve solved this problem: [problem description and solution]. Help me identify edge cases I might have missed including: empty inputs, null values, extreme values, concurrent requests, network failures, and boundary conditions. For each edge case, explain how to handle it properly.”
- Trade-off Analysis
“For [specific technical decision like choosing between SQL/NoSQL, monolith/microservices, SSR/CSR], present the trade-offs in terms of: performance, scalability, development speed, maintenance complexity, team expertise requirements, and cost. Help me make an informed decision based on project context.”
- Pattern Recognition Training
“Show me 5 coding problems that appear different but use the same underlying algorithm pattern. Don’t reveal the pattern initially. After I attempt all problems, reveal the common pattern and explain how recognizing it accelerates problem-solving in interviews.”
Technical Communication Prompts
- Explanation Practice
“I need to explain [technical concept] to a non-technical stakeholder. Evaluate my explanation for: clarity, use of appropriate analogies, avoiding jargon, addressing business impact, and engagement. Provide feedback and show an improved version.”
- Documentation Writing
“Review my API documentation/README file for: completeness, clarity, code examples, error response documentation, authentication instructions, and setup steps. Suggest improvements following industry-standard documentation practices.”
- Technical Presentation Simulation
“I need to present my project architecture to a technical panel. Act as the panel and ask challenging questions about: design decisions, scalability strategy, technology choices, security measures, and failure handling. Evaluate my responses for technical accuracy and communication effectiveness.”
- Code Walkthrough Practice
“I’ll walk you through my code for [specific feature]. Interrupt me with questions when: assumptions aren’t clear, edge cases aren’t addressed, or optimization opportunities exist. Then provide feedback on my code explanation clarity and technical communication skills.”
- Problem Statement Clarification
“Present an intentionally vague problem statement. Train me to ask the right clarifying questions about: requirements, constraints, scale expectations, performance criteria, security requirements, and edge case handling before jumping into implementation.”
Specialized Topic Prompts
- React Advanced Concepts
“Deep dive into [React performance optimization/custom hooks/context patterns/state management]. Provide advanced interview questions, real-world scenarios where these concepts apply, anti-patterns to avoid, and hands-on exercises to solidify understanding.”
- Django/Flask Mastery
“I’m preparing for Django/Flask interview questions. Generate 10 scenario-based questions covering: ORM optimization, middleware implementation, authentication/authorization, RESTful API design, testing strategies, and deployment considerations. For each answer I provide, give detailed feedback.”
- Database Query Optimization
“Present a slow database query and application context. Guide me through: analyzing the query execution plan, identifying bottlenecks, adding appropriate indexes, rewriting the query for efficiency, and implementing caching strategies. Compare performance before and after.”
- Authentication & Authorization
“Explain and quiz me on: JWT vs session-based authentication, OAuth 2.0 flow, role-based access control (RBAC), secure password storage, token refresh strategies, and preventing common security vulnerabilities in authentication systems.”
- API Design Best Practices
“I’m designing a REST API for [specific domain]. Review my API design for: proper HTTP method usage, resource naming conventions, versioning strategy, pagination implementation, error response format, rate limiting, and HATEOAS principles. Provide improvement suggestions.”
Progressive Learning Prompts
- Structured Learning Path
“Create a 30-day intensive preparation plan for Python Full Stack interviews. Break it down week-by-week with specific topics, practice problems, projects to build, and daily goals. Include checkpoint assessments to measure progress and adjust difficulty accordingly.”
- Weak Area Identification
“Quiz me on various full stack topics (Python, React, databases, system design, etc.) with 20 mixed-difficulty questions. Based on my answers, identify my weak areas and create a targeted improvement plan with specific resources and practice exercises.”
- Project-Based Learning
“Guide me through building a complete full stack project (like a task management app) from scratch. At each stage (database design, API development, frontend implementation, testing, deployment), explain best practices and challenge me with extension features to implement independently.”
- Interview Simulation Series
“Conduct a series of 5 progressive mock interviews increasing in difficulty: screening call, technical phone screen, live coding round, system design round, and final behavioral round. After each session, provide comprehensive feedback and preparation tips for the next round.”
- Real-world Scenario Practice
“Present realistic work scenarios I might face as a full stack developer: debugging production issues, implementing new features under tight deadlines, refactoring legacy code, handling database migrations, or optimizing slow endpoints. Guide me through proper problem-solving approaches for each scenario.”
Confidence Building Prompts
- Success Story Analysis
“Analyze successful interview experiences of Python Full Stack developers. Extract common patterns in: how they approached problems, what impressed interviewers, how they handled questions they didn’t know, and their preparation strategies. Create actionable insights I can apply.”
- Imposter Syndrome Management
“I’m feeling underprepared for interviews. Help me assess my current skill level objectively through targeted questions across different domains. Then create a confidence-building plan highlighting my strengths while systematically addressing knowledge gaps.”
- Stress Management Techniques
“Simulate high-pressure interview scenarios with time constraints and challenging questions. After each scenario, teach me stress management techniques, breathing exercises, and mental frameworks to stay calm and think clearly during actual interviews.”
- Learning from Mistakes
“I failed an interview because of [specific reason]. Help me analyse what went wrong, identify knowledge gaps versus communication issues, and create a recovery plan to turn this weakness into strength for future interviews.”
- Interview Day Preparation
“It’s the night before my interview. Create a final review checklist covering: key technical concepts to refresh, common pitfalls to avoid, questions to ask the interviewer, what to bring/setup for virtual interviews, and mental preparation strategies to perform at my best.”
⚙️ Theory is not enough — start applying!
Explore our Python Hands-on How-to Guides for practical coding examples and real-world problem-solving.

3.Communication Skills and Behavioural Interview Preparation
Understanding the STAR Method
The STAR method is a structured approach for answering behavioural interview questions by organizing responses into four components: Situation (20%), Task (10%), Action (60%), and Result (10%). This framework helps deliver clear, concise, and compelling stories that demonstrate relevant skills and experiences. The majority of response time should focus on actions taken, highlighting personal contributions using “I” rather than “we” to showcase individual impact.
Common Behavioural Questions for Developers
- Tell me about a time you solved a complex technical problem.
Use the STAR framework to structure responses effectively. Describe the specific technical challenge faced, explain the task or goal, detail the analysis and implementation steps taken personally, and quantify the outcome with metrics like performance improvements or user satisfaction gains. Focus on problem-solving methodology, technical decision-making process, and lessons learned from the experience.
- Describe a situation where you had to work with a difficult team member.
Emphasize collaboration, empathy, and conflict resolution skills in responses. Explain the interpersonal challenge context, describe responsibilities in resolving the situation, detail communication strategies and compromises made, and highlight positive outcomes like improved team dynamics or successful project completion. Demonstrate emotional intelligence and professionalism in handling workplace relationships.
- How do you handle tight deadlines and multiple priorities?
Showcase time management, prioritization, and stress management abilities. Describe a high-pressure situation with competing demands, explain the prioritization framework used to evaluate task urgency and importance, detail organizational strategies like breaking tasks into manageable chunks or delegating appropriately, and present outcomes demonstrating successful delivery despite constraints. Mention tools or techniques used for tracking and managing workload.
- Tell me about a time you made a mistake and how you handled it.
Demonstrate accountability, learning mindset, and problem-solving under pressure. Describe the error and its context honestly, explain responsibility accepted and immediate actions taken to mitigate impact, detail the corrective measures implemented and communication with stakeholders, and emphasize lessons learned and preventive measures adopted going forward. This question assesses maturity and growth potential.
- Describe a situation where you had to learn a new technology quickly.
Highlight adaptability, self-learning capabilities, and technical agility. Explain the business need or project requirement driving the learning, describe the learning approach taken including resources utilized and practice methods, detail how the new knowledge was applied to deliver value, and quantify the impact on project success or personal skill development. Demonstrate enthusiasm for continuous learning in the fast-paced tech industry.
- How do you handle disagreements about technical approaches?
Showcase collaboration, technical communication, and consensus-building skills. Describe a specific technical debate or architectural disagreement, explain personal perspective and the alternative viewpoints involved, detail how evidence and trade-off analysis were used to facilitate discussion, and present the resolution reached and its positive impact on the project. Emphasize respect for diverse perspectives and data-driven decision-making
- Tell me about a project you’re most proud of.
Structure responses to highlight technical depth, business impact, and personal growth. Describe the project scope, challenges, and significance, explain personal role and responsibilities within the team context, detail innovative solutions or technical excellence demonstrated, and quantify results using metrics like user adoption, performance improvements, or revenue impact. Choose projects that align with the role’s requirements.
- Describe a time when you received critical feedback.
Demonstrate openness to feedback, emotional intelligence, and growth orientation. Explain the feedback received and the context in which it was delivered, describe initial reaction and reflection process, detail specific actions taken to address the feedback and improve performance, and present evidence of improvement and positive outcomes from implementing changes. This reveals coachability and self-awareness.
- How do you explain technical concepts to non-technical stakeholders?
Highlight communication adaptability and stakeholder management skills. Describe a situation requiring technical translation for business audiences, explain the challenge of bridging knowledge gaps while maintaining accuracy, detail techniques used such as analogies, visual aids, or incremental explanations, and present outcomes showing stakeholder understanding and buy-in achieved. This skill is crucial for full stack developers interfacing with diverse teams.
- Tell me about a time you had to advocate for a technical decision.
Showcase persuasion, technical leadership, and strategic thinking abilities. Describe the technical recommendation and why it faced resistance, explain the stakeholder concerns and organizational context, detail the evidence, cost-benefit analysis, and communication strategies employed to build support, and present the decision outcome and its validation through project success. Demonstrate ability to influence without authority.
Effective Technical Communication
- Articulating Problem-Solving Approach
During technical discussions, verbalize thought processes by explaining problem understanding, constraint identification, and solution exploration. Use structured communication frameworks like “First, I would clarify requirements; second, I would consider these approaches; third, I would evaluate trade-offs”. This demonstrates organized thinking and helps interviewers follow reasoning even if the final solution isn’t perfect.
- Explaining Code and Architecture
When walking through code or design decisions, start with high-level architecture before diving into implementation details. Explain the “why” behind decisions, not just the “what,” connecting technical choices to business requirements or performance goals. Use clear analogies when appropriate and check for understanding by pausing for questions.
- Handling “I Don’t Know” Situations
When facing unfamiliar questions, honestly acknowledge knowledge gaps rather than fabricating answers. Immediately follow with related knowledge or a logical approach to finding the solution: “I haven’t worked directly with that framework, but based on my experience with similar technologies, I would approach it by…”. This demonstrates intellectual honesty and problem-solving resourcefulness.
- Active Listening in Technical Discussions
Practice active listening by taking notes during problem statements, asking clarifying questions before jumping to solutions, and paraphrasing requirements to confirm understanding. This prevents solving the wrong problem and demonstrates attention to detail valued in full stack development. Interviewers often provide hints during discussions that active listeners catch.
- Managing Interview Anxiety
Control nervousness through breathing techniques, positive self-talk, and reframing anxiety as excitement. If stuck during technical questions, verbalize the challenge: “Let me take a moment to think through this systematically”. Interviewers appreciate candidates who think aloud and maintain composure under pressure rather than freezing silently.
Non-Verbal Communication
- Body Language in Virtual Interviews
Maintain eye contact by looking at the camera rather than the screen, use hand gestures naturally to emphasize points, and position yourself at appropriate distance from the camera. Ensure good lighting, eliminate background distractions, and test technology beforehand to avoid technical fumbles that undermine confidence. Non-verbal cues significantly impact interviewer perception even in remote settings.
- Enthusiasm and Engagement
Display genuine interest through vocal variety, avoiding monotone delivery that signals disengagement. Smile naturally, nod to show active listening, and lean slightly forward to convey engagement. Energy level should match the conversation flow while remaining professional and authentic.
- Professional Presence
Dress appropriately for the company culture, maintain good posture throughout the interview, and minimize fidgeting or distracting movements. Professional appearance and demeanor create positive first impressions that influence hiring decisions beyond technical qualifications. Treat video interviews with the same professionalism as in-person meetings.
Structuring Behavioural Responses
- Crafting Compelling Stories
Prepare 8-10 diverse stories covering different competencies: technical problem-solving, teamwork, leadership, conflict resolution, failure and learning, innovation, and time management. Each story should be adaptable to multiple question variations and demonstrate growth or impact. Practice telling stories concisely within 2-3 minutes to respect interviewer time while providing sufficient detail.
- Quantifying Impact
Strengthen responses with specific metrics: “reduced API response time by 40%,” “improved test coverage from 60% to 95%,” or “mentored 3 junior developers who were promoted within a year”. Numbers make accomplishments tangible and memorable, differentiating candidates from those who provide vague descriptions. Even approximate figures are better than no quantification.
- Focusing on Personal Contribution
Clearly delineate individual actions from team efforts using first-person language. Instead of “we implemented a new architecture,” say “I designed the microservices architecture while my teammates focused on frontend implementation”. Interviewers assess individual capabilities, so highlighting personal contributions while acknowledging team context is essential.
- Demonstrating Learning and Growth
Conclude stories with lessons learned and how those insights influenced future behaviour or decisions. For failure stories, emphasize corrective actions taken and demonstrate that mistakes led to professional development. Growth mindset is highly valued in fast-evolving tech environments where continuous learning is mandatory.
Company-Specific Behavioural Questions
- “Why do you want to work here?”
Research the company’s products, technology stack, culture, and recent developments thoroughly. Connect personal career goals and values to specific aspects of the company: “I’m excited about your commitment to open-source contributions, which aligns with my passion for community-driven development”. Avoid generic responses that could apply to any company.
- “Where do you see yourself in five years?”
Balance ambition with realistic expectations and alignment to the role’s growth trajectory. Express interest in technical depth, leadership opportunities, or specialized expertise relevant to the company’s domain. Avoid responses suggesting short tenure or career pivots away from the role being hired for.
- “What are your salary expectations?”
Research market rates for Python Full Stack developers in the location and company size bracket. Provide a range based on research while expressing flexibility: “Based on my research and experience level, I’m targeting $X to $Y, but I’m open to discussion based on the complete compensation package”. Defer detailed negotiation until after receiving an offer when possible.
Teamwork and Collaboration Questions
- “Describe your ideal team environment.”
Highlight collaboration, knowledge sharing, constructive feedback, and psychological safety as important factors. Reference specific practices like code reviews, pair programming, or regular retrospectives that support healthy team dynamics. Align responses with the company’s stated cultural values learned through research.
- “How do you handle code reviews?”
Demonstrate openness to feedback and constructive approach to reviewing others’ code. Explain how code reviews are learning opportunities, describe techniques for delivering feedback tactfully, and share examples of incorporating reviewer suggestions to improve code quality. This reveals collaboration skills and ego management crucial for team success.
- “Tell me about a time you mentored someone.”
Highlight leadership potential through mentorship examples even without formal management experience. Describe the mentee’s initial state, teaching approach customized to their learning style, specific guidance provided, and measurable improvements in their performance or confidence. Mentorship ability indicates readiness for senior or lead roles.
- “How do you contribute to team knowledge sharing?”
Provide concrete examples: creating documentation, conducting brown bag sessions, contributing to internal wikis, or pair programming with teammates. Demonstrate commitment to collective team success beyond individual contributions. Knowledge sharing is essential in full stack roles spanning multiple technology domains.
Problem-Solving and Initiative Questions
- “Describe a time you identified and solved a problem proactively.”
Showcase initiative and ownership mentality by describing problems noticed before they became critical. Explain the business or technical risk identified, how stakeholders were convinced of the issue’s importance, the solution implemented independently or with team support, and the positive impact on system reliability or user experience. Proactive problem-solving distinguishes exceptional candidates.
- “How do you stay current with technology trends?”
Demonstrate commitment to continuous learning through specific habits: following tech blogs, contributing to open-source projects, attending meetups or conferences, completing online courses, or building side projects. Mention recent technologies learned and how they apply to professional growth. Continuous learning is crucial in the rapidly evolving full stack development landscape.
- “Tell me about a time you had to make a difficult technical decision.”
Illustrate decision-making process including gathering information, evaluating trade-offs, consulting stakeholders, and taking calculated risks. Explain the factors considered (performance vs. maintainability, cost vs. scalability, etc.) and how the decision was validated post-implementation. Good decision-making under uncertainty is a critical developer skill.
Handling Stress and Setbacks
- “Describe a time when a project didn’t go as planned.”
Show resilience and adaptability when facing adversity. Describe the unexpected challenge, initial impact assessment, contingency measures implemented, stakeholder communication throughout the crisis, and ultimate outcome or lessons learned. Recovery from setbacks reveals character and problem-solving under pressure.
- “How do you handle competing priorities from multiple stakeholders?”
Demonstrate prioritization frameworks used to evaluate urgency and business impact. Explain communication strategies for managing stakeholder expectations, negotiating deadlines, and maintaining transparency about capacity constraints. Effective stakeholder management is essential for full stack developers interfacing with product, design, and business teams.
- “Tell me about a time you worked long hours or weekends.”
Balance demonstrating dedication with healthy work-life boundaries. Explain the exceptional circumstances requiring extra effort, how the situation was temporary and justified, and any compensatory measures taken afterward. Avoid suggesting that constant overwork is expected or sustainable.
Questions to Ask Interviewers
- About the Role
Ask about day-to-day responsibilities, typical projects, technology stack evolution, and growth opportunities within the role. Inquire about team structure, collaboration patterns, and how success is measured in the position. Thoughtful questions demonstrate genuine interest and help assess role fit.
- About the Team
Ask about team size, composition, onboarding process, and professional development support. Inquire about team culture, communication norms, and how technical decisions are made collaboratively. Understanding team dynamics helps evaluate cultural alignment.
- About Technical Practices
Ask about development workflow, deployment frequency, testing practices, code review processes, and technical debt management. Inquire about opportunities to work across the full stack and learn new technologies. These questions reveal commitment to engineering excellence and continuous learning.
- About Company Direction
Ask about product roadmap, company growth trajectory, competitive positioning, and how the role contributes to strategic objectives. Inquire about challenges the company faces and how the team is addressing them. Strategic questions demonstrate big-picture thinking beyond individual technical work.
- About Next Steps
Ask about interview process timeline, next stages, and evaluation criteria. Inquire about feedback mechanisms if not selected and when to expect communication. Closing questions show proactive communication and genuine interest in the opportunity.
🎓 Go from Frontend to Full Stack!
Learn React + Django + Flask integration inside our Python Full Stack Developer Course.
4.Additional Preparation Elements

Python Full Stack Developer Interview Preparation Guide –
Additional Preparation Elements
Time Management Strategies
- Interview Time Allocation Framework
During a 45-60 minute coding interview, allocate time strategically: spend 5-7 minutes understanding the problem and clarifying requirements, 8-10 minutes planning the solution approach, 25-30 minutes implementing the code, and 12-15 minutes testing and debugging. This structured breakdown prevents rushing through implementation or running out of time before testing edge cases.
- Preparation Timeline Planning
For beginners with 0-1 years of experience, allocate 6-12 months focusing 2-4 hours daily on fundamentals including data structures, algorithms, and problem-solving. Intermediate programmers with 1-3 years of experience should dedicate 3-6 months with 1-3 hours daily for advanced topics like dynamic programming and system design. Experienced developers need 1-3 months with 1-2 hours daily for interview-specific practice and optimization techniques.
- Pomodoro Technique for Study Sessions
Use the Pomodoro technique to maintain focus during preparation by working in 25-minute intervals followed by 5-minute breaks, then taking longer 15-30 minute breaks after four cycles. This approach creates urgency, reduces distractions, and prevents burnout during intensive preparation periods. The structured intervals help maintain consistent practice without mental fatigue.
- Prioritization Matrix Application
Apply prioritization frameworks to manage multiple preparation topics by categorizing them as urgent/important, important/not urgent, urgent/not important, or neither. Focus on important but not urgent activities like algorithm mastery and system design fundamentals rather than reactive cramming. Break large preparation goals into smaller manageable tasks to maintain momentum and track progress effectively.
- Time-Saving Techniques During Interviews
Leverage built-in functions like array.sort() and IDE features such as auto-completion to save time on routine tasks. Focus first on achieving a working solution rather than optimizing prematurely, then refine if time permits. Familiarize yourself with common problem patterns to quickly recognize optimal approaches during interviews.
Whiteboard Interview Best Practices
- Whiteboard Interview Structure
Whiteboard coding interviews typically follow a 45-60 minute format: 5-10 minutes for problem presentation, 5 minutes for clarification questions, 10-15 minutes for solution design and pseudocode, 20-30 minutes for implementation, and 5-10 minutes for optimization and review. Understanding this structure helps allocate mental energy appropriately across interview stages.
- Communication and Thinking Aloud
Verbalize your thought process continuously throughout whiteboard interviews to help interviewers follow your reasoning and provide guidance when needed. Explain problem understanding, discuss potential approaches, justify chosen solutions, and articulate trade-offs being considered. This demonstrates structured thinking even if the final solution isn’t perfect.
- Space Management and Legibility
Write with readable font size considering interviewer distance, use all available whiteboard space efficiently, and plan layout before starting. Reserve the top-left corner for problem requirements and expected outputs, leaving the remaining space for solution sketches, pseudocode, and final implementation. Poor handwriting or cramped code reduces effectiveness of otherwise correct solutions.
- Clarification Before Coding
Ask clarifying questions before writing code to understand requirements, input/output formats, constraints, and edge cases. Questions should address ambiguities: “Should I optimize for time or space?”, “What are the input size constraints?”, “How should I handle invalid inputs?”. This demonstrates attention to detail and prevents solving the wrong problem.
- Iterative Solution Development
Start with a brute force approach to establish baseline understanding, then progressively optimize. Outline the solution in pseudocode or high-level steps before diving into detailed implementation. This approach demonstrates problem-solving methodology and provides recovery points if implementation gets complicated.
- Handling Mistakes Gracefully
When stuck or making mistakes, pause, take a breath, and verbalize the challenge: “Let me step back and reconsider this approach”. Welcome interviewer feedback and incorporate suggestions openly, showing collaboration skills valued in team environments. Errors in whiteboard interviews are expected; recovery demonstrates resilience and adaptability.
- Time Awareness Without Clock-Watching
Develop internal time sense through practice to gauge progress without constant clock-checking that increases anxiety. If running short on time, communicate the situation: “I’ll outline the remaining steps since we’re running low on time”. Interviewers appreciate candidates who manage time constraints transparently.
Take-Home Coding Assignment Excellence
- Understanding Requirements Thoroughly
Read assignment instructions 2-3 times and take detailed notes before starting. Identify core requirements versus “nice-to-have” features, focusing efforts on must-have functionality first. If critical details are unclear (frameworks, libraries, data sources), request clarification promptly rather than guessing.
- State Assumptions Clearly
Make reasonable assumptions for ambiguous aspects rather than over-asking questions, documenting them in code comments or README files. This demonstrates decision-making ability in uncertain contexts, a crucial developer skill. Explaining assumptions shows thoughtful analysis and communication capability valued by hiring teams.
- Code Quality and Best Practices
Write clean, well-documented code following language-specific style guides like PEP 8 for Python. Use meaningful variable names, proper indentation, consistent formatting, and include explanatory comments for complex logic. Apply design patterns appropriately, follow SOLID principles, and demonstrate understanding of separation of concerns.
- Testing and Documentation
Include comprehensive unit tests covering happy paths, edge cases, and error scenarios. Write a detailed README with setup instructions, dependencies, how to run the application and tests, design decisions, and assumptions made. Quality documentation differentiates candidates and demonstrates professional software development practices.
- Version Control Hygiene
Use Git with clear, descriptive commit messages showing logical progression of work. Structure commits to tell a story of development: initial setup, feature implementation, bug fixes, and optimizations. Clean Git history demonstrates organized thinking and professional workflow understanding.
- MVP First, Then Enhancement
Build a minimum viable product meeting core requirements before adding extra features. This ensures submission of working software even if time runs short and demonstrates prioritization skills. Once MVP is complete, add enhancements if time permits, documenting them as “additional features” in README.
- Performance and Optimization
Consider performance implications of implementation choices, using appropriate data structures and algorithms. Include time and space complexity analysis for critical functions in comments or documentation. If optimization opportunities exist but weren’t implemented due to time, mention them in documentation showing awareness of trade-offs.
- Code Review Tools Usage
Run linters, prettifies, and static analysis tools before submission to catch stylistic issues and potential bugs. These tools demonstrate attention to code quality and professional development practices. Automated checks help present polished submissions reflecting real-world development standards.
- Submission Timing Strategy
For multi-day assignments, aim to submit around 70% through the deadline rather than at the last minute. This provides buffer for unexpected issues and demonstrates time management skills. Early submission (if quality is high) can create positive impression of efficiency and confidence.
- Deployment and Live Demo
When possible, deploy the application to a hosting platform and provide a live URL in addition to source code. Live demonstrations are more impressive than code review alone and show end-to-end deployment capability. Include screenshots or screen recordings demonstrating functionality if deployment isn’t feasible.
Managing Interview Stress
- Pre-Interview Preparation Strategies
Prepare thoroughly by researching the company, reviewing your resume, and practicing common questions to build confidence. Plan the interview day carefully including route, timing, required documents, and contingencies for delays. Visualization techniques help by imagining successful interview performance and positive interactions beforehand.
- Physical Preparation
Get adequate sleep the night before, eat a nutritious breakfast, and stay hydrated to maintain energy and mental clarity. Exercise before the interview helps release nervous energy and produces endorphins that reduce anxiety. Physical preparation creates foundation for mental performance under pressure.
- The STOP Method
Use the STOP technique during interviews when anxiety rises: Stop and focus on your thoughts, Take deep breaths, Observe physical sensations and emotions non-judgmentally, Proceed with intentional actions incorporating observations. This mindfulness approach prevents anxiety spirals and maintains composure.
- Breathing and Pause Techniques
Focus on deep, even breathing throughout the interview to maintain calm and mental clarity. Pause before answering questions to collect thoughts and formulate coherent responses rather than rushing. Controlled breathing lowers heart rate and reduces physical symptoms of nervousness.
- Reframing Interview Mindset
View interviews as conversations rather than interrogations to reduce intimidation. Remember interviewers want candidates to succeed and are generally supportive rather than adversarial. Having prepared questions demonstrates genuine interest and creates more balanced power dynamic.
- Controlling Controllables
Focus energy on controllable factors like preparation, punctuality, and professional presentation rather than worrying about unknowns. Accept that nervousness is normal and even expected by interviewers who adjust their expectations accordingly. Most candidates don’t lose opportunities due to nervousness alone, but due to appearing disinterested or unprepared.
- Body Language Management
Maintain upright, engaged posture without slouching or perching on seat edge to project confidence. If hands shake, clench thigh muscles to calm tremors while keeping hands visible for natural gesturing. Positive body language influences both interviewer perception and personal emotional state through feedback loops.
- Building Confidence Through Preparation
Conduct mock interviews with peers or mentors to simulate real pressure and receive feedback. Practice explaining technical concepts clearly and concisely to non-technical friends. Repeated exposure to interview conditions reduces anxiety through familiarity and builds genuine competence-based confidence.
Post-Interview Follow-Up Etiquette
- Thank-You Email Timing
Send thank-you emails within 24 hours of the interview, ideally the same day while the conversation is fresh. Prompt follow-up demonstrates enthusiasm, professionalism, and strong communication skills valued by employers. Delayed follow-up may be interpreted as lack of interest in the opportunity.
- Email Structure and Content
Use a clear subject line like “Thank You – [Your Name] – [Position Title]” for easy identification. Express genuine gratitude for the interviewer’s time, reference specific discussion points that resonated, reiterate interest in the role, and offer to provide additional information if needed. Keep emails concise (under 200 words) and professional.
- Personalization and Specificity
Customize each thank-you email referencing unique aspects of conversations with different interviewers. Mention specific topics discussed, challenges mentioned, or insights shared that particularly interested you. Generic templates come across as insincere; personalization demonstrates attentiveness and genuine engagement.
- Reinforcing Fit and Value
Use follow-up emails to subtly reinforce your qualifications by connecting interview discussions to relevant experience. If you thought of a better answer post-interview, briefly mention it: “Reflecting on your question about X, I wanted to add…”. Avoid overselling or appearing desperate; maintain confident professionalism.
- Sample Thank-You Email Template
“Subject: Thank You – [Your Name] – Python Full Stack Developer Position
Dear [Interviewer’s Name],
Thank you for taking time to discuss the Python Full Stack Developer role at [Company] today. Our conversation about [specific project/challenge] was particularly insightful and reinforced my enthusiasm for contributing to your team.
I’m especially excited about [specific aspect of role/company discussed], and I’m confident my experience with [relevant skill/project] would enable me to make meaningful contributions immediately.
Please let me know if you need any additional information. I look forward to the next steps in your process.
Best regards,
[Your Name]
[LinkedIn URL]”
- Following Up on Pending Information
If you promised to send additional materials (portfolio links, code samples, references), include them in the thank-you email or separate follow-up within 24 hours. Meeting commitments made during interviews demonstrates reliability and follow-through. Organize materials professionally with clear labels and context.
- Handling Multiple Interviewers
Send individual thank-you emails to each interviewer rather than group messages, personalizing content based on your specific interaction with each person. If you can’t identify all interviewer emails, request them from the HR contact or send a general email asking HR to share your thanks. Individual emails show extra effort and attention to relationship-building.
- Timeline Inquiry Etiquette
If the interviewer didn’t mention next steps, politely ask about timeline in your thank-you email: “Could you share the expected timeline for next steps in your process?”. If a timeline was provided but deadline passes without communication, wait 2-3 business days after the expected date before sending a polite follow-up inquiry.
- Follow-Up After Rejection
If you receive a rejection, send a gracious response thanking them for the opportunity, expressing continued interest in future roles, and requesting feedback on areas for improvement. Professional handling of rejection maintains positive relationships for potential future opportunities. Many companies keep strong candidates in mind for other positions when handled well.
- Keeping Doors Open
Express interest in staying connected via LinkedIn and company updates even if this particular role doesn’t work out. Hiring managers appreciate candidates who view relationships beyond transactional interview outcomes. The tech industry is interconnected; professional grace can lead to unexpected opportunities later.
Final Interview Day Checklist
- Technical Setup for Virtual Interviews
Test camera, microphone, and internet connection 30 minutes before the interview. Ensure proper lighting with light source in front of you, professional background free of distractions, and backup devices ready if primary fails. Close unnecessary applications to prevent notifications or performance issues during coding exercises.
- Materials and Resources
Have copies of your resume, portfolio, list of references, and questions for interviewers readily accessible. For technical interviews, prepare notebook and pen for taking notes and working through problems. Keep water nearby to manage dry mouth from nervousness.
- Mental Preparation Routine
Review key technical concepts without cramming new material the night before. Practice positive self-talk: focus on preparation completed and strengths rather than dwelling on potential weaknesses. Arrive (physically or virtually) 10-15 minutes early to settle nerves and demonstrate punctuality.
- Contingency Planning
Identify backup plans for common issues: alternative route if traffic occurs, recruiter contact information if running late, backup device for virtual interviews. Having contingencies reduces anxiety about factors outside your control. Communicate proactively if unexpected issues arise rather than going silent.
- Post-Interview Reflection
After each interview, document questions asked, topics discussed, areas you handled well, and areas needing improvement. This reflection helps prepare for subsequent rounds and refine responses. Track interview experiences to identify patterns in your performance and adjust preparation accordingly.
🎯 You’re interview-ready — now become job-ready!
Join the Python Full Stack Developer Course in Telugu and build complete real-world apps from scratch with mentorship a