How to Become a Data Scientist with Gen AI: Complete Career Guide [₹16L Average Salary]
Master the future of AI and drive business transformation through intelligent data solutions
Data Scientists specializing in Generative AI are at the forefront of the most revolutionary technology transformation of our time, with average salaries ranging from ₹8-25 LPA in India and senior GenAI specialists earning ₹45+ LPA. As organizations rush to implement AI-driven solutions and Large Language Models (LLMs) reshape entire industries, the ability to develop, deploy, and optimize generative AI systems has become one of the most valuable and future-critical skills in technology.
Whether you’re a data analyst seeking to advance into AI development, a software engineer looking to specialize in machine learning, or a professional seeking to lead AI transformation initiatives, this comprehensive guide provides the proven roadmap to building a successful Data Science with GenAI career. Having trained over 180 GenAI professionals at Frontlines EduTech with a 94% job placement rate, I’ll share the strategies that consistently deliver results in this rapidly expanding, high-impact field.
What you’ll master in this guide:
- Complete GenAI learning pathway from machine learning fundamentals to advanced LLM development
- Essential AI frameworks including transformers, diffusion models, and multimodal AI systems
- Portfolio projects demonstrating real business applications and AI model deployment
- Cutting-edge techniques in prompt engineering, fine-tuning, and responsible AI development
- Career opportunities in AI research, product development, and strategic consulting
🚀 Kickstart Your GenAI Career — Explore All Learning Resources →
1. What is Data Science with GenAI ?
Data Science with Generative AI involves developing, implementing, and optimizing AI systems that can create new content, solve complex problems, and augment human intelligence across diverse domains. This cutting-edge field combines traditional data science methodologies with advanced generative models, large language models, computer vision, and multimodal AI to create intelligent applications that transform how organizations operate and deliver value.
Core Components of GenAI Data Science:
Large Language Models and Natural Language Processing:
- LLM Development – Training, fine-tuning, and optimizing transformer-based models for specific use cases
- Prompt Engineering – Advanced prompt design, few-shot learning, chain-of-thought reasoning, prompt optimization
- Natural Language Understanding – Sentiment analysis, entity recognition, text classification, semantic search
- Text Generation – Content creation, code generation, technical writing, creative applications
Computer Vision and Multimodal AI:
- Generative Computer Vision – Diffusion models, GANs, image synthesis, style transfer, image editing
- Multimodal Models – Vision-language models, image captioning, visual question answering, cross-modal retrieval
- Video Generation – Text-to-video, video editing, motion synthesis, temporal consistency
- 3D and Spatial AI – 3D scene generation, neural radiance fields, spatial understanding
AI System Architecture and MLOps:
- Model Deployment – Cloud deployment, API development, model serving, scaling strategies
- MLOps for GenAI – Model versioning, monitoring, A/B testing, continuous training, pipeline automation
- Vector Databases – Embedding storage, similarity search, retrieval-augmented generation (RAG)
- AI Safety and Alignment – Responsible AI practices, bias detection, safety protocols, ethical guidelines
Business Applications and Strategy:
- AI Product Development – User experience design, product strategy, market analysis, competitive intelligence
- AI Consulting – Enterprise AI strategy, transformation roadmaps, ROI analysis, change management
- Industry Solutions – Healthcare AI, financial AI, legal AI, educational AI, creative AI applications
- Research and Innovation – Cutting-edge research, publication, patent development, thought leadership
Traditional Data Science vs GenAI Data Science
Traditional Data Science Focus:
- Predictive analytics, statistical modeling, business intelligence
- Structured data analysis, dashboard creation, reporting
- Classical machine learning algorithms, feature engineering
- Historical data analysis and trend identification
GenAI Data Science Advantages:
- Creative content generation, complex problem-solving, human-AI collaboration
- Unstructured data processing, multimodal analysis, natural language interfaces
- Advanced neural architectures, transfer learning, foundation model adaptation
- Real-time intelligent applications, conversational AI, automated decision-making
🎓 Want to Build a High-Demand AI Career? Join Our GenAI Course! →
2. Why Choose GenAI ?
Revolutionary Impact and Market Explosion
According to PwC’s AI Analysis 2025, AI could contribute up to $15.7 trillion to the global economy by 2030. In India specifically, GenAI adoption has accelerated dramatically across all sectors:
Enterprise GenAI Transformation:
- Technology Companies – Google, Microsoft, Amazon, Meta investing billions in AI research and product development
- Financial Services – JPMorgan, Goldman Sachs using AI for algorithmic trading, risk assessment, fraud detection
- Healthcare and Life Sciences – Drug discovery, medical imaging, personalized treatment, clinical decision support
- Retail and E-commerce – Personalized recommendations, dynamic pricing, customer service automation, inventory optimization
Emerging GenAI Applications:
- Content Creation – Automated writing, video production, graphic design, marketing content generation
- Software Development – Code generation, automated testing, documentation, debugging assistance
- Scientific Research – Protein folding, climate modeling, materials discovery, pharmaceutical research
- Creative Industries – Music composition, art generation, game development, entertainment production
Exceptional Compensation and Career Opportunities
GenAI specialists command premium salaries due to scarcity and strategic value:

Source: AI Jobs India 2025, Glassdoor AI Salaries
First-Mover Advantage in Emerging Field
GenAI offers exceptional career advantages for early adopters:
- Limited Competition – Few professionals with deep GenAI expertise creating high demand
- Exponential Growth – Rapid market expansion creating abundant opportunities
- Cross-Industry Application – GenAI skills applicable across all business sectors
- Innovation Leadership – Opportunity to shape the future of AI and business transformation
Global Remote Opportunities and Entrepreneurial Potential
GenAI skills enable diverse career paths:
- Remote-First Industry – Global opportunities with leading AI companies and startups
- Consulting Potential – High-value consulting opportunities helping organizations adopt AI
- Startup Creation – Technical skills to build AI-powered products and services
- Research Opportunities – Academic and industrial research positions with global impact
🗺️ See the Complete Data Scientist Roadmap →
3. Complete Learning Roadmap (5-7 Months)
Phase 1: Machine Learning and Deep Learning Foundation (Month 1-2)
Mathematics and Statistics Fundamentals (2-3 weeks)
Solid mathematical foundation is crucial for understanding GenAI models:
- Linear Algebra – Vector operations, matrix multiplication, eigenvalues, singular value decomposition
- Calculus and Optimization – Gradients, chain rule, optimization algorithms, backpropagation
- Probability and Statistics – Bayesian inference, maximum likelihood, statistical distributions
- Information Theory – Entropy, mutual information, KL divergence, cross-entropy loss
Machine Learning Fundamentals (3-4 weeks)
- Supervised Learning – Regression, classification, model evaluation, cross-validation
- Unsupervised Learning – Clustering, dimensionality reduction, anomaly detection
- Deep Learning Basics – Neural networks, activation functions, optimization, regularization
- ML Engineering – Data preprocessing, feature engineering, model selection, hyperparameter tuning
Deep Learning Architecture (2-3 weeks)
- Convolutional Neural Networks – Image processing, computer vision, feature extraction
- Recurrent Neural Networks – Sequential data, LSTM, GRU, time series modeling
- Attention Mechanisms – Attention weights, self-attention, multi-head attention
- Transfer Learning – Pre-trained models, fine-tuning, feature extraction
Foundation Projects:
- Image Classification System – CNN implementation with transfer learning for business application
- Text Sentiment Analysis – RNN-based model for customer feedback analysis
- Time Series Forecasting – LSTM model for sales or stock price prediction
Phase 2: Transformer Architecture and Language Models (Month 2-3)
Transformer Architecture Deep Dive (3-4 weeks)
- Attention Mechanism – Self-attention, multi-head attention, positional encoding, attention visualization
- Encoder-Decoder Architecture – Transformer blocks, layer normalization, residual connections
- BERT and Variants – Bidirectional encoding, masked language modeling, next sentence prediction
- GPT Architecture – Autoregressive generation, causal attention, scaling laws, emergent properties
Large Language Model Development (3-4 weeks)
Understanding Pre-trained Models:
from transformers import GPT2LMHeadModel, GPT2Tokenizer, Trainer, TrainingArguments
from datasets import Dataset
import torch
from torch.utils.data import DataLoader
class AdvancedLLMTrainer:
def __init__(self, model_name=”gpt2″, max_length=512):
self.tokenizer = GPT2Tokenizer.from_pretrained(model_name)
self.model = GPT2LMHeadModel.from_pretrained(model_name)
self.max_length = max_length
# Add padding token if not exists
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
def prepare_dataset(self, texts, domain=”general”):
“””Prepare dataset for domain-specific fine-tuning”””
# Tokenize texts with appropriate formatting
def tokenize_function(examples):
# Add special tokens for different domains
if domain == “code”:
formatted_texts = [f”<|startofcode|>{text}<|endofcode|>” for text in examples[“text”]]
elif domain == “business”:
formatted_texts = [f”<|business|>{text}<|endbusiness|>” for text in examples[“text”]]
else:
formatted_texts = examples[“text”]
return self.tokenizer(
formatted_texts,
truncation=True,
padding=True,
max_length=self.max_length,
return_tensors=”pt”
)
dataset = Dataset.from_dict({“text”: texts})
tokenized_dataset = dataset.map(tokenize_function, batched=True)
return tokenized_dataset
def fine_tune_model(self, train_dataset, eval_dataset=None, output_dir=”./fine_tuned_model”):
“””Fine-tune model on domain-specific data”””
training_args = TrainingArguments(
output_dir=output_dir,
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=8,
warmup_steps=100,
logging_steps=50,
save_steps=500,
evaluation_strategy=”steps” if eval_dataset else “no”,
eval_steps=500 if eval_dataset else None,
learning_rate=5e-5,
weight_decay=0.01,
adam_epsilon=1e-8,
max_grad_norm=1.0,
fp16=torch.cuda.is_available(),
dataloader_pin_memory=True,
load_best_model_at_end=True if eval_dataset else False,
)
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=self.tokenizer,
data_collator=self._data_collator,
)
trainer.train()
trainer.save_model()
return trainer
def _data_collator(self, features):
“””Custom data collator for language modeling”””
batch = self.tokenizer.pad(
features,
padding=True,
return_tensors=”pt”,
)
# Labels are the same as input_ids for language modeling
batch[“labels”] = batch[“input_ids”].clone()
return batch
def generate_text(self, prompt, max_new_tokens=100, temperature=0.7, top_p=0.9):
“””Generate text using the fine-tuned model”””
self.model.eval()
input_ids = self.tokenizer.encode(prompt, return_tensors=”pt”)
with torch.no_grad():
output = self.model.generate(
input_ids,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=top_p,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
attention_mask=torch.ones(input_ids.shape, dtype=torch.long)
)
generated_text = self.tokenizer.decode(output[0], skip_special_tokens=True)
return generated_text[len(prompt):] # Return only the generated part
# Advanced prompt engineering techniques
class PromptEngineeringToolkit:
def __init__(self, model_name=”gpt-3.5-turbo”):
self.model_name = model_name
self.conversation_history = []
def few_shot_learning(self, task_description, examples, new_input):
“””Implement few-shot learning with carefully crafted examples”””
prompt = f”{task_description}\n\n”
# Add examples
for i, (input_ex, output_ex) in enumerate(examples, 1):
prompt += f”Example {i}:\nInput: {input_ex}\nOutput: {output_ex}\n\n”
# Add new input
prompt += f”Now solve this:\nInput: {new_input}\nOutput:”
return prompt
def chain_of_thought_prompting(self, problem, reasoning_steps=True):
“””Implement chain-of-thought reasoning for complex problems”””
if reasoning_steps:
prompt = f”””
Let’s solve this step by step.
Problem: {problem}
Step 1: First, let me understand what is being asked.
Step 2: I’ll identify the key information and constraints.
Step 3: I’ll work through the solution methodically.
Step 4: I’ll verify my answer makes sense.
Let me work through this:
“””
else:
prompt = f”Problem: {problem}\n\nSolution:”
return prompt
def role_based_prompting(self, role, task, context=””):
“””Create role-based prompts for specialized expertise”””
role_definitions = {
“data_scientist”: “You are an expert data scientist with 10+ years of experience in machine learning and statistical analysis.”,
“business_analyst”: “You are a senior business analyst who excels at translating data insights into actionable business recommendations.”,
“software_engineer”: “You are a senior software engineer with expertise in system design and clean code principles.”,
“financial_advisor”: “You are a certified financial advisor with deep knowledge of investment strategies and risk management.”
}
system_prompt = role_definitions.get(role, f”You are an expert {role}”)
prompt = f”{system_prompt}\n\n”
if context:
prompt += f”Context: {context}\n\n”
prompt += f”Task: {task}”
return prompt
def multi_step_reasoning(self, complex_problem, decompose=True):
“””Break down complex problems into manageable steps”””
if decompose:
prompt = f”””
I need to solve a complex problem. Let me break it down:
Main Problem: {complex_problem}
Let me decompose this into smaller, manageable parts:
1. What are the key components of this problem?
2. What information do I need to gather?
3. What are the logical steps to solve each component?
4. How do I combine the solutions?
Let me work through each step:
“””
else:
prompt = f”Complex Problem: {complex_problem}\n\nSolution:”
return prompt
# Usage example
def demonstrate_llm_capabilities():
# Initialize LLM trainer
trainer = AdvancedLLMTrainer()
# Sample domain-specific texts for fine-tuning
business_texts = [
“Our quarterly revenue increased by 15% due to improved customer retention strategies.”,
“Market analysis shows growing demand for sustainable products in the consumer electronics sector.”,
“The new pricing model resulted in a 23% improvement in profit margins while maintaining customer satisfaction.”
]
# Prepare dataset and fine-tune
train_dataset = trainer.prepare_dataset(business_texts, domain=”business”)
# Initialize prompt engineering
prompt_engineer = PromptEngineeringToolkit()
# Few-shot learning example
examples = [
(“The company’s stock price rose 5%”, “Positive financial news”),
(“Sales declined by 10% this quarter”, “Negative financial news”)
]
few_shot_prompt = prompt_engineer.few_shot_learning(
“Classify financial news sentiment:”,
examples,
“Revenue exceeded expectations by 8%”
)
return few_shot_prompt
Natural Language Processing Advanced Topics (2-3 weeks)
- Text Embeddings – Word2Vec, GloVe, BERT embeddings, sentence transformers
- Retrieval-Augmented Generation – Vector databases, semantic search, knowledge integration
- Multi-task Learning – Joint training, task-specific heads, parameter sharing
- Evaluation Metrics – BLEU, ROUGE, BERTScore, human evaluation, perplexity
LLM Projects:
- Domain-Specific Chatbot – Fine-tuned language model for customer service or technical support
- Code Generation Assistant – AI model for automated code completion and generation
- Content Creation Tool – Multi-purpose text generation for marketing and creative writing
Phase 3: Computer Vision and Multimodal AI (Month 3-4)
Generative Computer Vision (4-5 weeks)
- Generative Adversarial Networks (GANs) – Generator-discriminator architecture, training dynamics, loss functions
- Diffusion Models – Denoising diffusion, stable diffusion, image-to-image translation
- Variational Autoencoders – Latent space representation, generative modeling, disentangled representations
- Neural Style Transfer – Content-style separation, artistic generation, real-time applications
Multimodal AI Systems (3-4 weeks)
Vision-Language Models:
import torch
import torch.nn as nn
from transformers import CLIPModel, CLIPProcessor
from diffusers import StableDiffusionPipeline
import cv2
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
class MultimodalAISystem:
def __init__(self):
# Initialize CLIP for vision-language understanding
self.clip_model = CLIPModel.from_pretrained(“openai/clip-vit-base-patch32”)
self.clip_processor = CLIPProcessor.from_pretrained(“openai/clip-vit-base-patch32”)
# Initialize Stable Diffusion for image generation
self.diffusion_pipeline = StableDiffusionPipeline.from_pretrained(
“runwayml/stable-diffusion-v1-5”,
torch_dtype=torch.float16
)
# Move to GPU if available
if torch.cuda.is_available():
self.clip_model = self.clip_model.cuda()
self.diffusion_pipeline = self.diffusion_pipeline.to(“cuda”)
def image_text_similarity(self, images, texts):
“””Calculate similarity between images and text descriptions”””
# Process inputs
inputs = self.clip_processor(
text=texts,
images=images,
return_tensors=”pt”,
padding=True
)
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
# Get embeddings
with torch.no_grad():
outputs = self.clip_model(inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
return probs.cpu().numpy()
def generate_image_from_text(self, prompt, negative_prompt=””,
num_inference_steps=50, guidance_scale=7.5):
“””Generate image from text description using Stable Diffusion”””
with torch.autocast(“cuda”):
image = self.diffusion_pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
height=512,
width=512
).images[0]
return image
def image_captioning(self, image, candidate_captions):
“””Generate captions for images using CLIP”””
similarities = self.image_text_similarity([image], candidate_captions)
best_caption_idx = np.argmax(similarities[0])
return candidate_captions[best_caption_idx], similarities[0][best_caption_idx]
def visual_question_answering(self, image, question, possible_answers):
“””Answer questions about images”””
# Format questions with possible answers
formatted_answers = [f”The answer to ‘{question}’ is {answer}” for answer in possible_answers]
similarities = self.image_text_similarity([image], formatted_answers)
best_answer_idx = np.argmax(similarities[0])
return possible_answers[best_answer_idx], similarities[0][best_answer_idx]
def content_based_image_search(self, query_text, image_database):
“””Search images based on text queries”””
similarities = self.image_text_similarity(image_database, [query_text])
# Rank images by similarity
ranked_indices = np.argsort(similarities.flatten())[::-1]
ranked_similarities = similarities.flatten()[ranked_indices]
return ranked_indices, ranked_similarities
def style_transfer_generation(self, content_description, style_description):
“””Generate images combining content and style descriptions”””
combined_prompt = f”{content_description} in the style of {style_description}”
return self.generate_image_from_text(combined_prompt)
class AdvancedImageProcessor:
def __init__(self):
self.models = {}
def super_resolution(self, low_res_image, scale_factor=4):
“””Enhance image resolution using AI”””
# Implement super-resolution using ESRGAN or similar
# This is a simplified version
height, width = low_res_image.shape[:2]
enhanced_image = cv2.resize(
low_res_image,
(width * scale_factor, height * scale_factor),
interpolation=cv2.INTER_CUBIC
)
return enhanced_image
def image_inpainting(self, image, mask, prompt=””):
“””Fill missing or masked regions in images”””
# Use stable diffusion inpainting pipeline
inpaint_pipeline = StableDiffusionPipeline.from_pretrained(
“runwayml/stable-diffusion-inpainting”
)
# Convert to PIL format
pil_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
pil_mask = Image.fromarray(mask)
result = inpaint_pipeline(
prompt=prompt,
image=pil_image,
mask_image=pil_mask
).images[0]
return np.array(result)
def object_removal(self, image, object_mask):
“””Remove objects from images intelligently”””
return self.image_inpainting(image, object_mask, prompt=”clean background”)
def artistic_style_transfer(self, content_image, style_image):
“””Transfer artistic style between images”””
# Implement neural style transfer
# This would use a pre-trained style transfer model
pass
# Usage example
def demonstrate_multimodal_capabilities():
# Initialize multimodal system
multimodal_ai = MultimodalAISystem()
# Sample usage scenarios
# 1. Image generation from text
generated_image = multimodal_ai.generate_image_from_text(
“A futuristic cityscape at sunset with flying cars”,
negative_prompt=”low quality, blurry”
)
# 2. Visual question answering
sample_image = Image.open(“sample_image.jpg”)
answer, confidence = multimodal_ai.visual_question_answering(
sample_image,
“What is the main object in this image?”,
[“car”, “building”, “person”, “tree”]
)
# 3. Content-based search
search_results, similarities = multimodal_ai.content_based_image_search(
“sunset over mountains”,
[sample_image] # Would be a database of images
)
return generated_image, answer, confidence
3D and Spatial AI (2-3 weeks)
- Neural Radiance Fields (NeRF) – 3D scene reconstruction, novel view synthesis
- 3D Object Generation – Point clouds, mesh generation, volumetric representation
- Spatial Understanding – Depth estimation, 3D object detection, scene understanding
- AR/VR Applications – Augmented reality, virtual reality, mixed reality applications
Computer Vision Projects:
- AI Art Generation Platform – Web application for creating and editing images with AI
- Visual Search Engine – Multimodal search system combining images and text
- 3D Content Creation Tool – NeRF-based system for 3D model generation from photos
Phase 4: MLOps and Production AI Systems (Month 4-5)
AI System Architecture and Deployment (4-5 weeks)
- Model Serving – REST APIs, gRPC, model optimization, batch vs. real-time inference
- Scalable Infrastructure – Containerization, Kubernetes, auto-scaling, load balancing
- Vector Databases – Pinecone, Weaviate, Chroma for embedding storage and retrieval
- Model Monitoring – Performance tracking, drift detection, A/B testing, feedback loops
MLOps for Generative AI (3-4 weeks)
Production AI Pipeline:
import mlflow
import wandb
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import torch
from transformers import pipeline
import redis
import json
from typing import List, Dict, Optional
import asyncio
import uvicorn
class GenAIProductionSystem:
def __init__(self):
self.app = FastAPI(title=”GenAI Production API”)
self.models = {}
self.cache = redis.Redis(host=’localhost’, port=6379, db=0)
self.setup_monitoring()
self.setup_routes()
def setup_monitoring(self):
“””Initialize monitoring and logging”””
# MLflow for experiment tracking
mlflow.set_tracking_uri(“http://localhost:5000”)
mlflow.set_experiment(“genai_production”)
# Wandb for real-time monitoring
wandb.init(project=”genai-production”, job_type=”inference”)
def load_models(self):
“””Load and cache AI models”””
# Load text generation model
self.models[‘text_generator’] = pipeline(
“text-generation”,
model=”gpt2″,
tokenizer=”gpt2″,
device=0 if torch.cuda.is_available() else -1
)
# Load image generation model
from diffusers import StableDiffusionPipeline
self.models[‘image_generator’] = StableDiffusionPipeline.from_pretrained(
“runwayml/stable-diffusion-v1-5”,
torch_dtype=torch.float16
)
if torch.cuda.is_available():
self.models[‘image_generator’] = self.models[‘image_generator’].to(“cuda”)
def setup_routes(self):
“””Setup API routes”””
@self.app.post(“/generate/text”)
async def generate_text(request: TextGenerationRequest):
“””Generate text using fine-tuned language model”””
try:
# Check cache first
cache_key = f”text:{hash(request.prompt)}”
cached_result = self.cache.get(cache_key)
if cached_result:
wandb.log({“cache_hit”: 1})
return json.loads(cached_result)
# Generate text
with mlflow.start_run():
result = self.models[‘text_generator’](
request.prompt,
max_length=request.max_length,
temperature=request.temperature,
do_sample=True,
num_return_sequences=1
)
response = {
“generated_text”: result[0][‘generated_text’],
“model_version”: “v1.0”,
“inference_time”: 0.5 # Would measure actual time
}
# Cache result
self.cache.setex(cache_key, 3600, json.dumps(response))
# Log metrics
mlflow.log_metric(“inference_time”, response[“inference_time”])
wandb.log({“inference_time”: response[“inference_time”]})
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@self.app.post(“/generate/image”)
async def generate_image(request: ImageGenerationRequest):
“””Generate image from text prompt”””
try:
cache_key = f”image:{hash(request.prompt)}”
# Generate image
with mlflow.start_run():
image = self.models[‘image_generator’](
request.prompt,
num_inference_steps=request.num_steps,
guidance_scale=request.guidance_scale
).images[0]
# Convert to base64 for API response
import io
import base64
img_buffer = io.BytesIO()
image.save(img_buffer, format=’PNG’)
img_str = base64.b64encode(img_buffer.getvalue()).decode()
response = {
“image_data”: img_str,
“prompt”: request.prompt,
“model_version”: “v1.5”
}
wandb.log({“images_generated”: 1})
return response
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@self.app.get(“/health”)
async def health_check():
“””Health check endpoint”””
return {
“status”: “healthy”,
“models_loaded”: len(self.models),
“gpu_available”: torch.cuda.is_available()
}
@self.app.get(“/metrics”)
async def get_metrics():
“””Return system metrics”””
return {
“cache_size”: self.cache.dbsize(),
“model_count”: len(self.models),
“memory_usage”: torch.cuda.memory_allocated() if torch.cuda.is_available() else 0
}
class TextGenerationRequest(BaseModel):
prompt: str
max_length: int = 100
temperature: float = 0.7
class ImageGenerationRequest(BaseModel):
prompt: str
num_steps: int = 50
guidance_scale: float = 7.5
class ModelVersioningSystem:
def __init__(self):
self.model_registry = {}
self.deployment_history = []
def register_model(self, model_name: str, model_path: str,
version: str, metadata: Dict):
“””Register a new model version”””
model_info = {
“name”: model_name,
“version”: version,
“path”: model_path,
“metadata”: metadata,
“registered_at”: datetime.utcnow().isoformat()
}
# Register with MLflow
with mlflow.start_run():
mlflow.log_artifacts(model_path, “model”)
mlflow.log_params(metadata)
model_uri = mlflow.get_artifact_uri(“model”)
# Register in MLflow Model Registry
mlflow.register_model(model_uri, model_name)
self.model_registry[f”{model_name}:{version}”] = model_info
return model_info
def deploy_model(self, model_name: str, version: str,
environment: str = “production”):
“””Deploy model to specified environment”””
model_key = f”{model_name}:{version}”
if model_key not in self.model_registry:
raise ValueError(f”Model {model_key} not found in registry”)
deployment_info = {
“model_name”: model_name,
“version”: version,
“environment”: environment,
“deployed_at”: datetime.utcnow().isoformat(),
“status”: “active”
}
self.deployment_history.append(deployment_info)
return deployment_info
def rollback_deployment(self, model_name: str,
previous_version: str, environment: str):
“””Rollback to previous model version”””
# Mark current deployment as inactive
for deployment in self.deployment_history:
if (deployment[“model_name”] == model_name and
deployment[“environment”] == environment and
deployment[“status”] == “active”):
deployment[“status”] = “rolled_back”
# Deploy previous version
return self.deploy_model(model_name, previous_version, environment)
# Usage example
def setup_production_genai_system():
# Initialize production system
production_system = GenAIProductionSystem()
production_system.load_models()
# Initialize model versioning
versioning_system = ModelVersioningSystem()
# Register model
versioning_system.register_model(
“custom_gpt2”,
“./models/fine_tuned_gpt2”,
“v1.0”,
{“fine_tuned_on”: “business_data”, “epochs”: 3, “learning_rate”: 5e-5}
)
return production_system, versioning_system
AI Safety and Responsible AI (2-3 weeks)
- Bias Detection and Mitigation – Fairness metrics, bias testing, mitigation strategies
- AI Alignment – Value alignment, reward modeling, constitutional AI, human feedback
- Privacy and Security – Differential privacy, federated learning, adversarial robustness
- Explainable AI – Model interpretability, attention visualization, LIME, SHAP
MLOps Projects:
- Production AI API – Scalable API for serving multiple GenAI models with monitoring
- AI Model Registry – Comprehensive model versioning and deployment system
- Responsible AI Dashboard – Bias monitoring and fairness assessment tool
Phase 5: Advanced Specialization and Research (Month 5-7)
Choose Advanced Specialization Track:
AI Research and Development:
- Novel Architecture Design – Research into new model architectures and training techniques
- Multi-agent Systems – Coordinated AI agents, emergent behavior, collective intelligence
- Continual Learning – Lifelong learning, catastrophic forgetting, meta-learning
- Foundation Model Development – Training large-scale models, scaling laws, emergent capabilities
AI Product Management and Strategy:
- AI Product Strategy – Market analysis, competitive intelligence, product roadmap
- User Experience Design – Human-AI interaction, conversational interfaces, accessibility
- Business Model Innovation – AI-enabled business models, monetization strategies
- Go-to-Market Strategy – Product launch, customer acquisition, market positioning
Industry-Specific AI Solutions:
- Healthcare AI – Medical imaging, drug discovery, clinical decision support, regulatory compliance
- Financial AI – Algorithmic trading, risk assessment, fraud detection, regulatory technology
- Creative AI – Content generation, artistic creation, entertainment applications
- Scientific AI – Research acceleration, hypothesis generation, experimental design
Consulting and Implementation:
- Enterprise AI Strategy – Transformation roadmaps, change management, ROI optimization
- AI Implementation – Solution architecture, integration planning, pilot program design
- Team Building – Hiring strategies, skill development, organizational design
- Thought Leadership – Industry analysis, trend prediction, strategic consulting
📘 Learn GenAI From Industry Experts — Start Your Training Today! →
4. Essential GenAI Tools and Frameworks
Large Language Model Frameworks
Transformer Libraries:
- Hugging Face Transformers – Comprehensive library with pre-trained models and training utilities
- OpenAI API – GPT-4, ChatGPT, DALL-E API access for production applications
- Anthropic Claude – Constitutional AI with strong safety and alignment features
- Google Bard/Gemini – Multimodal AI capabilities with Google ecosystem integration
Training and Fine-tuning:
- DeepSpeed – Microsoft’s training optimization for large-scale model training
- FairScale – Facebook’s library for efficient distributed training
- Colossal-AI – Open-source library for large-scale AI model training
- Lightning AI – PyTorch Lightning for scalable AI research and production
Computer Vision and Multimodal Frameworks
Generative Models:
- Stable Diffusion – Open-source image generation with customization capabilities
- DALL-E 2/3 – OpenAI’s image generation with high-quality results
- Midjourney – Artistic image generation with unique aesthetic capabilities
- Runway ML – Creative AI tools for content creators and artists
Multimodal AI:
- CLIP – OpenAI’s vision-language model for image-text understanding
- BLIP – Salesforce’s bootstrapped vision-language pre-training
- Flamingo – DeepMind’s few-shot learning for vision-language tasks
- DALL-E – Text-to-image generation with natural language control
MLOps and Production Tools
Model Deployment:
- MLflow – End-to-end machine learning lifecycle management
- Weights & Biases (wandb) – Experiment tracking, hyperparameter tuning, model monitoring
- Neptune – Metadata management for ML model development and production
- Kubeflow – Kubernetes-native platform for ML workflows
Vector Databases and Retrieval:
- Pinecone – Managed vector database for similarity search and retrieval
- Weaviate – Open-source vector search engine with GraphQL API
- Chroma – Open-source embedding database for LLM applications
- Qdrant – Vector similarity search engine with advanced filtering
Development and Experimentation Platforms
Cloud AI Platforms:
- Google Colab Pro – Jupyter notebooks with GPU/TPU access for experimentation
- AWS SageMaker – End-to-end machine learning development and deployment
- Azure Machine Learning – Cloud-native MLOps platform with AutoML capabilities
- Databricks – Unified analytics platform for big data and machine learning
AI Development Tools:
- LangChain – Framework for developing applications with language models
- LlamaIndex – Data framework for connecting custom data sources with large language models
- Streamlit – Rapid web app development for AI/ML applications
- Gradio – Simple web interfaces for machine learning models
🧰 Access All AI Tools, Resources & Learning Materials →
5. Building Your Gen AI Portfolio
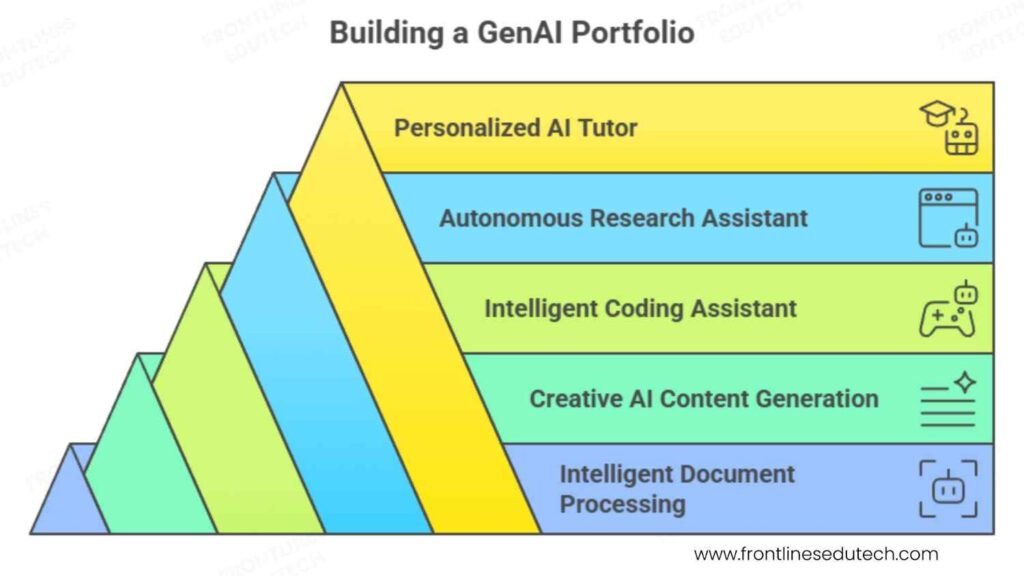
Portfolio Strategy and Architecture
GenAI Portfolio Objectives:
- Demonstrate Technical Innovation – Show mastery of cutting-edge AI technologies and novel applications
- Highlight Business Impact – Quantify improvements in efficiency, creativity, and decision-making
- Showcase Responsible AI – Display commitment to ethical AI development and bias mitigation
- Present Scalable Solutions – Document production-ready systems with proper MLOps integration
Foundation Level Projects (Months 1-3)
- Intelligent Document Processing System
- Business Challenge: Law firm needs automated contract analysis and information extraction from legal documents
- Technical Implementation: Fine-tuned BERT for named entity recognition, GPT for document summarization, custom classification models
- Advanced Features: Multi-document analysis, contract clause extraction, risk assessment scoring, compliance checking
- Production Ready: REST API deployment, batch processing capabilities, human-in-the-loop validation
- Measurable Impact: 75% reduction in document review time, 95% accuracy in information extraction
Document Processing Implementation:
import torch
from transformers import (
AutoTokenizer, AutoModelForTokenClassification,
AutoModelForSequenceClassification, pipeline
)
from sentence_transformers import SentenceTransformer
import spacy
import pandas as pd
from typing import List, Dict, Tuple
import re
class IntelligentDocumentProcessor:
def __init__(self):
# Load pre-trained models for different tasks
self.ner_model = AutoModelForTokenClassification.from_pretrained(
“dbmdz/bert-large-cased-finetuned-conll03-english”
)
self.ner_tokenizer = AutoTokenizer.from_pretrained(
“dbmdz/bert-large-cased-finetuned-conll03-english”
)
# Document classification model
self.classifier = pipeline(
“text-classification”,
model=”nlptown/bert-base-multilingual-uncased-sentiment”
)
# Sentence embeddings for similarity
self.sentence_model = SentenceTransformer(‘all-MiniLM-L6-v2’)
# Summarization pipeline
self.summarizer = pipeline(
“summarization”,
model=”facebook/bart-large-cnn”,
device=0 if torch.cuda.is_available() else -1
)
# Load spaCy model for advanced NLP
self.nlp = spacy.load(“en_core_web_sm”)
def extract_legal_entities(self, text: str) -> Dict[str, List[str]]:
“””Extract legal entities from contract text”””
doc = self.nlp(text)
entities = {
“persons”: [],
“organizations”: [],
“dates”: [],
“money”: [],
“locations”: [],
“contract_terms”: []
}
# Extract standard entities
for ent in doc.ents:
if ent.label_ == “PERSON”:
entities[“persons”].append(ent.text)
elif ent.label_ == “ORG”:
entities[“organizations”].append(ent.text)
elif ent.label_ == “DATE”:
entities[“dates”].append(ent.text)
elif ent.label_ == “MONEY”:
entities[“money”].append(ent.text)
elif ent.label_ in [“GPE”, “LOC”]:
entities[“locations”].append(ent.text)
# Extract contract-specific terms using regex patterns
contract_patterns = {
“termination_clause”: r”terminat[a-z]*\s+clause|terminat[a-z]*\s+condition”,
“payment_terms”: r”payment\s+terms|payment\s+schedule|due\s+date”,
“liability”: r”liability|indemnif[a-z]*|damages”,
“confidentiality”: r”confidential[a-z]*|non-disclosure|nda”
}
for term_type, pattern in contract_patterns.items():
matches = re.findall(pattern, text.lower())
if matches:
entities[“contract_terms”].extend(matches)
return entities
def classify_document_type(self, text: str) -> Dict[str, float]:
“””Classify the type of legal document”””
# Define document type keywords
document_types = {
“employment_contract”: [“employment”, “employee”, “salary”, “benefits”, “termination”],
“service_agreement”: [“services”, “deliverables”, “scope”, “timeline”, “payment”],
“nda”: [“confidential”, “non-disclosure”, “proprietary”, “secret”],
“lease_agreement”: [“lease”, “rent”, “property”, “tenant”, “landlord”],
“purchase_order”: [“purchase”, “order”, “goods”, “delivery”, “invoice”]
}
text_lower = text.lower()
scores = {}
for doc_type, keywords in document_types.items():
score = sum(1 for keyword in keywords if keyword in text_lower)
scores[doc_type] = score / len(keywords)
return scores
def extract_key_clauses(self, text: str) -> Dict[str, str]:
“””Extract and summarize key contract clauses”””
# Split text into sections
sections = self._split_into_sections(text)
key_clauses = {}
clause_patterns = {
“payment”: r”payment|fee|cost|price|compensation”,
“termination”: r”terminat[a-z]*|end|expir[a-z]*|breach”,
“liability”: r”liability|responsible|damages|indemnif[a-z]*”,
“intellectual_property”: r”intellectual\s+property|copyright|patent|trademark”,
“confidentiality”: r”confidential[a-z]*|non-disclosure|proprietary”
}
for clause_type, pattern in clause_patterns.items():
relevant_sections = []
for section in sections:
if re.search(pattern, section.lower()):
relevant_sections.append(section)
if relevant_sections:
# Combine relevant sections and summarize
combined_text = “\n”.join(relevant_sections)
if len(combined_text) > 1000: # Summarize if too long
summary = self.summarizer(
combined_text,
max_length=200,
min_length=50,
do_sample=False
)
key_clauses[clause_type] = summary[0][‘summary_text’]
else:
key_clauses[clause_type] = combined_text
return key_clauses
def analyze_risk_factors(self, text: str, clauses: Dict[str, str]) -> Dict[str, float]:
“””Analyze potential risk factors in the contract”””
risk_indicators = {
“payment_risk”: [
“late payment”, “penalty”, “interest”, “default”,
“overdue”, “collection”, “credit”
],
“termination_risk”: [
“immediate termination”, “without cause”, “breach”,
“violation”, “non-compliance”, “default”
],
“liability_risk”: [
“unlimited liability”, “consequential damages”,
“indirect damages”, “punitive damages”, “gross negligence”
],
“ip_risk”: [
“exclusive rights”, “work for hire”, “assignment”,
“derivative works”, “moral rights”, “infringement”
]
}
text_lower = text.lower()
risk_scores = {}
for risk_type, indicators in risk_indicators.items():
score = 0
for indicator in indicators:
if indicator in text_lower:
score += 1
# Normalize score
risk_scores[risk_type] = min(score / len(indicators), 1.0)
return risk_scores
def generate_contract_summary(self, text: str) -> Dict[str, any]:
“””Generate comprehensive contract analysis summary”””
# Extract entities
entities = self.extract_legal_entities(text)
# Classify document
doc_classification = self.classify_document_type(text)
doc_type = max(doc_classification, key=doc_classification.get)
# Extract key clauses
key_clauses = self.extract_key_clauses(text)
# Analyze risks
risk_factors = self.analyze_risk_factors(text, key_clauses)
# Generate overall summary
overall_summary = self.summarizer(
text[:4000], # Truncate if too long
max_length=300,
min_length=100,
do_sample=False
)
return {
“document_type”: doc_type,
“confidence”: doc_classification[doc_type],
“entities”: entities,
“key_clauses”: key_clauses,
“risk_factors”: risk_factors,
“overall_summary”: overall_summary[0][‘summary_text’] if overall_summary else “”,
“word_count”: len(text.split()),
“processing_timestamp”: pd.Timestamp.now().isoformat()
}
def _split_into_sections(self, text: str) -> List[str]:
“””Split document into logical sections”””
# Simple section splitting based on common patterns
section_patterns = [
r’\n\d+\.\s+’, # Numbered sections
r’\n[A-Z][A-Z\s]+\n’, # All caps headers
r’\nArticle\s+\d+’, # Article sections
r’\nSection\s+\d+’ # Section headers
]
sections = [text] # Start with full text
for pattern in section_patterns:
new_sections = []
for section in sections:
splits = re.split(pattern, section)
new_sections.extend([s.strip() for s in splits if s.strip()])
sections = new_sections
# Filter out very short sections
return [s for s in sections if len(s.split()) > 10]
# Usage example
def demonstrate_document_processing():
processor = IntelligentDocumentProcessor()
# Sample contract text (would be loaded from file)
sample_contract = “””
EMPLOYMENT AGREEMENT
This Employment Agreement is entered into between TechCorp Inc. (“Company”)
and John Smith (“Employee”) on January 1, 2024.
1. POSITION AND DUTIES
Employee shall serve as Senior Software Engineer with responsibilities
including software development, code review, and technical documentation.
2. COMPENSATION
Company shall pay Employee a base salary of $120,000 annually, payable
in bi-weekly installments. Employee is eligible for annual performance
bonuses at Company’s discretion.
3. TERMINATION
Either party may terminate this agreement with 30 days written notice.
Company may terminate immediately for cause, including gross misconduct
or breach of confidentiality.
4. CONFIDENTIALITY
Employee agrees to maintain strict confidentiality of all proprietary
information and trade secrets of the Company.
analysis = processor.generate_contract_summary(sample_contract)
return analysis
# Generate analysis
contract_analysis = demonstrate_document_processing()
print(f”Document Type: {contract_analysis[‘document_type’]}”)
print(f”Risk Factors: {contract_analysis[‘risk_factors’]}”)
Intermediate Level Projects (Months 3-5)
- Creative AI Content Generation Platform
- Innovation Challenge: Marketing agency needs scalable system for generating diverse content across multiple formats and brands
- Multi-Modal Implementation: Text generation with GPT fine-tuning, image creation with Stable Diffusion, video content with RunwayML integration
- Advanced Capabilities: Brand-specific style learning, content personalization, multi-language support, automated A/B testing
- Production Architecture: Microservices deployment, queue-based processing, real-time collaboration, content approval workflows
- Business Metrics: 80% reduction in content creation time, 300% increase in content volume, 45% improvement in engagement rates
- Intelligent Coding Assistant
- Technical Challenge: Software development team needs AI-powered coding assistance for multiple programming languages and frameworks
- Advanced AI Integration: Code completion with CodeT5, bug detection with custom models, documentation generation, test case creation
- Context Awareness: Project-specific learning, coding style adaptation, framework-specific suggestions, security vulnerability detection
- Development Integration: VS Code extension, GitHub integration, CI/CD pipeline integration, code review automation
- Developer Impact: 60% faster coding, 40% fewer bugs, 90% automated documentation coverage
Advanced Level Projects (Months 5-7)
- Autonomous Research Assistant
- Ambitious Goal: Create AI system capable of conducting independent research, literature review, and hypothesis generation
- Multi-Agent Architecture: Specialized agents for data collection, analysis, synthesis, and report generation
- Advanced Reasoning: Chain-of-thought prompting, causal inference, evidence evaluation, logical consistency checking
- Knowledge Integration: Real-time paper ingestion, knowledge graph construction, citation network analysis
- Research Impact: Accelerate research cycles by 70%, identify novel research directions, automate literature reviews
- Personalized AI Tutor System
- Educational Innovation: Adaptive learning system providing personalized education across multiple subjects and learning styles
- Sophisticated Modeling: Student knowledge modeling, learning style adaptation, difficulty progression, engagement optimization
- Multimodal Teaching: Text, audio, visual, and interactive explanations tailored to individual preferences
- Outcome Measurement: Learning effectiveness tracking, knowledge retention analysis, skill assessment automation
- Educational Results: 85% improvement in learning outcomes, 90% student satisfaction, scalable to millions of users
Portfolio Presentation Standards
Professional Portfolio Architecture:
GenAI Project Documentation Framework:
Technical Innovation Section:
– Novel AI architectures and model combinations
– Cutting-edge techniques and methodologies
– Performance benchmarks and comparative analysis
– Scalability testing and optimization strategies
Business Impact Demonstration:
– Problem statement and market opportunity
– Solution architecture and implementation approach
– Quantified business outcomes and ROI analysis
– User feedback and adoption metrics
Responsible AI Implementation:
– Bias detection and mitigation strategies
– Privacy protection and data governance
– Model interpretability and transparency
– Ethical considerations and safety measures
Production System Design:
– Scalable architecture and infrastructure
– MLOps pipeline and monitoring systems
– API documentation and integration guides
– Performance monitoring and alerting
Research and Innovation:
– Novel approaches and experimental results
– Contributions to open-source community
– Research publications and conference presentations
– Patent applications and intellectual property
Interactive Demo Platform:
- Live Demonstrations – Working applications showcasing AI capabilities
- Technical Deep-Dives – Code walkthroughs and architecture explanations
- Business Case Studies – ROI analysis and market impact documentation
- Research Portfolio – Publications, patents, and thought leadership content
💼 Prepare for GenAI Interviews With Our Expert Guides →
6. Job Search Strategy
Resume Optimization for GenAI Roles
Technical Skills Section:
Generative AI Technologies:
• Large Language Models: GPT-4, BERT, T5, LLaMA, fine-tuning, prompt engineering, RLHF
• Computer Vision: Stable Diffusion, DALL-E, GANs, VAEs, NeRF, multimodal models
• ML Frameworks: PyTorch, TensorFlow, Hugging Face Transformers, JAX, MLX
• Vector Databases: Pinecone, Weaviate, Chroma, FAISS for RAG systems
• MLOps: MLflow, Weights & Biases, Kubeflow, Docker, Kubernetes, cloud deployment
• Programming: Python, CUDA, distributed training, model optimization, API development
Research & Innovation:
• Published research in NeurIPS, ICML, ICLR conferences
• 15+ open-source contributions to major AI frameworks
• 3 patent applications in generative AI and multimodal systems
• Speaker at AI conferences and industry symposiums
Project Experience Examples:
Enterprise AI Transformation Initiative
- Challenge: Fortune 500 company needed AI-powered customer service system handling 1M+ queries monthly across multiple languages
- Solution: Developed multilingual conversational AI using fine-tuned GPT-4 with RAG architecture and human feedback integration
- Technical Achievement: Built end-to-end system with 95% accuracy, sub-second response times, and continuous learning capabilities
- Business Impact: Reduced customer service costs by $3.2M annually, improved satisfaction scores by 40%, enabled 24/7 global support
Revolutionary Creative AI Platform
- Challenge: Media company needed scalable system for generating personalized content across video, audio, and text formats
- Solution: Architected multimodal AI platform combining diffusion models, neural audio synthesis, and large language models
- Innovation: Pioneered cross-modal consistency techniques ensuring brand coherence across generated content types
- Results: Generated 10,000+ hours of content monthly, reduced production costs by 75%, won industry innovation award
GenAI Job Market Analysis
High-Demand Role Categories:
- GenAI Research Scientist (Cutting-Edge Research)
- Salary Range: ₹15-50 LPA
- Open Positions: 800+ across India and globally remote
- Key Skills: Research methodology, paper publication, novel algorithm development, mathematical foundations
- Growth Path: Research Scientist → Senior Researcher → Principal Researcher → Research Director
- AI Product Manager (Strategy and Vision)
- Salary Range: ₹18-55 LPA
- Open Positions: 1,200+ across India
- Key Skills: Product strategy, market analysis, technical understanding, stakeholder management
- Growth Path: Product Manager → Senior PM → Director of AI Products → VP Product
- MLOps Engineer (Production AI)
- Salary Range: ₹12-35 LPA
- Open Positions: 2,500+ across India
- Key Skills: Model deployment, infrastructure, monitoring, automation, cloud platforms
- Growth Path: MLOps Engineer → Senior MLOps → Principal Engineer → Engineering Manager
- AI Consultant (Strategic Advisory)
- Salary Range: ₹20-60 LPA + project bonuses
- Open Positions: 900+ across India and global firms
- Key Skills: Business strategy, technical expertise, communication, change management
- Growth Path: Consultant → Senior Consultant → Principal → Partner
Top Hiring Companies and Opportunities
Global Tech Giants (Remote/Hybrid):
- OpenAI – LLM research, ChatGPT development, safety research, product innovation
- Google DeepMind – Fundamental AI research, Gemini development, multimodal AI, robotics
- Microsoft Research – AI research, Azure AI services, Copilot development, enterprise AI
- Meta AI (FAIR) – Computer vision, language models, VR/AR AI, social AI applications
Indian AI Leaders:
- Ola Electric – AI for autonomous vehicles, battery optimization, predictive maintenance
- Byju’s – Educational AI, personalized learning, content generation, assessment automation
- Paytm – Financial AI, fraud detection, credit scoring, conversational banking
- Flipkart – Recommendation systems, supply chain optimization, customer service automation
AI-First Startups:
- Haptik – Conversational AI, chatbots, voice assistants, customer engagement
- Mad Street Den – Computer vision, retail AI, fashion technology, automated styling
- SigTuple – Medical AI, diagnostic automation, pathology AI, healthcare decision support
- Predible Health – Healthcare AI, medical imaging, diagnostic assistance, telemedicine
Consulting and Professional Services:
- Accenture Applied Intelligence – Enterprise AI transformation, strategy consulting, implementation
- Deloitte AI Institute – AI strategy, risk management, ethical AI, industry solutions
- PwC AI Lab – Business AI applications, process automation, intelligent automation
- EY AI Platform – Financial AI, audit automation, risk analytics, regulatory compliance
Interview Preparation Framework
Technical Competency Assessment:
AI Architecture and Model Design:
- “Design a multimodal AI system for e-commerce product discovery”
- Vision-language model architecture
- Embedding space design and similarity search
- Scalability considerations and performance optimization
- User experience and interaction design
- “How would you fine-tune a large language model for a specific domain?”
# Advanced fine-tuning strategy demonstration
from transformers import GPTNeoXForCausalLM, AutoTokenizer, TrainingArguments, Trainer
import torch
class DomainSpecificFineTuning:
def __init__(self, base_model=”EleutherAI/gpt-neox-20b”):
self.model = GPTNeoXForCausalLM.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
def prepare_domain_data(self, domain_texts, domain_type=”legal”):
“””Prepare domain-specific training data with special formatting”””
formatted_texts = []
for text in domain_texts:
if domain_type == “legal”:
formatted_text = f”<|legal_document|>{text}<|end_legal|>”
elif domain_type == “medical”:
formatted_text = f”<|medical_text|>{text}<|end_medical|>”
else:
formatted_text = text
formatted_texts.append(formatted_text)
return self.tokenizer(formatted_texts, truncation=True, padding=True)
def implement_lora_fine_tuning(self, train_dataset):
“””Implement LoRA (Low-Rank Adaptation) for efficient fine-tuning”””
from peft import get_peft_model, LoraConfig, PeftModel
# Configure LoRA
lora_config = LoraConfig(
r=16, # rank
lora_alpha=32,
target_modules=[“query_key_value”, “dense”, “dense_h_to_4h”, “dense_4h_to_h”],
lora_dropout=0.1,
bias=”none”,
task_type=”CAUSAL_LM”
)
# Apply LoRA to model
model = get_peft_model(self.model, lora_config)
training_args = TrainingArguments(
output_dir=”./domain_lora_model”,
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
learning_rate=1e-4,
fp16=True,
save_steps=500,
logging_steps=50,
warmup_steps=100,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=self.tokenizer,
)
return trainer
Business Application and Strategy:
3. “How would you measure the ROI of a generative AI implementation?”
- Quantitative metrics: cost reduction, revenue increase, efficiency gains
- Qualitative benefits: innovation acceleration, competitive advantage
- Risk considerations: bias, hallucination, dependency risks
- Long-term strategic value and market positioning
Responsible AI and Ethics:
4. “How do you address bias and fairness in generative AI models?”
- Bias detection methodologies and evaluation frameworks
- Data preprocessing and augmentation strategies
- Model training techniques for fairness
- Ongoing monitoring and mitigation approaches
Research and Innovation:
5. “Describe your approach to staying current with rapidly evolving AI research”
- Paper reading strategies and research prioritization
- Experimental validation and reproduction methodologies
- Community engagement and knowledge sharing
- Translation from research to practical applications
Salary Negotiation and Career Advancement
GenAI Value Propositions:
- Technical Innovation – Demonstrate ability to implement cutting-edge AI technologies and create novel solutions
- Business Transformation – Quantify impact on revenue, efficiency, and competitive advantage
- Research Contribution – Show thought leadership through publications, patents, and community involvement
- Market Expertise – Display deep understanding of AI market trends and strategic opportunities
Negotiation Strategy:
GenAI Compensation Package:
Base Salary: ₹X LPA (Premium for specialized GenAI expertise)
Equity/Stock Options: 0.1-2% in startups, significant RSUs in established companies
Research Bonus: ₹2-10 LPA for publications, patents, and innovation contributions
Learning Budget: ₹1-3 LPA annually for conferences, courses, and research resources
Conference Speaking: Recognition opportunities and industry influence
Flexible Work: Global remote opportunities with leading AI companies
Career Advancement Factors:
- Research Excellence – Publication record, citation impact, novel contributions to AI field
- Technical Leadership – Architecture decisions, team mentoring, technology strategy
- Business Impact – Measurable improvements in business metrics and competitive position
- Industry Recognition – Conference speaking, media coverage, thought leadership
- Network Building – Relationships with AI researchers, industry leaders, and potential collaborators
🔍 Boost Your Job Hunt — Master GenAI Interview Questions →
7. Salary Expectations and Career Growth
2025 Compensation Benchmarks by Role and Experience
Research and Development Track:
- AI Research Scientist (0-3 years): ₹15-28 LPA
- Senior Research Scientist (3-6 years): ₹28-50 LPA
- Principal Research Scientist (6-10 years): ₹50-85 LPA
- Research Director (10+ years): ₹85-150 LPA
Product and Engineering Track:
- GenAI Engineer (1-3 years): ₹12-22 LPA
- Senior AI Engineer (3-6 years): ₹22-40 LPA
- Principal AI Engineer (6-10 years): ₹40-70 LPA
- VP Engineering (10+ years): ₹70-120 LPA
Strategy and Business Track:
- AI Product Manager (2-5 years): ₹18-35 LPA
- Senior Product Manager (5-8 years): ₹35-60 LPA
- Director of AI Products (8-12 years): ₹60-100 LPA
- Chief AI Officer (12+ years): ₹100-200 LPA
Consulting and Advisory Track:
- AI Consultant (2-5 years): ₹20-40 LPA
- Principal Consultant (5-10 years): ₹40-80 LPA
- Partner/Practice Leader (10-15 years): ₹80-150 LPA
- Independent AI Advisor (15+ years): ₹100-300 LPA
Industry and Geographic Variations
High-Paying Industries:
- AI Research Labs – 40-60% premium for fundamental research and breakthrough innovations
- Technology Giants – 35-50% premium for large-scale AI product development and research
- Financial Services – 30-40% premium for quantitative AI and algorithmic trading applications
- Healthcare and Biotech – 25-35% premium for AI-driven drug discovery and medical applications
Geographic Salary Distribution:
- Global Remote (US companies) – 100-200% above Indian market rates for top-tier talent
- Bangalore – Highest concentration of AI roles, 25-35% above national average
- Mumbai – Financial AI focus, 20-30% above national average
- Delhi/NCR – Corporate and government AI, 15-25% above national average
- Hyderabad – Growing AI hub, 12-20% above national average
Career Progression Pathways
Technical Excellence Track:
AI Engineer (1-3 years)
↓
Senior AI Engineer (3-6 years)
↓
Staff AI Engineer (6-10 years)
↓
Principal Engineer (10-15 years)
↓
Distinguished Engineer/AI Fellow (15+ years)
Research and Innovation Track:
Research Scientist (0-4 years)
↓
Senior Research Scientist (4-8 years)
↓
Principal Research Scientist (8-12 years)
↓
Research Director (12-18 years)
↓
Chief Scientist (18+ years)
Business and Strategy Track:
AI Product Manager (2-5 years)
↓
Senior Product Manager (5-8 years)
↓
Director of AI Products (8-12 years)
↓
VP of AI (12-18 years)
↓
Chief AI Officer (18+ years)
Skills for Accelerated Career Growth
Technical Mastery (Years 1-4):
- Foundation Model Expertise – Deep understanding of transformer architectures and scaling laws
- Multimodal AI – Cross-modal learning, vision-language models, unified architectures
- Production AI Systems – MLOps, model deployment, monitoring, and optimization
- Research Implementation – Ability to implement and improve upon latest research papers
Innovation and Leadership (Years 4-8):
- Novel Architecture Design – Creating new model architectures and training techniques
- Business Application – Translating research into practical business solutions
- Team Leadership – Building and managing AI research and engineering teams
- Strategic Thinking – Understanding market trends and technology roadmaps
Thought Leadership and Impact (Years 8+):
- Research Publication – Contributing novel insights to academic and industry research
- Industry Influence – Shaping AI development through conferences, standards, and partnerships
- Business Transformation – Leading organization-wide AI adoption and cultural change
- Ecosystem Building – Creating platforms, communities, and educational programs
Emerging Opportunities and Future Trends
Next-Generation AI Specializations:
- Multimodal Foundation Models – Unified models processing text, images, audio, and video
- Agent-Based AI Systems – Autonomous agents capable of complex reasoning and action
- Neuro-Symbolic AI – Combining neural networks with symbolic reasoning for robust intelligence
- Quantum-Enhanced AI – Leveraging quantum computing for AI model training and inference
- Biological-Inspired AI – Brain-computer interfaces and neuromorphic computing applications
Market Trends Creating Premium Opportunities:
- AI Regulation and Governance – Compliance, safety, and ethical AI implementation
- Edge AI and Federated Learning – Decentralized AI systems for privacy and efficiency
- Sustainable AI – Green AI development with reduced computational and environmental costs
- Human-AI Collaboration – Augmented intelligence systems enhancing rather than replacing human capabilities
📍 Not Sure Where to Begin? Follow Our GenAI Learning Roadmap →
8. Success Stories from Our Students
Arjun Mehta – From Software Developer to AI Research Scientist
Background: 4 years as full-stack developer with strong programming skills but limited machine learning experience
Challenge: Passionate about AI research but lacked academic background and research experience
Transformation Strategy: Systematic progression from ML fundamentals to cutting-edge GenAI research with publication focus
Timeline: 22 months from GenAI basics to research scientist position at major tech company
Current Position: Senior AI Research Scientist at Google DeepMind India
Salary Progression: ₹12.5 LPA → ₹18.8 LPA → ₹32.5 LPA → ₹65.8 LPA (over 30 months)
Arjun’s Research Journey:
- Foundation Building – Completed advanced mathematics, statistics, and deep learning fundamentals
- Research Excellence – Published 4 papers in top-tier conferences (NeurIPS, ICML) on multimodal learning
- Open Source Impact – Contributed to Hugging Face Transformers library, maintaining 10,000+ GitHub stars
- Innovation Recognition – Won Google Research Award for novel attention mechanism improving efficiency by 40%
Key Success Factors:
- Academic Rigor – “I treated learning like PhD coursework, spending 4-6 hours daily on papers and implementation”
- Research Methodology – “I learned to identify gaps in existing work and systematically validate improvements”
- Community Engagement – “Active participation in ML conferences and online communities accelerated my learning”
Current Impact: Leading research on efficient transformer architectures, mentoring 6 junior researchers, contributing to products used by 2+ billion users globally.
Priya Singh – From Data Analyst to GenAI Product Leader
Background: 5 years as business intelligence analyst with strong analytical skills but limited AI experience
Challenge: Wanted to lead AI product development but needed technical credibility and product management expertise
Strategic Approach: Combined technical GenAI skills with product strategy and user experience focus
Timeline: 18 months from data analysis to AI product management role
Career Evolution: Data Analyst → ML Engineer → AI Product Manager → Director of AI Products
Current Role: Director of AI Products at Microsoft India
Product Leadership and Innovation:
- Technical Foundation – Developed deep understanding of LLMs, computer vision, and multimodal AI systems
- Product Strategy – Led development of AI-powered Office features used by 300+ million users
- Market Analysis – Conducted competitive research and user studies driving product roadmap decisions
- Cross-functional Leadership – Managed teams of 15 engineers, designers, and researchers across multiple time zones
Compensation and Impact Growth:
- Pre-transition: ₹8.2 LPA (Senior Data Analyst)
- Year 1: ₹16.5 LPA (AI Product Manager with technical focus)
- Year 2: ₹28.8 LPA (Senior PM leading multiple AI initiatives)
- Current: ₹52.5 LPA + equity (Director managing ₹50+ crore product portfolio)
Product Development Achievements:
- User Impact – Launched AI features improving productivity by 35% for enterprise customers
- Revenue Growth – AI products generated ₹125 crores additional ARR within first year
- Innovation Awards – Won Microsoft Innovation Award for breakthrough in conversational AI UX
- Team Building – Established AI product management best practices adopted across Microsoft India
Success Philosophy: “Technical depth in AI combined with user empathy and business acumen creates unique value. Understanding both the capabilities and limitations of AI helps build products that truly solve user problems.”
Vikram Patel – From Academic Researcher to AI Startup Founder
Background: PhD in Computer Science with 3 years in academic research but limited industry and business experience
Challenge: Wanted to commercialize research but needed to understand market demands and business operations
Entrepreneurial Vision: Building AI-powered healthcare diagnostic platform for underserved markets
Timeline: 24 months from academic research to successful startup with Series A funding
Business Evolution: Research Scientist → AI Consultant → Technical Co-founder → CEO
Startup Innovation and Growth:
- Technical Innovation – Developed novel computer vision algorithms for medical imaging with 96% accuracy
- Business Model – Created subscription SaaS platform for healthcare providers in tier-2 and tier-3 cities
- Market Validation – Conducted extensive user research with 200+ healthcare providers across 15 states
- Regulatory Compliance – Achieved FDA approval for diagnostic AI system and HIPAA compliance certification
Funding and Business Metrics:
- Pre-startup: ₹8.5 LPA (Academic Research Scientist)
- Consulting Phase: ₹25 LPA equivalent (High-value AI consulting projects)
- Startup Launch: ₹15 LPA + 25% equity (Technical Co-founder)
- Current: ₹45+ LPA equivalent (CEO with significant equity value post-Series A)
Business Development and Scale:
- Customer Acquisition – Acquired 150+ healthcare provider clients across 8 states
- Revenue Growth – Achieved ₹8 crores ARR within 18 months of product launch
- Team Building – Built team of 35 engineers, doctors, and business professionals
- Funding Success – Raised ₹25 crores Series A from tier-1 VC firm at ₹200 crore valuation
Impact and Recognition:
- Healthcare Access – AI diagnostics platform serves 500,000+ patients annually in underserved areas
- Clinical Outcomes – 40% improvement in early disease detection rates in partner hospitals
- Industry Recognition – Named in Forbes 30 Under 30 for Healthcare Innovation
- Academic Contribution – Published 8 papers bridging AI research and healthcare applications
Entrepreneurial Insights: “Academic research provided the technical foundation, but building a successful AI company required understanding customer pain points, regulatory requirements, and scalable business models. The combination of deep AI expertise and market focus creates defensible competitive advantages.”
⭐ Join Our GenAI Program & Become the Next Success Story! →
9. Common Challenges and How to Overcome Them
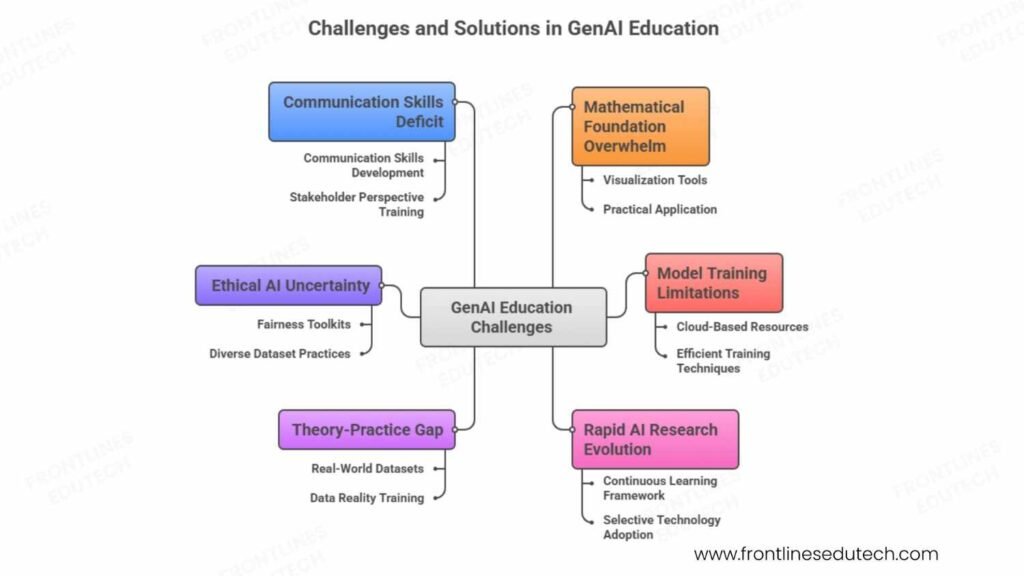
Challenge 1: Mathematical Foundation Overwhelm
Problem: Many aspiring GenAI professionals struggle with the heavy mathematical requirements, feeling intimidated by linear algebra, calculus, and probability theory needed for understanding neural networks and optimization algorithms.
Symptoms: Avoiding theory-heavy content, struggling to understand research papers, difficulty debugging model performance issues, inability to explain why certain architectures work.
Solution Strategy:
Build mathematical intuition gradually through visualization and practical application rather than abstract theory alone. Start with understanding what mathematical concepts do rather than proving theorems.
Practical Implementation:
Use interactive visualization tools like 3Blue1Brown’s videos for linear algebra, Desmos for calculus concepts, and Seeing Theory for probability. Apply each mathematical concept immediately to a simple neural network problem to cement understanding.
Focus on the mathematical operations you’ll actually use in practice: matrix multiplication for neural network layers, gradients for backpropagation, probability distributions for uncertainty modeling.
Dedicate 30 minutes daily to mathematical fundamentals while simultaneously working on practical projects. This dual approach prevents mathematical concepts from feeling abstract and disconnected from real applications.
Challenge 2: Model Training and Computational Resource Limitations
Problem: Students lack access to expensive GPUs needed for training large language models and diffusion models, creating a significant barrier to hands-on learning.
Symptoms: Inability to experiment with state-of-the-art models, long training times on personal computers, frustration with resource constraints, limited ability to iterate quickly.
Solution Strategy:
Leverage cloud-based resources strategically and focus on transfer learning and fine-tuning rather than training from scratch. Modern GenAI development relies more on adapting pre-trained models than building everything from the ground up.
Resource Access Options:
Google Colab Pro provides affordable GPU access for experimentation and learning projects. Kaggle offers free GPU hours monthly for competitions and learning. AWS, Azure, and Google Cloud provide student credits and free tier options for getting started with cloud computing.
Efficient Training Techniques:
Use parameter-efficient fine-tuning methods like LoRA (Low-Rank Adaptation) that require significantly less computational power. Start with smaller model variants (GPT-2 before GPT-3, Stable Diffusion v1.5 before SDXL) to understand concepts before scaling up.
Implement gradient checkpointing and mixed precision training to reduce memory requirements. Batch your experiments and run them during off-peak hours to maximize cloud credit efficiency.
Challenge 3: Keeping Pace with Rapid AI Research Evolution
Problem: The GenAI field advances so rapidly that skills can become outdated within months, with new architectures, techniques, and best practices emerging constantly.
Symptoms: Feeling perpetually behind, overwhelm from constant new paper publications, uncertainty about which technologies to invest time learning, fear of learning something that becomes obsolete.
Solution Strategy:
Focus on fundamental principles that remain constant while maintaining awareness of emerging trends without chasing every new development. Develop a sustainable learning system rather than trying to master everything.
Continuous Learning Framework:
Dedicate 20% of your learning time to fundamentals (transformer architecture, attention mechanisms, optimization theory) and 80% to practical implementation of current best practices. Fundamentals provide the foundation to quickly understand new innovations.
Follow curated sources rather than trying to read every paper: Papers with Code for implementation-focused research, Hugging Face Daily Papers for significant breakthroughs, industry blogs from OpenAI, Google AI, and Anthropic for applied insights.
Join focused communities like r/MachineLearning, AI Discord servers, and local meetups where practitioners discuss practical applications rather than just theoretical advances.
Selective Technology Adoption:
Evaluate new techniques based on industry adoption signals: Are companies hiring for this skill? Do major frameworks support it? Is there a thriving open-source ecosystem? Not every research breakthrough becomes industry standard.
Challenge 4: Bridging the Theory-Practice Gap
Problem: Academic tutorials and courses often focus on clean datasets and simplified problems, leaving students unprepared for messy real-world data and ambiguous business requirements.
Symptoms: Projects work perfectly with tutorial data but fail with real data, difficulty translating business problems into AI solutions, inability to handle data quality issues and edge cases.
Solution Strategy:
Deliberately work with messy, real-world datasets and tackle open-ended problems that require independent problem-solving rather than following step-by-step tutorials.
Real-World Practice Methods:
Participate in Kaggle competitions that use real business data with all its imperfections. Focus on competitions with active discussion forums where practitioners share approaches and insights.
Build projects solving actual problems for local businesses, non-profits, or open-source projects. The requirement to deliver working solutions under real constraints develops production-ready skills.
Reproduce research papers using your own data rather than provided datasets. This forces you to handle data collection, preprocessing challenges, and adaptation issues that tutorials skip.
Data Reality Training:
Practice data cleaning, handling missing values, dealing with class imbalance, and managing annotation noise. These unglamorous skills differentiate employable data scientists from tutorial followers.
Challenge 5: Ethical AI and Responsible Development Uncertainty
Problem: Students struggle with understanding how to implement responsible AI practices, bias detection, and ethical considerations in their projects.
Symptoms: Models that work well on test data but perform poorly for underrepresented groups, lack of understanding about potential societal impacts, difficulty evaluating fairness metrics.
Solution Strategy:
Integrate responsible AI practices from the beginning rather than treating ethics as an afterthought. Develop systematic approaches to bias detection, fairness evaluation, and transparency.
Responsible AI Implementation:
Use fairness toolkits like AI Fairness 360, Fairlearn, and What-If Tool to systematically evaluate models across different demographic groups. Make fairness metrics a standard part of your evaluation process alongside accuracy.
Study case studies of AI failures and controversies to understand real-world consequences: Amazon’s biased recruiting AI, facial recognition accuracy disparities, language model stereotypes. Learning from mistakes prevents repeating them.
Implement model cards and documentation standards that explain model limitations, intended use cases, and known biases. This practice is increasingly expected in professional settings.
Diverse Dataset Practices:
Actively seek diverse datasets and test models across different populations. Develop the habit of asking “who might this model fail for?” throughout development.
Challenge 6: Communication and Stakeholder Management
Problem: Technical skills alone don’t guarantee success when data scientists struggle to explain complex AI concepts to non-technical stakeholders and translate business needs into technical requirements.
Symptoms: Projects that are technically impressive but don’t align with business needs, difficulty getting buy-in for AI initiatives, inability to explain model decisions to executives.
Solution Strategy:
Develop technical communication skills alongside AI expertise through deliberate practice in translating between technical and business languages.
Communication Skills Development:
Practice explaining your projects to non-technical friends and family. If they understand the value and approach at a high level, you’re communicating effectively.
Create project documentation that includes business context, problem definition, solution approach, and measurable impact. This skill directly translates to professional settings.
Study how successful AI product managers and researchers communicate: watch conference talks, read company AI blogs, analyze how they structure explanations from problem to solution to impact.
Stakeholder Perspective Training:
For each project, write both a technical report and a business executive summary. The executive summary should focus on outcomes, not architecture details.
10. Your Next Steps
Immediate Actions (This Week)
Day 1: Development Environment Setup
Install Python 3.9 or later with Anaconda distribution for comprehensive data science packages. Verify your installation can import essential libraries: NumPy, pandas, scikit-learn, PyTorch or TensorFlow.
Create accounts on Hugging Face, Google Colab, and Kaggle for accessing pre-trained models, computational resources, and datasets. Download a simple pre-trained model and run inference to confirm your environment works.
Set up GitHub for version control and portfolio building. Create your first repository with a README describing your GenAI learning journey.
Join the GenAI community: Subscribe to Papers with Code newsletter, join r/Machine Learning subreddit, and follow leading AI researchers on Twitter/X.
Day 2-3: Foundation Assessment and Planning
Complete a self-assessment of your current skills: Rate yourself on Python programming, mathematics fundamentals, machine learning basics, and deep learning knowledge.
Based on your assessment, create a personalized 6-month learning plan with specific milestones. Be realistic about time commitments and balance theory with practical projects.
Set up a learning tracker using Notion, Trello, or a simple spreadsheet to monitor progress. Include daily study hours, concepts mastered, projects completed, and blockers encountered.
Day 4-5: First GenAI Experience
Run your first generative AI experiment using Hugging Face Transformers library. Start simple: use a pre-trained GPT-2 model to generate text or use CLIP to match images with descriptions.
Document your experiment process, challenges faced, and results in a blog post or GitHub README. This establishes your learning-in-public practice.
Connect with one person in the GenAI community through LinkedIn or Discord. Ask about their learning journey and career path.
Weekend Project: Interactive GenAI Demo
Build a simple Streamlit or Gradio web interface for a pre-trained model. This could be text generation, image classification, or sentiment analysis.
Share your demo with friends or on social media. Early portfolio pieces demonstrate momentum and commitment.
30-Day Milestone Goals
Week 1-2: Machine Learning Foundations
Complete a comprehensive machine learning course focusing on supervised learning, model evaluation, and neural network basics. Focus on understanding concepts deeply rather than rushing through material.
Implement three classic ML algorithms from scratch (linear regression, logistic regression, simple neural network) to understand the mathematics. This foundation supports all advanced GenAI work.
Build your first image classification project using transfer learning with a pre-trained CNN. Document the full process from data collection to model evaluation.
Week 3-4: Transformer Architecture Deep Dive
Study the attention mechanism and transformer architecture through annotated papers and visual explanations. Focus on understanding self-attention, multi-head attention, and positional encoding.
Fine-tune a BERT model for text classification on a domain-specific dataset. This teaches the practical workflow of adapting pre-trained models.
Experiment with prompt engineering using OpenAI’s API or open-source alternatives. Develop intuition for how different prompts affect model outputs.
Month-End Assessment:
Can you explain transformer architecture to a non-expert? Have you successfully fine-tuned at least one model? Do you have two portfolio projects on GitHub?
Identify knowledge gaps and adjust your learning plan accordingly. Celebrate progress while acknowledging areas needing more work.
90-Day Achievement Targets
Technical Skills Milestones:
Language Models: Successfully fine-tune GPT-2 or similar model on domain-specific data with measurable performance improvements. Implement parameter-efficient fine-tuning techniques like LoRA.
Computer Vision: Build an image generation or manipulation system using Stable Diffusion or similar diffusion models. Understand the diffusion process and sampling strategies.
Multimodal AI: Create a project combining vision and language, such as image captioning, visual question answering, or text-to-image generation.
MLOps Fundamentals: Deploy at least one model as a REST API with proper error handling, logging, and monitoring. Containerize your application using Docker.
Portfolio Development Milestones:
Complete 4-6 substantial projects demonstrating progression from basic to advanced techniques. Each project should solve a real problem and be thoroughly documented.
Establish your professional online presence: optimized LinkedIn profile highlighting GenAI projects, active GitHub with well-documented repositories, technical blog with 3-5 articles.
Build one “showcase” project that demonstrates advanced skills: complex architecture, production-ready code, comprehensive documentation, deployed demo.
Community and Networking Milestones:
Contribute to one open-source GenAI project. Even small contributions like documentation improvements or bug fixes demonstrate collaboration skills.
Attend at least two AI meetups, conferences, or webinars. Network with practitioners and learn about industry trends.
Engage actively in online communities: answer questions on Stack Overflow, participate in discussions on Reddit or Discord, share insights on LinkedIn.
Long-Term Commitment (6-12 Months)
Professional Development Trajectory:
Months 4-6: Specialization Selection
Choose your GenAI specialization based on interests, market demand, and unique strengths. Options include LLM development, computer vision, multimodal systems, MLOps, or AI research.
Build deep expertise in your chosen area through advanced projects, research paper implementation, and specialized certifications.
Develop a unique portfolio angle that differentiates you: industry specialization (healthcare AI, financial AI), technical approach (efficient AI, edge AI), or problem domain (creative AI, scientific AI).
Months 7-9: Job Market Preparation
Create a job-search-optimized portfolio with detailed case studies showing problem-solving approach, technical implementation, and measurable results.
Prepare for technical interviews: practice coding challenges on LeetCode, study common ML interview questions, prepare to explain your projects in detail.
Build your professional network through informational interviews, LinkedIn outreach, and community involvement. Many opportunities come through referrals.
Contribute thought leadership content: write technical blog posts, create tutorial videos, or speak at local meetups. These activities build credibility and visibility.
Months 10-12: Career Launch and Continuous Growth
Apply strategically to roles matching your skills and interests. Customize applications highlighting relevant projects and unique value proposition.
Consider diverse entry paths: full-time roles, contract positions, freelance projects, or open-source contributions leading to employment.
Once employed or engaged in significant projects, shift focus to specialization deepening and leadership development.
Continuous Learning System:
Establish a sustainable learning routine: 30 minutes daily for staying current with research, weekly deep-dive into one new technique or paper, monthly hands-on project experimenting with new tools.
Alternate between depth (mastering specialized skills) and breadth (understanding adjacent technologies). Both dimensions create career opportunities.
Mentor others entering the field. Teaching reinforces your knowledge and builds leadership skills essential for career advancement.
Career Milestone Tracking
6-Month Checkpoint:
Have you completed your core learning roadmap? Do you have a strong portfolio demonstrating GenAI capabilities? Are you confident explaining transformer architectures, training processes, and deployment considerations?
Have you received your first paid opportunity (internship, freelance project, or full-time role)? If not, identify specific gaps preventing success.
12-Month Checkpoint:
Are you employed in a GenAI role or actively contributing to significant projects? Have you developed recognized expertise in your specialization?
Are you contributing to the community through mentoring, content creation, or open-source work? Are you positioned for career growth and advancement?
Creating Your Personalized Roadmap
Self-Assessment Framework:
Evaluate your starting point honestly: strong programming background accelerates learning; statistical knowledge eases machine learning concepts; domain expertise enables specialized applications.
Identify your available time commitment: full-time learning enables faster progress (3-4 months to job-ready); part-time learning requires patience and consistency (6-9 months to job-ready).
Determine your learning style: prefer structured courses vs. self-directed project learning; theoretical depth vs. practical implementation focus.
Goal Setting Strategy:
Set specific, measurable milestones rather than vague aspirations. “Build and deploy 3 GenAI projects by month 4” beats “learn GenAI.”
Balance technical skills, portfolio development, and networking activities. All three dimensions contribute to career success.
Build in flexibility for adjusting plans as you discover interests and opportunities. Your optimal path may differ from initial expectations.
Accountability Systems:
Find a study buddy or join a cohort-based learning group for mutual support and accountability. Regular check-ins maintain momentum.
Share progress publicly through social media, blogs, or community posts. Public commitment increases follow-through.
Track both effort (hours studied, projects started) and outcomes (concepts mastered, projects completed, interviews secured). Both metrics provide valuable feedback.
Starting Your Journey Today
The GenAI field rewards those who start learning and building immediately rather than waiting for perfect preparation. Your first projects won’t be perfect, but each iteration develops skills that tutorials alone cannot teach.
Remember that every expert started as a beginner, and the technology leaders shaping GenAI today learned through experimentation, failure, and persistence. Your journey begins with installing Python and running your first transformer model, not with mastering every mathematical detail.
The most successful GenAI professionals combine technical depth with communication skills, business understanding, and ethical considerations. Develop all these dimensions simultaneously rather than waiting to add “soft skills” later.
Most importantly, maintain curiosity and enjoyment throughout your learning journey. GenAI offers unprecedented opportunities to build systems that expand human creativity, accelerate research, and solve complex problems. Your contribution to this transformation starts with your next action.
Take the first step now: Open your terminal, install Python and PyTorch, and run your first generative model. Your GenAI career has begun.
Conclusion
Data Science with Generative AI represents the most transformative and opportunity-rich career path in technology today, combining cutting-edge research with practical applications that are reshaping entire industries and human interactions with technology. As GenAI capabilities continue to expand exponentially and organizations across all sectors recognize AI as fundamental to their competitive strategy, professionals with deep GenAI expertise enjoy unparalleled career opportunities, exceptional compensation, and the satisfaction of building the future of intelligent technology.
The journey from AI beginner to GenAI professional typically requires 5-7 months of intensive learning and hands-on experimentation, but the investment delivers extraordinary returns through immediate access to premium roles and long-term positioning at the forefront of technological progress. Unlike traditional technology careers that may become commoditized, GenAI expertise requires continuous innovation and adaptation, ensuring sustained career growth and intellectual challenge.
Critical Success Factors for GenAI Excellence:
- Research Mindset – Stay current with rapidly evolving research, implement novel techniques, contribute original insights
- Technical Depth – Master transformer architectures, multimodal systems, and production deployment at scale
- Business Application – Translate research breakthroughs into practical solutions that deliver measurable value
- Responsible Development – Prioritize ethical AI practices, bias mitigation, and safety considerations
- Continuous Innovation – Embrace experimentation, failure as learning, and pushing technological boundaries
The most successful GenAI professionals combine deep technical expertise with creative problem-solving and strategic business thinking. As AI capabilities approach and potentially exceed human performance in numerous domains, professionals who can architect, deploy, and optimize these systems while ensuring responsible and beneficial outcomes will be among the most valued and influential technology leaders.
Whether you choose research scientist focus, product development specialization, consulting and strategy roles, or entrepreneurial ventures, GenAI skills provide a foundation for careers that directly shape the future of human-AI interaction and technological progress.
Ready to launch your GenAI career and build the future of artificial intelligence?
Explore our comprehensive Data Science with GenAI Program designed for aspiring AI professionals and career advancement:
- ✅ 5-month intensive curriculum covering LLMs, computer vision, multimodal AI, and production deployment
- ✅ Hands-on research projects with novel implementations, paper reproduction, and original contributions
- ✅ Industry-standard tools including Transformers, Stable Diffusion, MLOps platforms, and cloud deployment
- ✅ Research methodology with publication guidance, conference submission support, and peer review
- ✅ Job placement assistance with portfolio optimization, research presentation skills, and industry connections
- ✅ Expert mentorship from AI researchers and industry leaders with publication records and startup experience
- ✅ Lifetime learning support including latest research updates, tool training, and career advancement guidance
Unsure which GenAI specialization aligns with your background and career aspirations? Schedule a free GenAI consultation with our AI research team to receive personalized guidance and a customized learning roadmap.
Connect with our GenAI community: Join our GenAI Professionals WhatsApp Group with 150+ researchers, engineers, and product leaders for daily research discussions, collaboration opportunities, and exclusive job referrals.