90-Day Machine Learning & Deep Learning Roadmap: From Beginner to Job-Ready
Table of Contents
This is a structured, day-by-day 90-day roadmap to become a job-ready Machine Learning Engineer — covering Python, Mathematics, NumPy, Pandas, Scikit-learn, Neural Networks, TensorFlow, Deep Learning, and Generative AI. Built on Frontlines Edutech’s proven ML & DL course curriculum, this plan is designed for students and freshers across India who want to break into one of the highest-paying tech fields — even with zero prior coding experience. India’s AI/ML job market grew 36% in 2025. ML engineers earn ₹7–25 LPA, and deep learning specialists average ₹29.7 LPA. By Day 90, you’ll have a project portfolio, a GitHub profile, and the interview confidence to crack roles at Infosys, TCS, Google, Flipkart, and fast-growing AI startups.
Explore ML Learning Resources →
Why Machine Learning Is the Best Career Bet for 2026
The global ML market is projected to grow from $113 billion in 2025 to $503 billion by 2030 — and India is right at the centre of that explosion. Here’s why now is the best time to start:
- ML/AI roles grew 36% in India entering 2025 — supply of trained engineers still lags far behind demand
- Hyderabad, Bangalore, Chennai, Pune, and Mumbai are leading the hiring wave across IT, fintech, healthtech, and e-commerce
- Unlike many tech roles, ML engineers are almost impossible to automate — you are the one building the AI
- Companies like Google, Microsoft, Amazon, Flipkart, Swiggy, Infosys, and TCS are all hiring — giving you both startup and enterprise options
The bottom line: 90 days of focused effort in ML gives you access to one of the most future-proof, well-compensated career tracks in Indian tech.
The 3-Month Learning Structure at a Glance
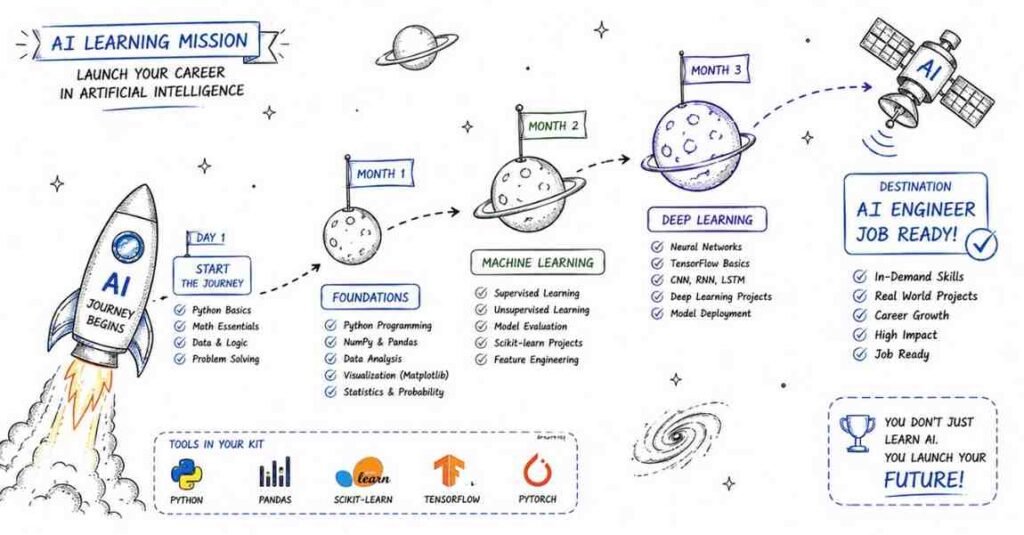
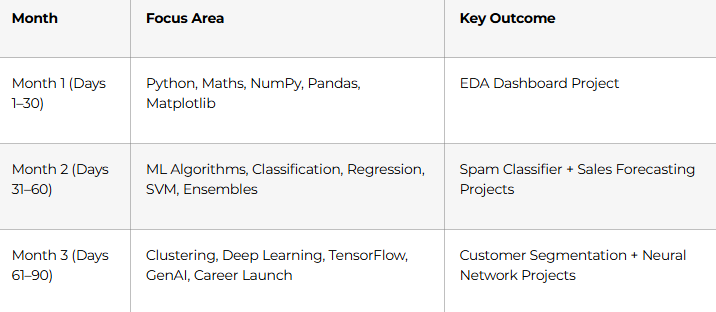
Month 1: Build Your Foundation (Days 1–30)
Strong ML foundations are not optional — they’re what separates candidates who get hired from those who get rejected after the first technical round. Give Month 1 your full focus.
Week 1–2: Python & Mathematics for Machine Learning (Days 1–14)
Days 1–3: Python Essentials
- Day 1 — Python installation, Jupyter Notebook/PyCharm setup, variables, data types, input/output
- Day 2 — Control flow (if/elif/else, for/while loops, break/continue), functions with parameters and return values
- Day 3 — Lists, tuples, dictionaries, sets — indexing, slicing, list comprehensions, dictionary operations
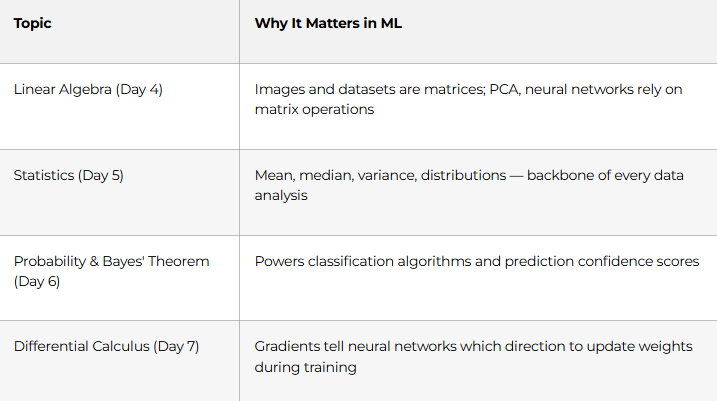
Days 4–7: Mathematics That Powers Every ML Algorithm
Don’t panic — you don’t need a maths degree. You need applied intuition:
Days 8–14: NumPy — The Engine Under Every ML Library
- Days 8–9 — Array creation, attributes, indexing, reshaping, transposing, broadcasting rules
- Day 10 — Universal functions: element-wise maths, trigonometry, exponential and log operations
- Days 11–12 — Array processing: sorting, filtering with boolean indexing, statistical operations, random number generation for data splitting
- Days 13–14 — NumPy projects: image manipulation with arrays, synthetic dataset creation, implementing ML operations from scratch
Week 3–4: Pandas, Data Cleaning & Visualisation (Days 15–30)
Days 15–21: Pandas — From Raw Data to Clean Data
- Day 15 — Series and DataFrames: creation from dicts, lists, NumPy arrays; head, tail, info, describe
- Day 16 — Reading data from CSV, Excel, JSON, SQL databases; handling encodings and missing value flags
- Day 17 — loc and iloc indexing, boolean filtering, column selection, chaining operations
- Day 18 — Handling missing values: isnull(), dropna(), forward fill, backward fill, mean/median imputation
- Day 19 — Remove duplicates, fix data types, standardise text, handle outliers with statistical methods
- Days 20–21 — Groupby aggregations, pivot/melt, merge/join datasets, apply() and map() for custom transformations
Days 22–28: Matplotlib & Data Visualisation
- Days 22–23 — Line plots, scatter plots, bar charts; customising titles, labels, legends, grids
- Day 24 — Histograms, box plots, heatmaps, correlation matrices, subplots
- Days 25–26 — Distribution plots, pair plots, time series visualisations for storytelling with data
- Days 27–28 — Mini Project: Full EDA Dashboard — load real dataset, clean it, run statistical analysis, produce 8–10 visualisations answering business questions
Days 29–30: Introduction to Machine Learning
- What ML is, how it differs from traditional programming, the end-to-end ML workflow
- Types: Supervised (classification, regression), Unsupervised (clustering), Reinforcement Learning — when to use which
🏆 Month 1 Milestone: You can load, clean, analyse, and visualise any real-world dataset. You’re ready to build ML models.
Explore the ML Career Guide →
Month 2: Core ML Algorithms (Days 31–60)
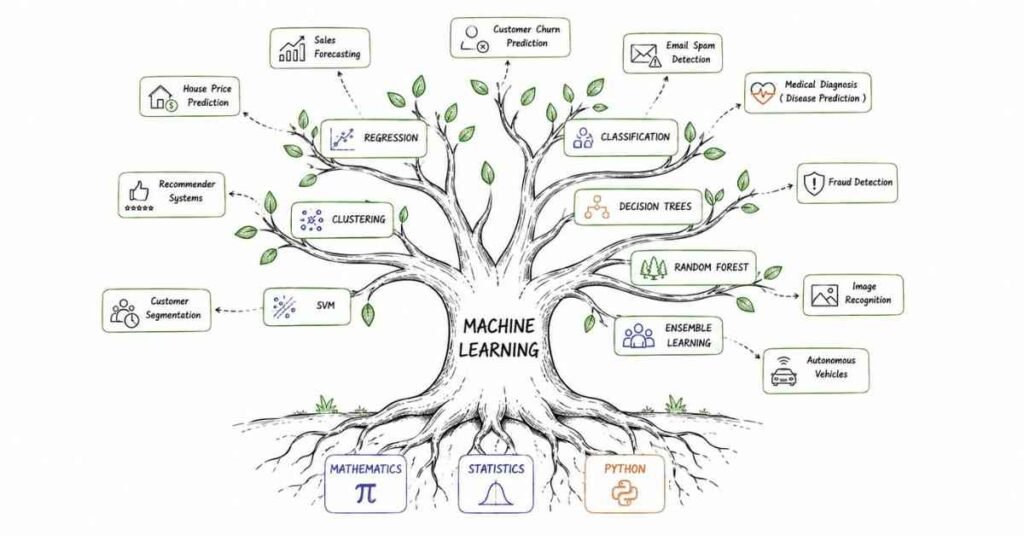
Month 2 is where theory becomes real. Every algorithm you learn here is tested in interviews and used in production systems at every company in your target list.
Week 5–6: End-to-End ML Workflow + Classification (Days 31–42)
Days 31–35: The Complete ML Project Workflow
- Day 31 — ML system types: batch vs. online learning, instance-based vs. model-based
- Day 32 — Problem definition, data collection, identifying target variables, assessing data quality
- Day 33 — Train/test splitting, cross-validation, feature scaling (normalisation vs. standardisation), encoding categorical variables
- Day 34 — Training process, loss functions, evaluation metrics, recognising overfitting vs. underfitting
- Day 35 — Project: House Price Prediction using Linear Regression — data exploration → cleaning → feature engineering → training → evaluation
Days 36–42: Classification Algorithms
- Days 36–37 — Logistic Regression: sigmoid function, decision boundaries, accuracy, precision, recall, F1-score
- Day 38 — Confusion matrix, ROC curves, AUC scores for model comparison
- Days 39–40 — Multi-class classification: one-vs-rest, one-vs-one, softmax activation, error analysis
- Day 41 — Multi-label and multi-output classification scenarios
- Day 42 — Project: Email Spam Classifier — text preprocessing, TF-IDF feature extraction, model training, hyperparameter tuning, evaluation
Week 7–8: Regression & Gradient-Based Learning (Days 43–49)
- Days 43–44 — Simple and multiple Linear Regression: OLS method, coefficient interpretation, R-squared, validating assumptions
- Day 45 — Gradient Descent: learning rate selection, convergence, batch vs. SGD vs. mini-batch
- Days 46–47 — Polynomial Regression for non-linear patterns; Ridge (L2), Lasso (L1) regularisation; early stopping
- Days 48–49 — Project: Sales Forecasting Model — datetime feature engineering, seasonality handling, model comparison, prediction intervals for business planning
Week 9–10: SVM, Decision Trees & Ensemble Methods (Days 50–60)
Week 8: Unsupervised Learning, Neural Networks & Month Review (Days 52–60)
Days 50–53: Support Vector Machines
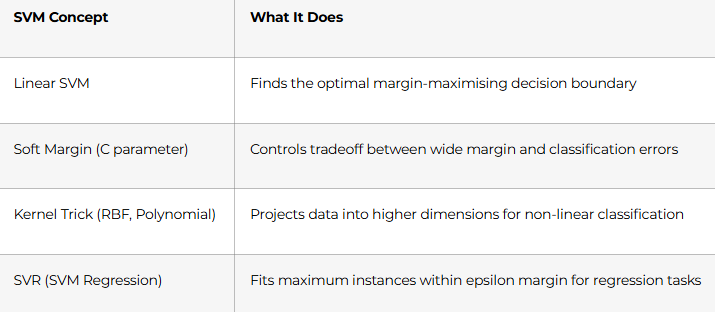
Days 54–60: Decision Trees, Random Forests & Boosting
- Days 54–55 — Decision trees: CART algorithm, visualisation, interpreting decision rules
- Day 56 — Gini impurity vs. entropy: when each is better and why
- Day 57 — Tree regularisation: max_depth, min_samples_split, pruning to prevent overfitting
- Days 58–59 — Random Forests: ensemble of trees on random feature/data subsets; out-of-bag evaluation; feature importance ranking
- Day 60 — Boosting Algorithms: AdaBoost (focuses on misclassified points) and Gradient Boosting (sequential error correction); stacking ensembles
🏆 Month 2 Milestone: You can build, evaluate, and compare classification and regression models from scratch. You are an ML practitioner.
Master ML Interviews Prep →
Month 3: Deep Learning, GenAI & Career Launch (Days 61–90)
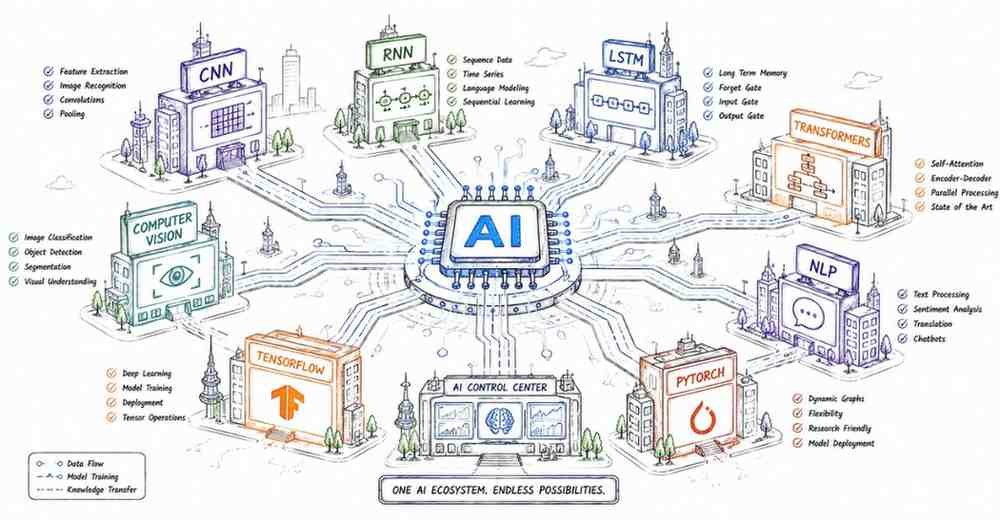
The final month adds neural networks, TensorFlow pipelines, Generative AI, and a complete career launch sprint. This is the content that puts your resume in a completely different league.
Week 11: Unsupervised Learning & Clustering (Days 61–67)
- Days 61–62 — K-Means clustering: centroid initialisation, iterative optimisation, elbow method, silhouette analysis for optimal K
- Day 63 — K-Means limitations: sensitivity to initialisation, poor performance on non-spherical clusters
- Day 64 — DBSCAN: density-based clustering that handles arbitrary shapes and detects outliers automatically
- Days 65–66 — Applications: customer segmentation, image compression, anomaly detection, semi-supervised learning
- Day 67 — Project: Customer Segmentation using RFM (Recency, Frequency, Monetary) features — multiple clustering algorithms, visualisations, actionable business insights
Week 12: Deep Learning with Keras (Days 68–74)
Neural networks are what every recruiter wants on your resume. This week makes that happen.
- Day 68 — Biological neurons → artificial neurons, perceptrons, activation functions
- Day 69 — Multi-Layer Perceptrons (MLPs): forward propagation, backpropagation, weight updates
- Day 70 — Keras Sequential API: stacking layers, compiling with loss functions and optimisers, training
- Day 71 — Regression MLPs (MSE loss, linear output) vs. Classification MLPs (softmax, categorical crossentropy)
- Day 72 — Keras Functional API: multiple inputs/outputs, shared layers, skip connections
- Day 73 — Callbacks: early stopping, model checkpointing, learning rate scheduling, saving/restoring models
- Day 74 — Hyperparameter tuning: layers, neurons, learning rate, batch size, epochs — grid search and random search
Week 13: Advanced Deep Learning & TensorFlow (Days 75–87)
Days 75–80: Training Deep Networks Like a Pro

Days 81–84: TensorFlow Data Pipeline
- Day 81 — TensorFlow tensors, eager execution vs. graph mode for production deployment
- Days 82–83 — tf.data.Dataset API: chaining transforms, shuffling, batching, prefetching, parallel loading for large datasets
- Day 84 — Feature preprocessing layers: scaling, one-hot encoding, embeddings, text preprocessing — baked directly into the model
Days 85–87: Generative AI Overview
- Day 85 — Generative vs. discriminative models; GenAI applications across text, image, and code generation
- Day 86 — Transformer architecture, LLMs (GPT, BERT, LLaMA), attention mechanisms explained clearly
- Day 87 — RAG (Retrieval-Augmented Generation), text embeddings, vector stores, prompt engineering techniques
Week 14: Career Launch Sprint (Days 88–90)
Day 88: GitHub Portfolio + LinkedIn Optimisation
Your GitHub IS your technical resume. Build 4–5 polished projects covering:
- Classification (Spam Detector, Churn Prediction)
- Regression (House/Sales Forecasting)
- Clustering (Customer Segmentation)
- Deep Learning (Image Classifier or Sentiment Analyser)
- Capstone combining multiple techniques
Every repo needs: a clear README, Jupyter notebooks with markdown walkthrough, clean PEP 8 code, result visualisations, and at least one Streamlit/Flask deployment for live demo.
LinkedIn Headline: “Machine Learning Engineer | Python | TensorFlow | Deep Learning | Open to Opportunities in Hyderabad”
Day 89: Job Search Strategy
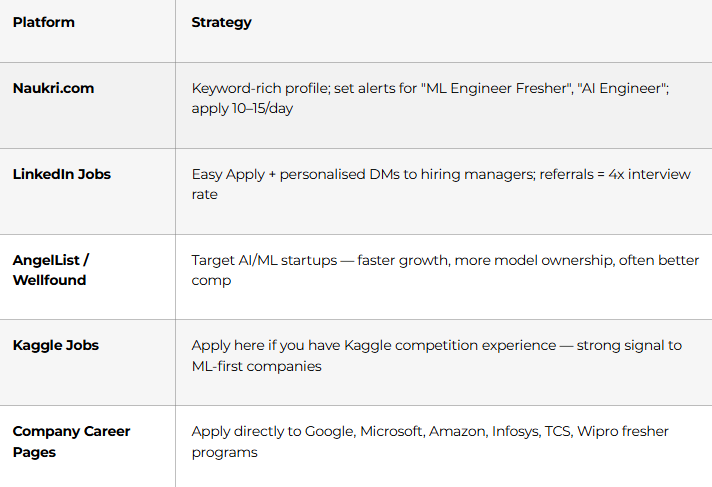
Also target “Data Analyst” and “AI Engineer” JDs — many accept ML-trained freshers.
Day 90: Interview Mastery
Prepare for all four ML interview rounds:
- Coding Round — Python arrays, strings, dicts on LeetCode Easy; implement linear regression and K-Means from scratch without libraries
- ML Theory — Bias-variance tradeoff, overfitting prevention, cross-validation, L1 vs. L2, backpropagation, class imbalance handling
- Case Study — “Design a fraud detection model for a bank” or “Build a recommendation engine for Flipkart” — structure: data → features → model → metrics → deployment
- Behavioural — STAR stories about debugging a failing model, learning a new framework, collaborating on a team project
🏆 Day 90 Milestone: Portfolio live. Resume submitted. Interview-ready. ML career begins.
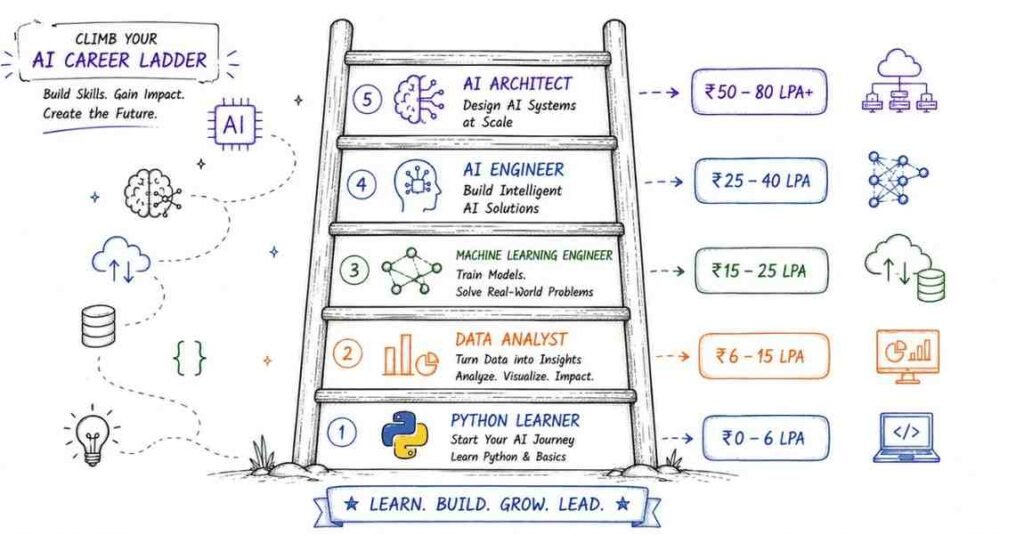
ML & Deep Learning Career Paths & Salary Guide (India 2026)
Role | Experience | Salary Range | Core Skills |
ML Engineer (Fresher) | 0–1 years | ₹6–10 LPA | Python, Scikit-learn, SQL, Git |
Data Scientist | 0–2 years | ₹7–14 LPA | ML algorithms, Statistics, EDA |
AI Engineer | 1–3 years | ₹10–20 LPA | TensorFlow, Keras, NLP, APIs |
Deep Learning Engineer | 2–5 years | ₹15–30 LPA | CNNs, RNNs, Transformers |
Senior ML Engineer | 4–7 years | ₹25–45 LPA | System design, model production |
Deep Learning Specialist | 5+ years | ₹30–50 LPA | Research-level model building |
Top hiring cities: Hyderabad, Bangalore, Chennai, Pune, Mumbai, Gurgaon, Noida
Top hiring companies: Google, Microsoft, Amazon, Meta, Infosys, TCS, Wipro, Accenture, Cognizant, Capgemini, Flipkart, Swiggy, Zomato, PhonePe, and hundreds of AI-native startups
Why Choose Frontlines Edutech?
Frontlines Edutech is headquartered in Somajiguda, Hyderabad and has transformed thousands of learners across the Telugu states into ML professionals — including freshers, non-IT graduates, and working professionals switching careers.
- Expert mentors from leading tech companies — real industry experience, not just teaching certifications
- Hands-on projects aligned to what companies actually test in interviews
- Telugu-friendly delivery — complex concepts like backpropagation and gradient descent explained so they actually click
- Career support that doesn’t stop — resume, LinkedIn, mock interviews, placement updates until you land the role
- Affordable fees — comprehensive training at a fraction of what other institutes charge
- Lifetime access to recordings, code repositories, cheat sheets, and the alumni community
Frequently Asked Questions (FAQs)
Q1.Do I need a mathematics or programming background to start this ML roadmap?
A.No. The roadmap starts from Python basics and applied mathematics on Day 1. Non-IT students and arts/commerce graduates have successfully completed this course. The focus is on practical intuition, not theoretical proofs.
Q2.How long does it take to complete this Machine Learning & Deep Learning roadmap?
A.The roadmap is structured for 90 days with 3–4 hours of daily study and practice. Students with prior Python experience may move faster. Working professionals can follow weekend batches and complete it in 120 days.
Q3.What is the salary for a Machine Learning Engineer fresher in India?
A.Entry-level ML engineers in India earn ₹6–10 LPA. Deep learning specialists with strong portfolios can start at ₹12–15 LPA. Hyderabad and Bangalore offer the most competitive fresher packages in the ML space.
Q4.What Python libraries will I learn in this Machine Learning course?
A.You’ll master NumPy and Pandas (data manipulation), Matplotlib (visualisation), Scikit-learn (ML algorithms), TensorFlow and Keras (deep learning), and get an introduction to Hugging Face Transformers for Generative AI.
Q5.Is Deep Learning covered separately or as part of this ML roadmap?
A.Deep Learning is fully integrated into Month 3 of this roadmap (Days 68–84), covering Artificial Neural Networks, Keras Sequential and Functional APIs, advanced training techniques, batch normalisation, dropout, transfer learning, and TensorFlow data pipelines.
Q6.What real-world projects will I build in this Machine Learning course?
A.Key projects include: House Price Prediction (linear regression), Email Spam Classifier (text classification), Sales Forecasting Model (time series regression), Customer Segmentation (clustering with RFM), and a Deep Learning image classifier — all portfolio-ready with GitHub documentation.
Q7.Does Frontlines Edutech provide placement support after the ML course?
A.Yes. Placement support includes resume building, LinkedIn optimisation, mock technical interviews, and active job referrals from a network of 200+ partner companies. The team supports you until you land your first ML/AI role.
Q8.What is the difference between Machine Learning and Deep Learning?
A.Machine Learning uses statistical algorithms (regression, decision trees, SVMs) to find patterns in structured data. Deep Learning uses neural networks with multiple layers to learn from unstructured data like images, audio, and text — and typically requires more data and compute power.
Published by Frontlines Edutech | blog.frontlinesedutech.com
support@frontlinesedutech.com