SQL Interview Questions & Answers Guide 2025

Mastering SQL is essential for anyone pursuing a data-related career in 2025. This comprehensive SQL Interview Preparation Guide features 205 carefully curated questions and answers to help you crack technical interviews with confidence. Covering everything from database fundamentals and DDL/DML statements to joins, set operations, and advanced SQL queries, this guide equips you with practical knowledge and interview-ready skills for top tech roles.
📌Get Ready for SQL Mastery!
Explore our Step-by-Step SQL Roadmap from fundamentals to advanced analytics.
Module 1: SQL Technical Interview Questions & Answers (205 Questions)
- Introduction to Data Warehouse and Database (-20)
- Introduction to SQL (2-40)
- DDL and DML Statements (4-70)
- Aggregate Functions (7-95)
- Joins and Set Operations (96-25)
- Advanced SQL Questions (26 – 205)
Introduction to Data Warehouse and Database
Fundamental Database Concepts
1. What is a database?
A database is an organized collection of structured data stored electronically in a computer system, managed by a Database Management System (DBMS) that allows efficient storage, retrieval, and manipulation of data.
2. What is a Data Warehouse?
A data warehouse is a centralized repository that stores integrated data from multiple sources, designed specifically for query and analysis rather than transaction processing, supporting business intelligence activities.
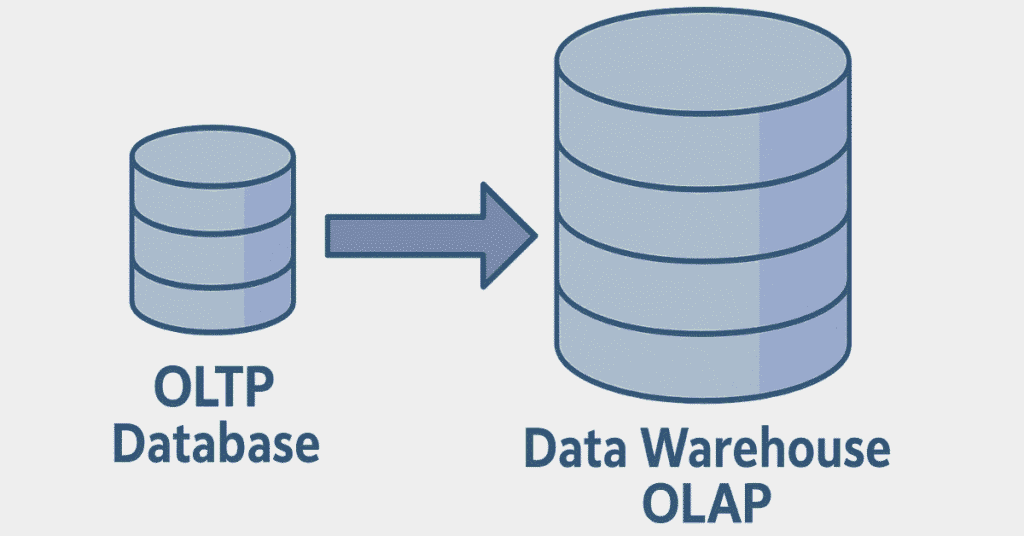
3. What is the difference between OLTP and OLAP?
OLTP (Online Transaction Processing) is designed for real-time transactional operations with frequent INSERT, UPDATE, and DELETE operations, while OLAP (Online Analytical Processing) is optimized for complex queries and data analysis on historical data.
is, pulvinar dapibus leo.
4. What is RDBMS?
RDBMS (Relational Database Management System) is a database management system based on the relational model where data is organized into tables with rows and columns, and relationships are established using keys.
5. What are the advantages of using a DBMS?
DBMS provides data security, reduced data redundancy, improved data consistency, easier data access, concurrent access control, data integrity, backup and recovery mechanisms, and centralized data management.
6. What is data redundancy?
Data redundancy occurs when the same piece of data is stored in multiple places within a database, leading to inconsistency, wasted storage space, and complications in data maintenance.
7. What is a relational database?
A relational database organizes data into tables (relations) consisting of rows (tuples) and columns (attributes), where relationships between tables are established through primary and foreign keys.
8. What are the different types of relationships in a database?
The main relationship types are One-to-One (:), One-to-Many (:N), Many-to-One (N:), and Many-to-Many (M:N), which define how records in one table relate to records in another table.
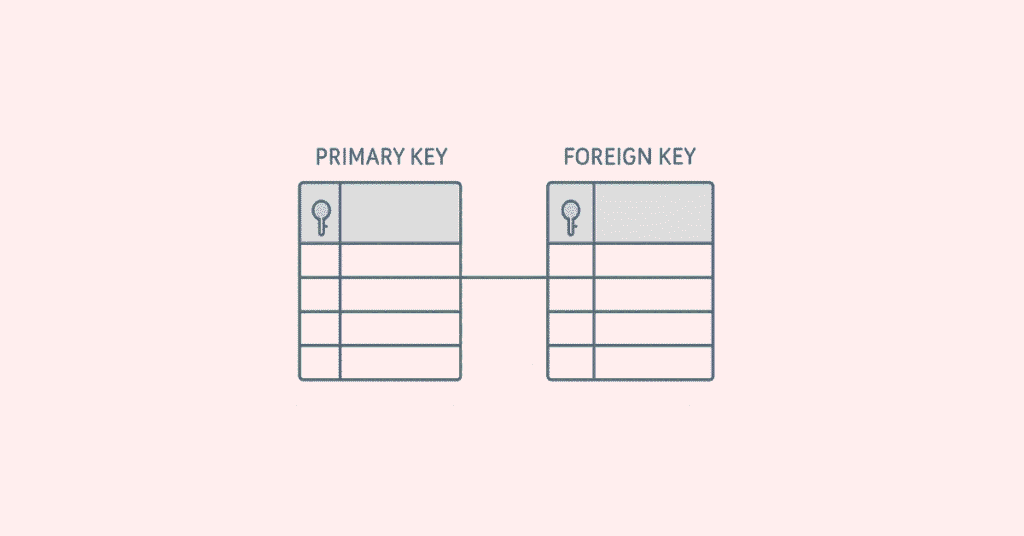
9. What is a primary key?
A primary key is a column or combination of columns that uniquely identifies each row in a table, ensuring no duplicate or NULL values are allowed.
10. What is a foreign key?
A foreign key is a column or set of columns in one table that references the primary key of another table, establishing a relationship between the two tables and maintaining referential integrity.
11. What are constraints in SQL?
Constraints are rules applied to table columns to enforce data integrity, including PRIMARY KEY, FOREIGN KEY, UNIQUE, NOT NULL, CHECK, and DEFAULT constraints.
12. What is the difference between a primary key and a unique key?
A primary key uniquely identifies records and cannot contain NULL values (only one per table), while a unique key also ensures uniqueness but can accept one NULL value and multiple unique keys can exist in a table.
13. What is a composite key?
A composite key is a primary key composed of two or more columns that together uniquely identify a record in a table, used when a single column cannot guarantee uniqueness.
14. What are logical operators in SQL?
Logical operators include AND (both conditions must be true), OR (at least one condition must be true), and NOT (reverses the condition), used to combine multiple conditions in WHERE clauses.
15. What are relational operators in SQL?
Relational operators compare values and include = (equal), != or <> (not equal), > (greater than), < (less than), >= (greater than or equal), and <= (less than or equal).
16. What is referential integrity?
Referential integrity ensures that relationships between tables remain consistent, meaning a foreign key value must either match a primary key value in the referenced table or be NULL.
17. What is data independence?
Data independence is the ability to modify the schema at one level without affecting the schema at the next higher level, divided into logical and physical data independence.
18. What is a database schema?
A database schema is the logical structure that defines how data is organized, including tables, columns, relationships, views, indexes, and constraints.
19. What is normalization?
Normalization is the process of organizing database tables to reduce data redundancy and improve data integrity by dividing large tables into smaller, related tables.
20. What are the advantages of database normalization?
Normalization eliminates data redundancy, improves data consistency, reduces storage space, simplifies database maintenance, and enhances query performance for specific operations.
Introduction to SQL
SQL Fundamentals
21. What is SQL?
SQL (Structured Query Language) is a standardized programming language used to manage, manipulate, and query relational databases, enabling operations like data retrieval, insertion, updating, and deletion.
22. What is SSMS?
SSMS (SQL Server Management Studio) is an integrated environment developed by Microsoft for configuring, managing, and administering SQL Server databases through a graphical user interface.
23. What are the different types of SQL commands?
SQL commands are categorized into DDL (Data Definition Language), DML (Data Manipulation Language), DCL (Data Control Language), TCL (Transaction Control Language), and DQL (Data Query Language).
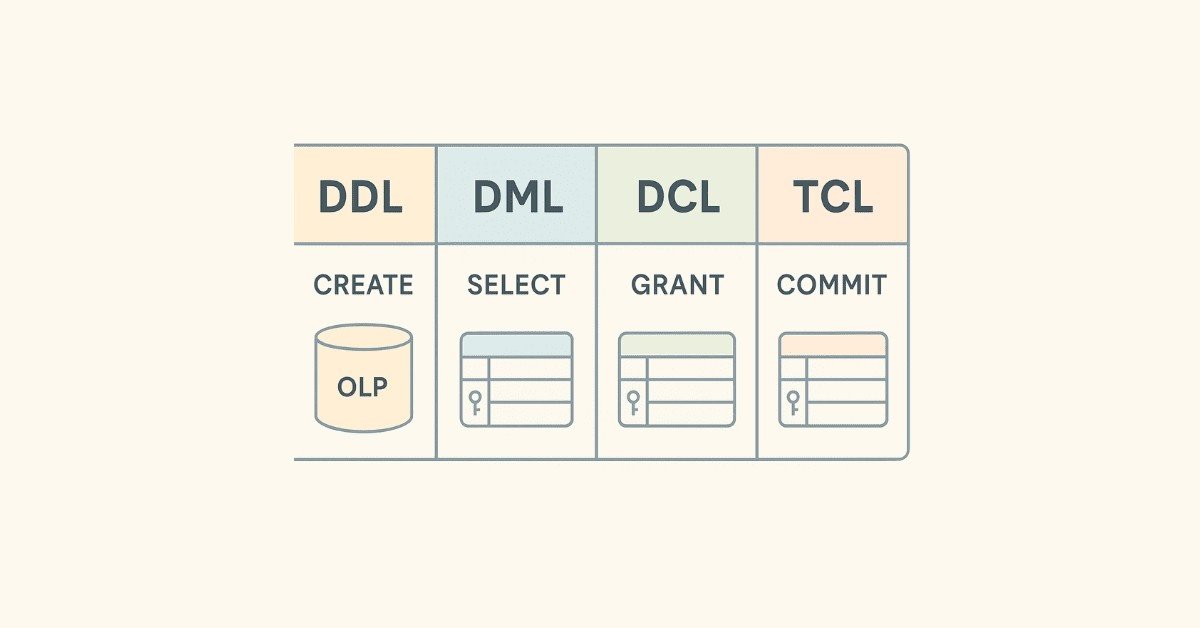
24. What is DDL (Data Definition Language)?
DDL consists of commands that define and modify database structure, including CREATE (create objects), ALTER (modify objects), DROP (delete objects), and TRUNCATE (remove all records).
25. What is DML (Data Manipulation Language)?
DML includes commands for manipulating data within tables: INSERT (add records), UPDATE (modify records), DELETE (remove records), and MERGE (insert or update).
26. What is DCL (Data Control Language)?
DCL commands control access to database objects, primarily GRANT (give permissions) and REVOKE (remove permissions), managing user privileges and security.
27. What is TCL (Transaction Control Language)?
TCL commands manage database transactions, including COMMIT (save changes permanently), ROLLBACK (undo changes), and SAVEPOINT (create transaction checkpoints).
28. What is DQL (Data Query Language)?
DQL consists primarily of the SELECT statement, used to retrieve and query data from database tables without modifying the data.

29. What are the main data types in SQL Server?
SQL Server data types include Numeric (INT, BIGINT, DECIMAL), Character (CHAR, VARCHAR, TEXT), Date/Time (DATE, DATETIME, TIMESTAMP), Binary (BINARY, VARBINARY), and Boolean (BIT).
30. What is the difference between CHAR and VARCHAR?
CHAR is a fixed-length character data type that always uses the declared size, while VARCHAR is variable-length and uses only the space needed for the actual data, making it more storage-efficient.
31. What is the difference between VARCHAR and TEXT?
VARCHAR has a maximum length limit (typically 8000 characters in SQL Server), while TEXT can store larger amounts of data but has limitations on indexing and certain operations.
32. What is the INT data type?
INT (Integer) is a numeric data type that stores whole numbers ranging from -2,47,483,648 to 2,47,483,647, commonly used for counting and identification purposes.
33. What is the DECIMAL data type?
DECIMAL is a fixed-precision numeric data type that stores exact numeric values with a specified number of digits before and after the decimal point, ideal for financial calculations.
34. What is the DATE data type?
DATE stores calendar dates (year, month, day) without time information, typically in the format YYYY-MM-DD, useful for tracking events and deadlines.
35. What is the DATETIME data type?
DATETIME stores both date and time information together, including year, month, day, hour, minute, and second, useful for timestamp recording.
36. What is NULL in SQL?
NULL represents the absence of a value or unknown data in a column, distinct from zero or empty string, and requires special handling with IS NULL or IS NOT NULL operators.
37. How do you check for NULL values?
Use IS NULL to check if a value is NULL (e.g., WHERE column_name IS NULL) and IS NOT NULL to check for non-NULL values, as normal comparison operators don’t work with NULL.
38. What is a database instance?
A database instance is a running copy of the database software that manages database files, including memory structures and background processes.
39. What is the difference between SQL and MySQL?
SQL is a standardized query language for managing relational databases, while MySQL is a specific relational database management system that implements SQL along with its own extensions.
40. What is the difference between SQL and NoSQL?
SQL databases are relational, table-based, use structured schemas, and support ACID properties, while NoSQL databases are non-relational, support flexible schemas, and are designed for horizontal scalability.
DDL and DML Statements
Table Creation and Modification
41. How do you create a database in SQL?
Use the CREATE DATABASE statement: CREATE DATABASE database_name; to create a new database.
42. How do you create a table in SQL?
Use the CREATE TABLE statement with column definitions: CREATE TABLE table_name (column datatype constraints, column2 datatype constraints);.
43. What is the ALTER TABLE command?
ALTER TABLE modifies an existing table structure, allowing you to ADD columns, DROP columns, MODIFY data types, or ADD/DROP constraints.
44. How do you add a new column to an existing table?
Use: ALTER TABLE table_name ADD column_name datatype; to add a new column to an existing table.
45. How do you delete a column from a table?
Use: ALTER TABLE table_name DROP COLUMN column_name; to remove a column from an existing table.
46. How do you modify a column’s data type?
Use: ALTER TABLE table_name ALTER COLUMN column_name new_datatype; (SQL Server syntax) to change a column’s data type.
47. What is the DROP TABLE command?
DROP TABLE permanently deletes a table and all its data from the database: DROP TABLE table_name;.
48. What is the difference between DROP and TRUNCATE?
DROP removes the entire table structure and data permanently, while TRUNCATE removes all rows but keeps the table structure, and TRUNCATE is faster and cannot be rolled back in some systems.
49. What is the INSERT statement?
INSERT adds new rows to a table: INSERT INTO table_name (column, column2) VALUES (value, value2);.
50. How do you insert multiple rows in a single INSERT statement?
Use: INSERT INTO table_name (column, column2) VALUES (valuea, value2a), (valueb, value2b), (valuec, value2c);.
51. What is the UPDATE statement?
UPDATE modifies existing records in a table: UPDATE table_name SET column = value, column2 = value2 WHERE condition;.
52. What is the DELETE statement?
DELETE removes specific rows from a table based on a condition: DELETE FROM table_name WHERE condition;.
53. What happens if you use DELETE without a WHERE clause?
All rows in the table will be deleted, but the table structure remains intact, making it a dangerous operation if used accidentally.
54. What is the TRUNCATE statement?
TRUNCATE removes all rows from a table quickly without logging individual row deletions, resetting identity columns: TRUNCATE TABLE table_name;.
55. What is the difference between DELETE and TRUNCATE?
DELETE can use WHERE clause for selective deletion, logs each deletion, can be rolled back, and doesn’t reset identity; TRUNCATE removes all rows, is faster, resets identity, and in some systems cannot be rolled back.
Basic SQL Queries
56. What is the SELECT statement?
SELECT retrieves data from one or more tables: SELECT column, column2 FROM table_name; is the basic syntax for querying data.
57. How do you select all columns from a table?
Use the asterisk (*) wildcard: SELECT * FROM table_name; to retrieve all columns.
58. What is the WHERE clause?
WHERE filters records based on specified conditions: SELECT * FROM table_name WHERE condition; returns only rows meeting the condition.
59. How do you use multiple conditions in WHERE?
Combine conditions using AND (both must be true) or OR (at least one must be true): WHERE condition AND condition2.
60. What is the ORDER BY clause?
ORDER BY sorts query results in ascending (ASC, default) or descending (DESC) order: SELECT * FROM table_name ORDER BY column_name DESC;.
61. How do you sort by multiple columns?
List columns in order of priority: ORDER BY column ASC, column2 DESC; sorts first by column, then by column2 for ties.
62. What is the LIMIT clause?
LIMIT restricts the number of rows returned: SELECT * FROM table_name LIMIT 0; returns only the first 0 rows (MySQL syntax).
63. What is the TOP clause in SQL Server?
TOP limits the number of rows returned in SQL Server: SELECT TOP 0 * FROM table_name; returns the first 0 rows.
64. What is the OFFSET clause?
OFFSET skips a specified number of rows before starting to return results, often used with LIMIT for pagination: LIMIT 0 OFFSET 20; skips 20 rows and returns next 0.
65. How do you filter text using patterns?
Use the LIKE operator with wildcards (% for any sequence, _ for single character): WHERE name LIKE ‘A%’ finds names starting with A.
66. What is the BETWEEN operator?
BETWEEN selects values within a range (inclusive): WHERE age BETWEEN 20 AND 30 selects ages from 20 to 30.
67. What is the IN operator?
IN checks if a value matches any value in a list: WHERE city IN (‘Delhi’, ‘Mumbai’, ‘Bangalore’).
68. How do you exclude values using NOT IN?
Use NOT IN to select rows where column value is not in the specified list: WHERE city NOT IN (‘Delhi’, ‘Mumbai’).
69. What are wildcards in SQL?
Wildcards are special characters used with LIKE: % (matches any sequence of characters), _ (matches single character), (matches any character within brackets), (matches any character not in brackets).
70. Give an example of pattern matching.
SELECT * FROM employees WHERE name LIKE ‘S%h’ finds names starting with S and ending with h, like “Singh” or “Shah”.
Aggregate Functions
COUNT, SUM, MIN, MAX, AVG

71. What are aggregate functions?
Aggregate functions perform calculations on multiple rows and return a single result, including COUNT, SUM, AVG, MIN, and MAX.
72. What does the COUNT() function do?
COUNT() returns the number of rows that match a specified condition: SELECT COUNT(*) FROM table_name; counts all rows.
73. What is the difference between COUNT(*) and COUNT(column)?
COUNT(*) counts all rows including NULL values, while COUNT(column) counts only non-NULL values in that specific column.
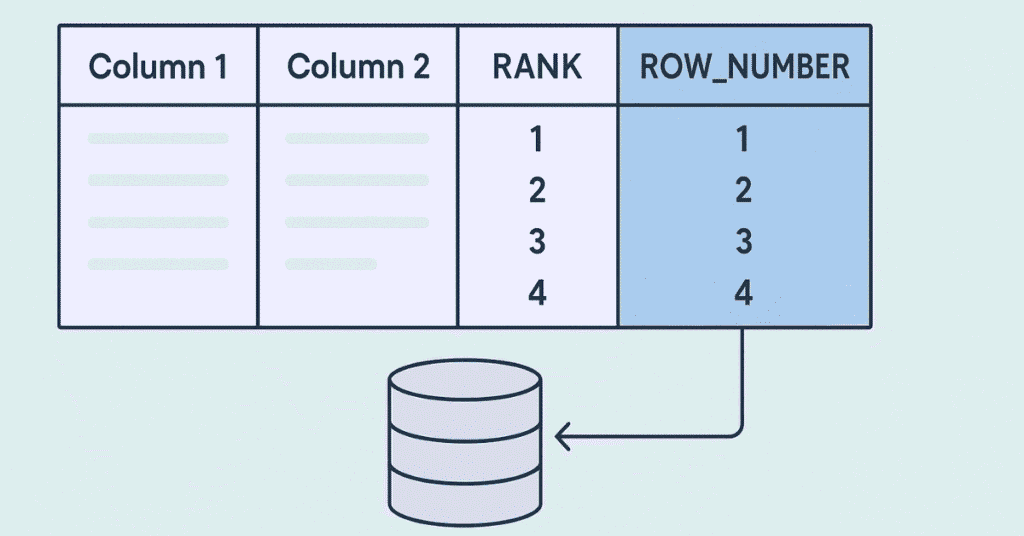
74. What does the SUM() function do?
SUM() calculates the total of numeric values in a column: SELECT SUM(salary) FROM employees; returns total salary.
75. What does the AVG() function do?
AVG() calculates the average of numeric values: SELECT AVG(salary) FROM employees; returns the mean salary.
76. What does the MIN() function do?
MIN() returns the smallest value in a column: SELECT MIN(salary) FROM employees; finds the lowest salary.
77. What does the MAX() function do?
MAX() returns the largest value in a column: SELECT MAX(salary) FROM employees; finds the highest salary.
78. What is the GROUP BY clause?
GROUP BY groups rows with the same values in specified columns into summary rows, typically used with aggregate functions: SELECT department, COUNT(*) FROM employees GROUP BY department;.
79. What is the HAVING clause?
HAVING filters grouped results (used after GROUP BY), similar to WHERE but for aggregated data: HAVING COUNT(*) > 5 filters groups with more than 5 records.
80. What is the difference between WHERE and HAVING?
WHERE filters individual rows before grouping, while HAVING filters groups after aggregation; WHERE cannot use aggregate functions, but HAVING can.
81. Can you use aggregate functions without GROUP BY?
Yes, aggregate functions without GROUP BY operate on all rows as a single group, returning one result for the entire table.
82. How do you count distinct values?
Use COUNT(DISTINCT column): SELECT COUNT(DISTINCT department) FROM employees; counts unique departments.
83. How do you find the second highest salary?
Use: SELECT MAX(salary) FROM employees WHERE salary < (SELECT MAX(salary) FROM employees); or use LIMIT/OFFSET approaches.
84. Write a query to find total sales by product.
SELECT product_name, SUM(quantity * price) as total_sales FROM sales GROUP BY product_name ORDER BY total_sales DESC;.
85. How do you find departments with more than 0 employees?
SELECT department, COUNT(*) as emp_count FROM employees GROUP BY department HAVING COUNT(*) > 0;.
String Functions
86. What is the CONCAT() function?
CONCAT() joins two or more strings together: SELECT CONCAT(first_name, ‘ ‘, last_name) as full_name FROM employees;.
87. What is the SUBSTRING() function?
SUBSTRING() extracts a portion of a string: SUBSTRING(string, start_position, length) returns characters from the specified position.
88. What is the REPLACE() function?
REPLACE() replaces occurrences of a substring with another: REPLACE(column_name, ‘old_text’, ‘new_text’).
89. What is the LENGTH() or LEN() function?
LENGTH() (MySQL) or LEN() (SQL Server) returns the number of characters in a string: SELECT LENGTH(name) FROM employees;.
90. What is the UPPER() function?
UPPER() converts all characters in a string to uppercase: SELECT UPPER(name) FROM employees;.
91. What is the LOWER() function?
LOWER() converts all characters in a string to lowercase: SELECT LOWER(email) FROM users;.
92. What is the TRIM() function?
TRIM() removes leading and trailing spaces from a string: SELECT TRIM(column_name) FROM table_name;.
93. What is the LEFT() function?
LEFT() returns a specified number of characters from the left side of a string: LEFT(string, number_of_characters).
94. What is the RIGHT() function?
RIGHT() returns a specified number of characters from the right side of a string: RIGHT(string, number_of_characters).
95. What is the CHARINDEX() or INSTR() function?
CHARINDEX() (SQL Server) or INSTR() (MySQL) returns the position of a substring within a string: CHARINDEX(‘substring’, string).
Joins and Set Operations
Introduction to Joins
96. What is a JOIN in SQL?
JOIN combines rows from two or more tables based on a related column, enabling retrieval of data distributed across multiple tables.
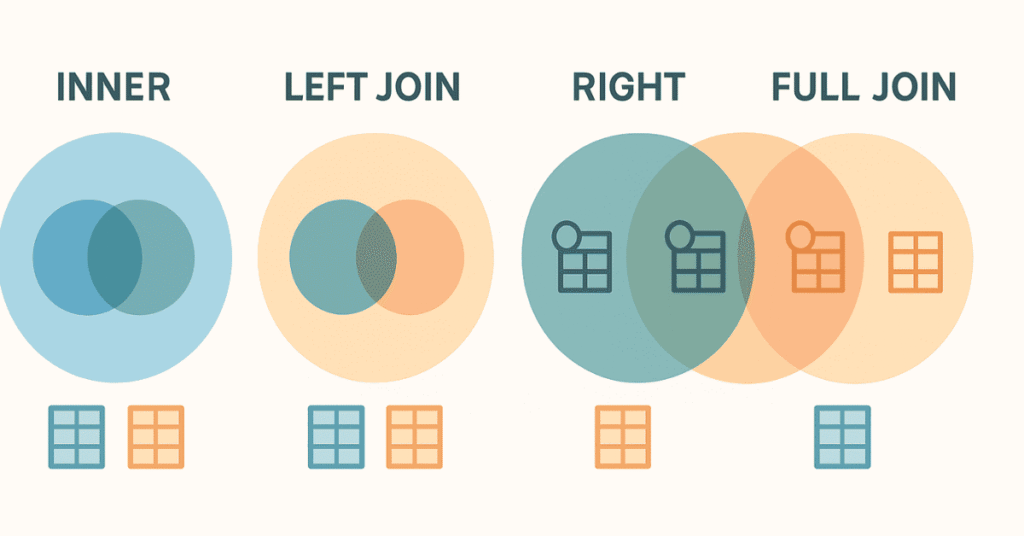
97. What are the different types of JOINs?
The main types are INNER JOIN, LEFT JOIN (LEFT OUTER JOIN), RIGHT JOIN (RIGHT OUTER JOIN), FULL JOIN (FULL OUTER JOIN), and CROSS JOIN.
98. What is an INNER JOIN?
INNER JOIN returns only matching rows from both tables based on the join condition, excluding non-matching rows: SELECT * FROM table INNER JOIN table2 ON table.id = table2.id;.
99. What is a LEFT JOIN?
LEFT JOIN returns all rows from the left table and matching rows from the right table; non-matching right table rows show NULL: SELECT * FROM table LEFT JOIN table2 ON table.id = table2.id;.
100. What is a RIGHT JOIN?
RIGHT JOIN returns all rows from the right table and matching rows from the left table; non-matching left table rows show NULL.
101. What is a FULL OUTER JOIN?
FULL OUTER JOIN returns all rows from both tables, with NULLs where there’s no match, combining results of LEFT and RIGHT joins.
102. What is a CROSS JOIN?
CROSS JOIN produces a Cartesian product, combining each row from the first table with every row from the second table, resulting in rows = table_rows × table2_rows.
103. What is a SELF JOIN?
SELF JOIN joins a table to itself, useful for comparing rows within the same table: SELECT a.name, b.name FROM employees a JOIN employees b ON a.manager_id = b.employee_id;.
104. When would you use a LEFT JOIN instead of INNER JOIN?
Use LEFT JOIN when you need all records from the left table regardless of matches, such as showing all customers even those without orders.
105. Can you join more than two tables?
Yes, you can chain multiple JOIN operations: SELECT * FROM table JOIN table2 ON … JOIN table3 ON …;.
106. What is the difference between JOIN and UNION?
JOIN combines columns from multiple tables horizontally (adding columns), while UNION combines result sets vertically (adding rows) from multiple SELECT statements.
107. Write a query to join employees and departments tables.
SELECT e.employee_name, e.salary, d.department_name FROM employees e INNER JOIN departments d ON e.department_id = d.department_id;.
108. What is an equi-join?
An equi-join uses equality (=) operator in the join condition, the most common join type: ON table.column = table2.column.
109. What is a non-equi join?
A non-equi join uses comparison operators other than equality (>, <, >=, <=, BETWEEN) in the join condition.
110. How do you handle NULL values in joins?
Use COALESCE or ISNULL functions to replace NULLs, or include NULL checking in WHERE clause: WHERE column IS NOT NULL.
Data Selection with Joins
111. What is the SELECT DISTINCT keyword?
DISTINCT removes duplicate rows from the result set: SELECT DISTINCT column_name FROM table_name;.
112. How do you select data from joined tables with aliases?
Use table aliases for clarity: SELECT e.name, d.dept_name FROM employees e JOIN departments d ON e.dept_id = d.id;.
113. Write a query to find employees with no department assigned.
SELECT e.* FROM employees e LEFT JOIN departments d ON e.department_id = d.id WHERE d.id IS NULL;.
114. How do you find records that exist in one table but not another?
Use LEFT JOIN with NULL check or NOT EXISTS: SELECT * FROM table t LEFT JOIN table2 t2 ON t.id = t2.id WHERE t2.id IS NULL;.
115. What is the purpose of table aliases?
Aliases provide shorter names for tables, improve query readability, and are essential for self-joins: FROM employees AS e.
Set Operations
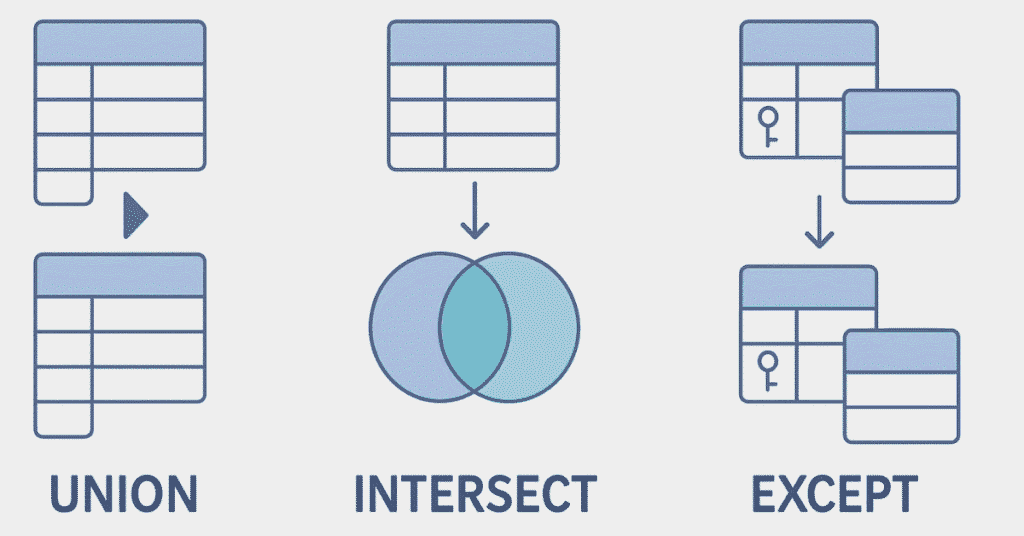
116. What is UNION in SQL?
UNION combines result sets of two or more SELECT statements, removing duplicates, requiring same number of columns with compatible data types.
117. What is the difference between UNION and UNION ALL?
UNION removes duplicate rows from the combined result, while UNION ALL includes all rows including duplicates, making UNION ALL faster.
118. When would you use UNION ALL instead of UNION?
Use UNION ALL when duplicates are acceptable or when you know duplicates don’t exist, as it’s faster without the overhead of removing duplicates.
119. What is INTERSECT?
INTERSECT returns only rows that appear in both result sets: SELECT column FROM table INTERSECT SELECT column FROM table2;.
120. What is EXCEPT (or MINUS)?
EXCEPT returns rows from the first query that don’t appear in the second query, showing the difference between result sets.
121. Can UNION combine tables with different numbers of columns?
No, all SELECT statements in UNION must have the same number of columns with compatible data types in the same order.
122. Write a query using UNION to combine active and inactive users.
SELECT user_id, name, ‘Active’ as status FROM active_users UNION SELECT user_id, name, ‘Inactive’ as status FROM inactive_users;.
123. How do you sort results after using UNION?
Place ORDER BY at the end of the entire UNION query: (SELECT …) UNION (SELECT …) ORDER BY column_name;.
124. What are the requirements for set operations?
All queries must have the same number of columns, corresponding columns must have compatible data types, and column names from the first query are used.
125. Can you use WHERE with UNION?
Yes, each SELECT statement in UNION can have its own WHERE clause: (SELECT * FROM t WHERE condition) UNION (SELECT * FROM t2 WHERE condition2);.
Advanced SQL Questions
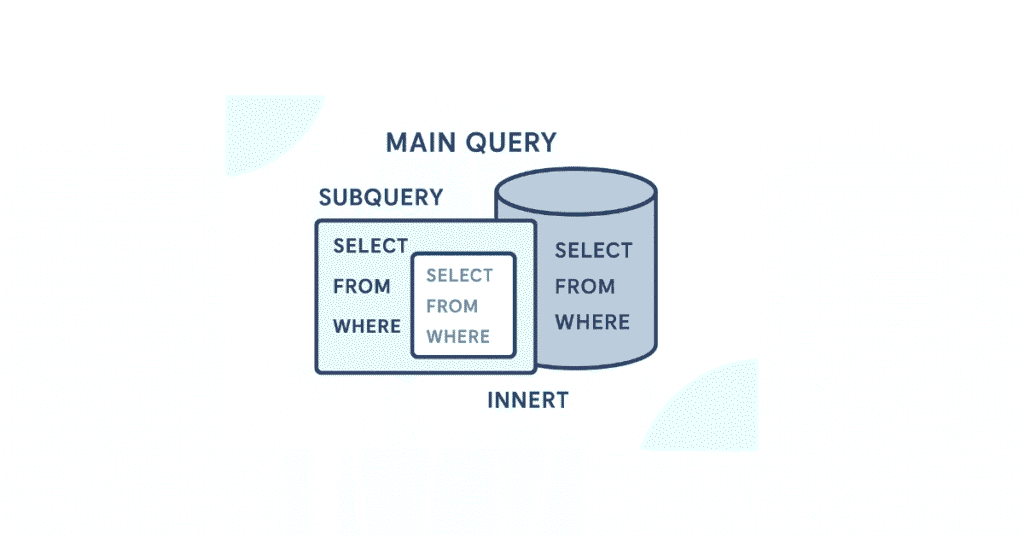
Subqueries
126. What is a subquery?
A subquery is a query nested inside another query (SELECT, INSERT, UPDATE, or DELETE), used to return data that will be used by the main query.
127. What are the types of subqueries?
Single-row subquery (returns one row), multiple-row subquery (returns multiple rows), multiple-column subquery, and correlated subquery (references outer query).
128. What is a correlated subquery?
A correlated subquery references columns from the outer query and is executed once for each row processed by the outer query.
129. What is the difference between a subquery and a join?
Subqueries are nested queries that can return single values or sets, while joins combine columns from multiple tables; joins often perform better but subqueries can be more readable.
130. When should you use a subquery instead of a join?
Use subqueries when you need to filter based on aggregate results, check existence, or when the logic is clearer with nested queries.
131. What is a nested subquery?
A nested subquery is a subquery contained within another subquery, creating multiple levels of nesting.
132. Write a query to find employees earning more than average salary.
SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);.
133. How do you use IN with a subquery?
SELECT * FROM employees WHERE department_id IN (SELECT id FROM departments WHERE location = ‘Delhi’);.
134. What is the EXISTS operator?
EXISTS checks if a subquery returns any rows, returning TRUE if at least one row exists: WHERE EXISTS (SELECT FROM table WHERE condition).
135. What is the difference between IN and EXISTS?
EXISTS stops processing once a match is found (faster for large datasets), while IN compares all values; EXISTS works better with correlated subqueries.
Views
136. What is a view in SQL?
A view is a virtual table based on a SELECT query result, stored as a named query that can be referenced like a table.
137. How do you create a view?
Use CREATE VIEW: CREATE VIEW view_name AS SELECT column, column2 FROM table_name WHERE condition;.
138. What are the advantages of using views?
Views simplify complex queries, provide data security by restricting access to specific columns, enable data abstraction, and support consistent data presentation.
139. Can you update data through a view?
Yes, but only simple views without joins, aggregates, DISTINCT, or GROUP BY can be updated; complex views are read-only.
140. How do you drop a view?
Use DROP VIEW: DROP VIEW view_name;.
Indexes
141. What is an index in SQL?
An index is a database object that improves query performance by providing quick access to rows, similar to a book’s index pointing to specific pages.
142. What are the types of indexes?
Clustered index (determines physical order of data, one per table), non-clustered index (separate structure with pointers, multiple per table), unique index, and composite index.
143. When should you create an index?
Create indexes on columns frequently used in WHERE, JOIN, ORDER BY clauses, or columns with high selectivity and frequent search operations.
144. What are the disadvantages of indexes?
Indexes consume storage space, slow down INSERT, UPDATE, DELETE operations, and require maintenance; over-indexing can degrade performance.
145. How do you create an index?
Use CREATE INDEX: CREATE INDEX index_name ON table_name(column_name);.
Transactions
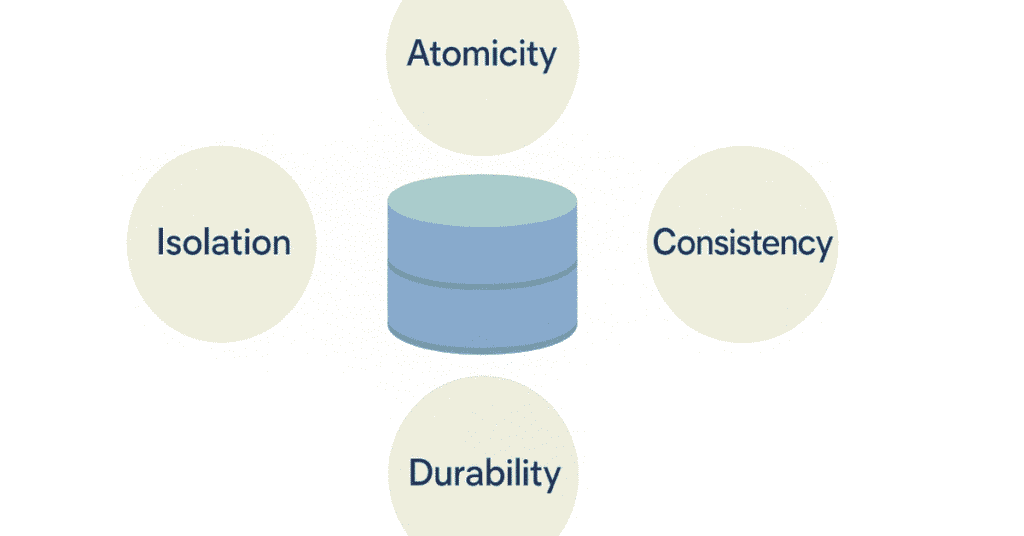
146. What is a transaction in SQL?
A transaction is a sequence of one or more SQL operations executed as a single unit of work, either all succeeding or all failing together.
147. What are ACID properties?
ACID stands for Atomicity (all-or-nothing), Consistency (maintains data integrity), Isolation (concurrent transactions don’t interfere), and Durability (committed changes are permanent).
148. What is the COMMIT command?
COMMIT saves all changes made during the current transaction permanently to the database.
149. What is the ROLLBACK command?
ROLLBACK undoes all changes made during the current transaction, returning the database to its previous state.
150. What is a SAVEPOINT?
SAVEPOINT creates a point within a transaction to which you can later rollback without affecting the entire transaction.
151. What is a deadlock?
A deadlock occurs when two or more transactions wait indefinitely for each other to release locks, preventing all from proceeding.
152. How do you prevent deadlocks?
Access objects in the same order, keep transactions short, use appropriate isolation levels, implement timeout mechanisms, and use lock hints carefully.
153. What are isolation levels?
Isolation levels control how transaction changes are visible to other concurrent transactions: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE.
154. What is the difference between COMMIT and SAVEPOINT?
COMMIT permanently saves all changes and ends the transaction, while SAVEPOINT creates a checkpoint within an active transaction for partial rollback.
155. Can you rollback after a COMMIT?
No, once COMMIT is executed, changes are permanent and cannot be rolled back.
Stored Procedures and Functions
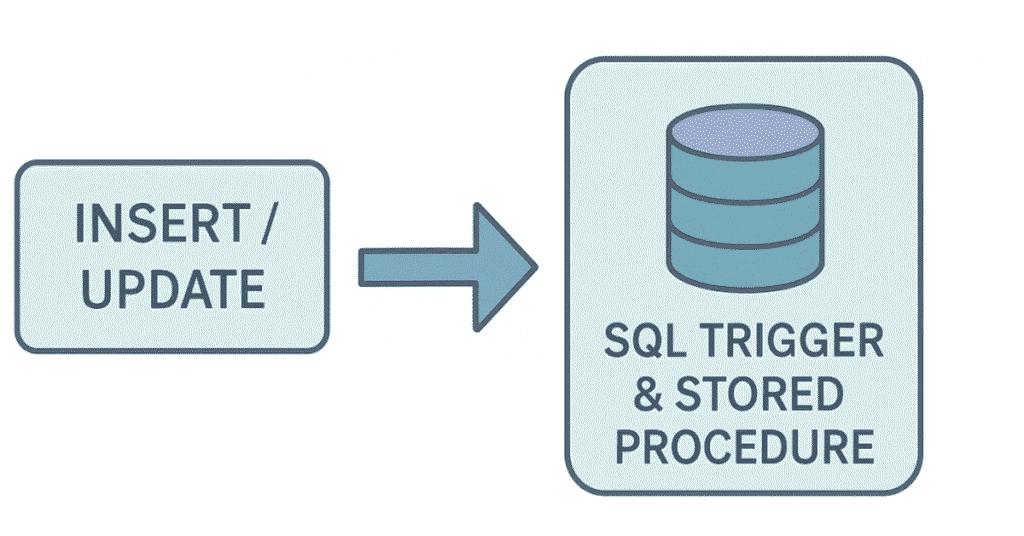
156. What is a stored procedure?
A stored procedure is a precompiled set of SQL statements stored in the database, executed as a unit, accepting parameters and returning results.
157. What are the advantages of stored procedures?
Improved performance (precompiled), code reusability, reduced network traffic, enhanced security, centralized business logic, and easier maintenance.
158. How do you create a stored procedure in SQL Server?
CREATE PROCEDURE procedure_name
@parameter datatype,
@parameter2 datatype
AS
BEGIN
— SQL statements
END
159. How do you execute a stored procedure?
Use EXECUTE or EXEC: EXEC procedure_name @param = value, @param2 = value2;.
160. What is a trigger?
A trigger is a special stored procedure automatically executed in response to specific events (INSERT, UPDATE, DELETE) on a table.
161. What are the types of triggers?
BEFORE triggers (execute before the event), AFTER triggers (execute after the event), and INSTEAD OF triggers (execute instead of the event).
162. What is a user-defined function?
A user-defined function is a routine that accepts parameters, performs calculations or operations, and returns a single value or table.
163. What is the difference between stored procedures and functions?
Functions must return a value and can be used in SELECT statements; procedures may or may not return values and cannot be used in SELECT; procedures can modify database state more freely.
164. What are scalar functions?
Scalar functions return a single value based on input parameters, such as mathematical functions (ABS, ROUND) or string functions (LEN, SUBSTRING).
165. Can functions modify data?
User-defined functions generally shouldn’t modify database data (INSERT, UPDATE, DELETE); stored procedures are designed for data modification.
Advanced Query Techniques
166. What is a window function?
Window functions perform calculations across a set of table rows related to the current row, without grouping rows into a single output row.
167. What is the ROW_NUMBER() function?
ROW_NUMBER() assigns a unique sequential integer to rows within a partition: ROW_NUMBER() OVER (PARTITION BY column ORDER BY column).
168. What is the RANK() function?
RANK() assigns ranks with gaps after tied values: if two rows tie for rank , the next rank is 3.
169. What is the DENSE_RANK() function?
DENSE_RANK() assigns ranks without gaps: if two rows tie for rank , the next rank is 2.
170. What is the difference between RANK() and DENSE_RANK()?
RANK() leaves gaps in ranking after ties, while DENSE_RANK() provides consecutive ranks without gaps.
171. What is PARTITION BY?
PARTITION BY divides the result set into partitions where window functions are applied independently to each partition.
172. What is a CTE (Common Table Expression)?
A CTE is a temporary named result set defined within a query using WITH clause, improving readability and enabling recursive queries.
173. How do you create a CTE?
WITH cte_name AS (
SELECT column, column2 FROM table_name WHERE condition
)
SELECT * FROM cte_name;
174. What is a recursive CTE?
A recursive CTE references itself to process hierarchical or tree-structured data, such as organizational charts or bill of materials.
175. Write a recursive CTE to display employee hierarchy.
WITH EmployeeHierarchy AS (
SELECT employee_id, name, manager_id, AS level
FROM employees WHERE manager_id IS NULL
UNION ALL
SELECT e.employee_id, e.name, e.manager_id, eh.level +
FROM employees e
JOIN EmployeeHierarchy eh ON e.manager_id = eh.employee_id
)
SELECT * FROM EmployeeHierarchy;
176. What is the CASE statement?
CASE provides conditional logic in SQL, returning different values based on conditions: CASE WHEN condition THEN result ELSE default END.
177. Write a query using CASE to categorize salaries.
SELECT name, salary,
CASE
WHEN salary < 30000 THEN ‘Low’
WHEN salary BETWEEN 30000 AND 60000 THEN ‘Medium’
ELSE ‘High’
END AS salary_category
FROM employees;
178. What is the COALESCE function?
COALESCE returns the first non-NULL value from a list: COALESCE(column, column2, ‘default’) returns column if not NULL, else column2, else ‘default’.
179. What is the NULLIF function?
NULLIF returns NULL if two expressions are equal, otherwise returns the first expression: NULLIF(expression, expression2).
180. How do you handle division by zero?
Use NULLIF: column / NULLIF(column2, 0) returns NULL instead of error when column2 is zero.
Date and Time Functions
181. What are common date functions?
GETDATE() (current date/time), DATEADD() (add intervals), DATEDIFF() (difference between dates), YEAR(), MONTH(), DAY(), DATEPART().
182. How do you extract the year from a date?
Use YEAR(): SELECT YEAR(order_date) FROM orders; or DATEPART(): DATEPART(YEAR, order_date).
183. How do you add days to a date?
Use DATEADD(): DATEADD(DAY, 7, order_date) adds 7 days to order_date.
184. How do you calculate the difference between two dates?
Use DATEDIFF(): DATEDIFF(DAY, start_date, end_date) returns the number of days between dates.
185. How do you format a date?
Use CONVERT() or FORMAT(): FORMAT(date_column, ‘dd-MM-yyyy’) or CONVERT(VARCHAR, date_column, 03).
Data Integrity and Constraints
186. What is a CHECK constraint?
CHECK enforces domain integrity by limiting values in a column: CHECK (age >= 8) ensures age is at least 8.
187. What is a DEFAULT constraint?
DEFAULT provides a default value for a column when no value is specified during INSERT: column_name INT DEFAULT 0.
188. What is a NOT NULL constraint?
NOT NULL ensures a column cannot contain NULL values, requiring a value for every row.
189. How do you add a constraint to an existing table?
Use ALTER TABLE: ALTER TABLE table_name ADD CONSTRAINT constraint_name CHECK (condition);.
190. How do you drop a constraint?
Use ALTER TABLE: ALTER TABLE table_name DROP CONSTRAINT constraint_name;.
Performance and Optimization
191. What is query optimization?
Query optimization involves improving query performance through better query structure, proper indexing, avoiding unnecessary operations, and efficient join strategies.
192. What is an execution plan?
An execution plan shows how the database engine executes a query, including operations performed, order of execution, and resource usage.
193. How do you view an execution plan?
Use EXPLAIN (MySQL) or SET SHOWPLAN_ALL ON (SQL Server) or the graphical execution plan feature in SSMS.
194. What are some query optimization techniques?
Use appropriate indexes, avoid SELECT *, limit result sets, use EXISTS instead of IN for subqueries, optimize joins, avoid functions on indexed columns in WHERE, use proper data types.
195. Why is SELECT * considered bad practice?
SELECT * retrieves unnecessary columns, increases network traffic and memory usage, reduces query performance, and makes code less maintainable.
196. What is index fragmentation?
Index fragmentation occurs when index pages are not contiguous, causing the database to read more pages than necessary, degrading performance.
197. How do you rebuild an index?
Use: ALTER INDEX index_name ON table_name REBUILD; to reorganize and defragment the index.
198. What is a covering index?
A covering index contains all columns needed by a query, allowing the database to retrieve data entirely from the index without accessing the table.
199. What is database normalization?
Normalization organizes tables to reduce redundancy and dependency by dividing large tables into smaller related tables and defining relationships.
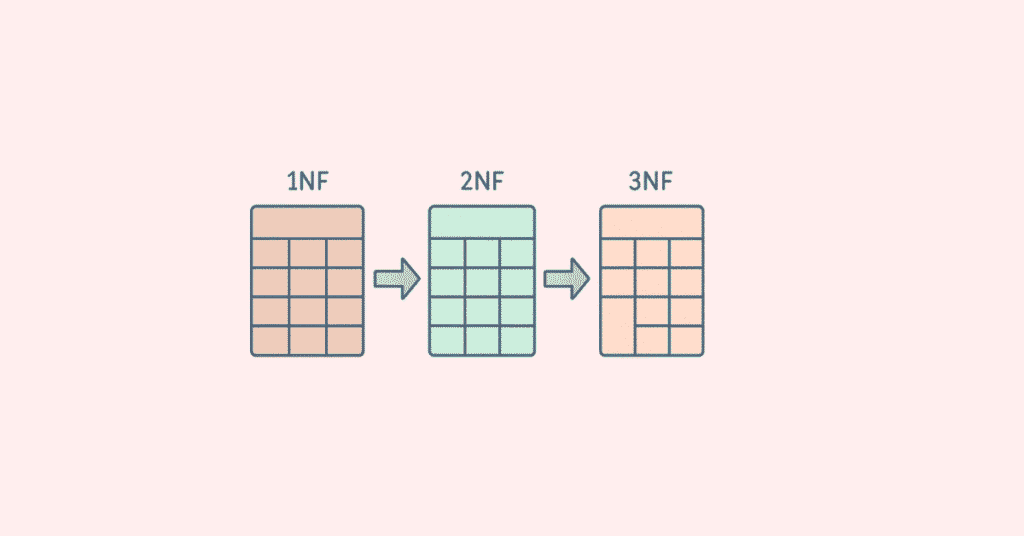
200. What are the normal forms?
First Normal Form (NF): atomic values, no repeating groups; Second Normal Form (2NF): NF + no partial dependencies; Third Normal Form (3NF): 2NF + no transitive dependencies; Boyce-Codd Normal Form (BCNF): stricter 3NF.
201. What is denormalization?
Denormalization deliberately introduces redundancy by combining tables to improve read performance, used in data warehouses and reporting systems.
202. When would you denormalize a database?
When read performance is critical, query complexity needs reduction, reporting requires aggregated data, or in OLAP systems where updates are infrequent.
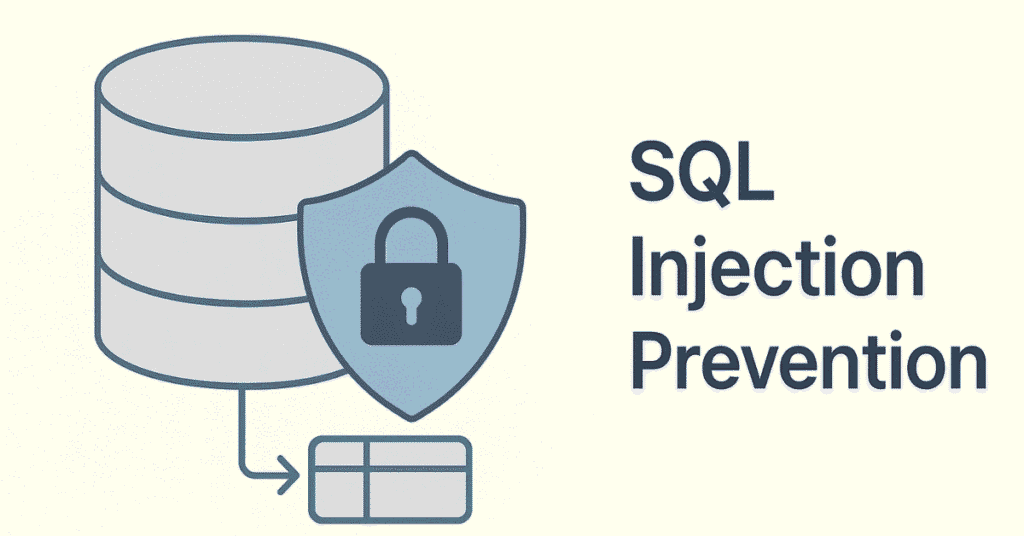
203. What is SQL injection?
SQL injection is a security vulnerability where malicious SQL code is inserted into input fields, potentially exposing, modifying, or deleting database data.
204. How do you prevent SQL injection?
Use parameterized queries/prepared statements, validate and sanitize input, use stored procedures, apply least privilege principle, and avoid dynamic SQL when possible.
205. What is the N+ query problem?
N+ problem occurs when one query retrieves main records, then N additional queries fetch related data for each record, causing performance issues.
🎯 Build a solid SQL foundation!
Enroll in our Beginner SQL Course to learn with real-world projects.
Module 2: Self-Preparation Prompts Using ChatGPT (50 Prompts)
50 Self-Preparation Prompts Using ChatGPT
These prompts are designed for students preparing for SQL and database interviews, enabling systematic self-study and practice using ChatGPT as a learning companion.
Coding and Query Practice Prompts
1. SQL Query Problem Solving Practice
“I’m preparing for SQL database interviews. Generate a medium-difficulty problem requiring implementation of joins, subqueries, aggregate functions, and window functions. Include problem statement with database schema, sample data, constraints, expected output, and edge cases. After I submit my SQL solution, analyze query performance, suggest optimizations using indexes or query restructuring, and explain execution plans.”
2. Database Design Debugging Challenge
“Present a database schema with subtle issues like missing foreign keys, improper normalization, data redundancy, inefficient indexing, or poor data type choices. Don’t reveal issues initially. Let me identify problems through schema analysis, then provide detailed explanations of design flaws, normalization violations, and best practices for preventing similar issues in production databases.”
3. SQL Pattern Recognition and Mastery
“Explain the window functions / correlated subqueries / recursive CTEs / pivot operations pattern with detailed SQL implementations. Provide 3 progressively difficult problems using this pattern with different business scenarios. For each problem, wait for my SQL solution before revealing the optimal approach with detailed performance analysis and execution plan explanations.”
4. Power BI + SQL Integration Deep Dive
“I need to master connecting Power BI with SQL databases, writing optimized DAX queries that complement SQL, creating efficient data models, and implementing incremental refresh strategies. Create a comprehensive learning path with practical exercises building on each other. Include real-world dashboard scenarios, common performance pitfalls, and hands-on SQL + Power BI challenges.”
5. Real-World Database Scenario Design
“Create a realistic database design scenario for an e-commerce order system / hospital management system / banking application. Guide me through requirements analysis, entity identification, relationship mapping, normalization to 3NF, indexing strategy, and sample query writing. Ask clarifying questions about data volume, query patterns, and performance requirements before I propose my design.”
Technical Concept Clarification Prompts
6. Database Indexing Deep Dive
“I’m confused about clustered vs non-clustered indexes, composite indexes, covering indexes, index fragmentation, and when to use which type. Explain as if teaching an intermediate SQL developer. Use real-world analogies, provide code examples demonstrating performance differences with EXPLAIN PLAN, and show JVM tuning recommendations. Then quiz me with 3 scenario-based indexing questions.”
7. SQL Join Performance Optimization
“Explain the N+ query problem in SQL contexts, INNER JOIN vs EXISTS performance differences, join order optimization, and hash join vs nested loop join strategies. Provide code examples showing performance issues and optimized solutions. Create 5 challenging exercises with actual execution times demonstrating these concepts.”
8. Transaction Management and Concurrency Mastery
“Deep dive into ACID properties, transaction isolation levels (READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE), deadlock detection and prevention, and optimistic vs pessimistic locking. Explain with real-world banking transaction examples, then present 5 concurrency problems requiring proper transaction handling. Evaluate my solutions for correctness, performance, and data integrity.”
9. SQL Query Optimization Best Practices
“I need to master query optimization techniques in SQL Server. Cover execution plan analysis, query hints, avoiding table scans, proper use of WHERE vs HAVING, SET operations efficiency, and statistics updates. Provide a poorly performing query exercise where I must optimize through indexing, rewriting, or restructuring, then critique my optimization decisions.”
10. Database Normalization and Denormalization
“For each normal form (NF, 2NF, 3NF, BCNF), explain the problem it solves with real-world examples. Show database schema transformations at each normalization stage. Then present a denormalized data warehouse scenario explaining when and why denormalization is beneficial. Present a real-world e-commerce schema requiring normalization and evaluate my design.”
Mock Interview Simulation Prompts
11. SQL Technical Screening Round
“Act as an interviewer for a SQL Database Developer position at a data analytics company. Conduct a 45-minute technical screening covering SQL fundamentals (SELECT, JOIN, GROUP BY), aggregate functions, subqueries, and basic indexing concepts. Ask one question at a time, evaluate my responses comprehensively, and provide detailed feedback on technical accuracy, query efficiency, and communication skills.”
12. Live SQL Coding Interview
“Simulate a live SQL coding interview presenting a medium-hard query problem involving multiple tables, complex joins, window functions, and CTEs. Give 30 minutes to solve. As I explain my approach, ask clarifying questions about data assumptions and hint if I’m stuck. After submission, critique solution efficiency, query readability, edge case handling, and alternative approaches.”
13. Database Design System Interview
“Conduct a database design interview for designing a social media platform / online learning management system / e-commerce marketplace. Guide through requirements gathering, entity-relationship modeling, cardinality decisions, normalization vs denormalization trade-offs, partitioning strategies, and backup/recovery planning. Challenge my decisions with follow-up questions about scalability and data integrity.”
14. SQL Performance Tuning Review
“Present a SQL database with performance issues like slow queries, missing indexes, table scans, parameter sniffing, and statistics problems. Give 20 minutes to identify bottlenecks using execution plans and DMVs (Dynamic Management Views). Propose optimized solutions with proper indexing strategies, query rewrites, and SQL Server configuration tuning.”
15. Data Warehouse Interview Simulation
“Conduct an interview on data warehouse design for a business intelligence project. Cover star schema vs snowflake schema, dimension tables and fact tables, slowly changing dimensions (SCD Types , 2, 3), ETL processes, and aggregate tables. Present a retail business scenario requiring data warehouse design and evaluate my dimensional modeling approach.”
Query Review and Feedback Prompts
16. SQL Query Quality Assessment
“Review this SQL query for proper join syntax, appropriate use of WHERE vs HAVING, efficient aggregate functions, subquery optimization, readability with proper formatting and aliasing, and avoidance of anti-patterns like SELECT * or implicit joins. Identify performance bottlenecks, security issues (SQL injection risks), and provide refactored version with explanations.”
17. Database Security Vulnerability Analysis
“Analyze this SQL query and database design for security vulnerabilities including SQL injection points, improper access controls, missing encryption for sensitive data, exposed connection strings, and lack of parameterized queries. Explain each vulnerability’s impact and provide secure implementation using prepared statements, stored procedures, and proper authentication.”
18. SQL Stored Procedure Review
“Review this stored procedure checking for proper error handling with TRY-CATCH blocks, transaction management with COMMIT/ROLLBACK, parameter validation, efficient logic flow, and reusability. Identify anti-patterns like cursors where set-based operations would work, missing indexes for queries, and suggest improvements using modern SQL Server features.”
19. Query Execution Plan Analysis
“Analyze these query execution plans identifying table scans, index seeks vs index scans, missing index warnings, expensive operators (sorts, hash matches), and parallelism issues. Explain bottlenecks using metrics like estimated rows vs actual rows, CPU time, logical reads. Provide optimized versions with appropriate indexes and query rewrites showing performance improvements.”
20. Database Testing Strategy Evaluation
“Review this database testing approach covering unit tests for stored procedures, integration tests for multi-table operations, data validation tests, and performance benchmarks. Evaluate test data quality, edge case coverage, transaction rollback after tests, and use of database mocking tools. Suggest improvements using SQL Server unit testing frameworks and automated testing strategies.”
Problem-Solving Strategy Prompts
21. Debugging Database Performance Issues
“Simulate a production database issue with slow query response times, high CPU usage, blocking and deadlocks, or tempdb contention. Guide me through analyzing SQL Server DMVs, execution plans, wait statistics, and blocking chains. Don’t give solutions immediately—ask diagnostic questions helping me identify root causes systematically like a DBA troubleshooting in real-time.”
22. Multiple SQL Solution Approaches
“For this business requirement (e.g., finding top 5 customers by revenue across multiple years), generate 3 different SQL solutions: basic approach using subqueries, optimized approach using window functions (ROW_NUMBER, RANK), and highly performant approach with indexed views or materialized results. Compare trade-offs in readability, performance, and maintainability.”
23. Refactoring Legacy Database Code
“Present legacy SQL code with poor structure including cursor-based logic instead of set-based operations, lack of parameterization, hard-coded values, missing error handling, and no indexing strategy. Guide me through refactoring to modern T-SQL with CTEs, window functions, stored procedures with parameters, comprehensive error handling, and proper indexing.”
24. Database Technology Decision Making
“For a specific technical decision like SQL Server vs PostgreSQL vs MySQL, relational vs NoSQL, on-premise vs cloud database, present trade-offs considering data volume, transaction requirements, scalability needs, budget constraints, and team expertise. Help me make a justified decision with supporting technical reasoning.”
25. SQL Server vs MySQL Comparison
“Present scenarios where I must choose between SQL Server, MySQL, PostgreSQL, or cloud-managed databases (Azure SQL, RDS). Discuss licensing costs, enterprise features (Always On, replication), performance characteristics, developer familiarity, tool ecosystem, and cloud integration. Help evaluate based on project constraints and organizational needs.”
Technical Communication Prompts
26. Explaining Complex Database Concepts Simply
“I need to explain database normalization / ACID properties / indexing strategies / query optimization to a junior developer, business analyst, and technical project manager. Evaluate each explanation for appropriate technical depth, use of relatable analogies, clarity without jargon, and engagement. Provide improved versions tailored to each audience’s background.”
27. SQL Technical Documentation Writing
“Review my database documentation including data dictionary, ER diagrams, stored procedure documentation, indexing strategy guide, and backup/recovery procedures. Evaluate for completeness, clarity, code examples with sample data, setup instructions, troubleshooting guides, and versioning. Suggest improvements following enterprise database documentation standards.”
28. Database Architecture Presentation Preparation
“I’m presenting a database architecture design to technical leadership covering schema design, partitioning strategy, high availability setup, disaster recovery plan, and performance monitoring. Prepare me for tough questions about data consistency, backup windows, RTO/RPO objectives, scaling strategies, and cost optimization. Simulate challenging questions and evaluate my technical responses.”
29. SQL Code Review Communication
“Simulate a code review where I must provide constructive feedback on poorly written SQL including missing indexes, inefficient joins, lack of error handling, SQL injection vulnerabilities, and unreadable formatting. Teach me to identify issues diplomatically, suggest alternatives with clear reasoning, balance perfectionism with pragmatism, and foster learning.”
30. Database Requirement Clarification
“Present intentionally ambiguous database design requirements about data volumes, query patterns, reporting needs, and data retention policies. Train me to ask clarifying questions about expected transaction volume, concurrent users, data growth rate, compliance requirements, and performance SLAs before proposing database architecture.”
Specialized SQL Topics
31. Advanced SQL Server Features
“Deep dive into SQL Server advanced features including indexed views for query performance, columnstore indexes for analytics workloads, in-memory OLTP for high-throughput scenarios, temporal tables for historical tracking, and data compression. Create 0 scenario-based requirements and evaluate my implementations for correctness and performance benefits.”
32. SQL + Power BI Integration Best Practices
“Guide me through optimal Power BI and SQL integration covering DirectQuery vs Import mode trade-offs, query folding for performance, incremental refresh configuration, RLS (Row-Level Security) implementation, and parameterized queries. Present real-world dashboard scenarios requiring efficient SQL backend design and evaluate my data modeling decisions.”
33. Cloud Database Migration Strategy
“Explain migrating on-premise SQL Server to Azure SQL Database / AWS RDS including compatibility assessment, migration tools (Azure Data Migration Service, AWS DMS), schema conversion, performance tuning for cloud, cost optimization, and high availability configuration. Walk me through end-to-end migration plan with proper testing and rollback strategies.”
34. SQL Query Performance Profiling
“Present a slow-performing SQL database requiring systematic optimization. Guide through profiling using SQL Server Profiler / Extended Events, analyzing wait statistics, identifying expensive queries using DMVs, examining index usage statistics, and monitoring tempdb contention. Help identify bottlenecks and implement performance improvements with before/after metrics.”
35. Database DevOps and CI/CD
“Design a database CI/CD pipeline using tools like Redgate, SSDT (SQL Server Data Tools), or Flyway for version control, automated testing of stored procedures and functions, schema comparison and deployment, rollback strategies, and deployment to multiple environments (dev, staging, production). Include database testing automation and deployment approval workflows.”
Progressive Learning Prompts
36. 90-Day SQL Mastery Plan
“Create a structured 90-day plan covering SQL fundamentals (weeks -2), advanced querying with joins and subqueries (weeks 3-4), indexing and performance tuning (weeks 5-6), stored procedures and functions (weeks 7-8), transactions and concurrency (week 9), data warehousing concepts (weeks 0-), Power BI integration (week 2). Include daily goals, practice queries, and weekly assessments.”
37. SQL Problem-Solving Strategy Development
“I’m solving SQL problems on platforms like LeetCode, HackerRank, and SQLZoo. Help me develop a strategy for categorizing problems by patterns (aggregation, joins, window functions, recursive CTEs), tracking progress with difficulty levels, and learning from mistakes. Review my solutions providing query optimization improvements, alternative approaches, and pattern recognition insights.”
38. Building SQL Portfolio Project
“Guide me in building a comprehensive SQL database project for a portfolio like e-commerce analytics database, hospital management system, or financial reporting system. At each phase (requirements analysis, ER modeling, schema creation, stored procedures, query optimization, Power BI integration, documentation), explain best practices, review implementation, suggest enhancements demonstrating professional-level work.”
39. Contributing to Open-Source Database Projects
“Prepare me for contributing to open-source SQL tools or database-related projects on GitHub. Guide through finding beginner-friendly issues, understanding database codebases, following contribution guidelines, writing test cases for SQL functions, and creating pull requests. Review my proposed contributions before submission ensuring code quality standards.”
40. SQL Interview Simulation Series
“Conduct 5 progressive SQL mock interviews increasing in difficulty: phone screening (basic SQL), technical deep-dive (complex queries and optimization), database design round, performance tuning challenge, and hiring manager round (behavioral + technical). After each, provide comprehensive feedback on strengths demonstrated, areas needing improvement, specific SQL topics to review, and practice recommendations.”
Real-World Scenario Practice
41. Production Database Incident Response
“Simulate production database incidents including connection pool exhaustion, blocking and deadlocks causing timeouts, tempdb filling up disk space, sudden query performance degradation, or corrupted indexes. Guide me through incident detection using monitoring tools, impact assessment, immediate mitigation (killing sessions, rebuilding indexes), root cause analysis using logs, and long-term preventive fixes.”
42. Database Migration Scenarios
“Present migration scenarios like upgrading SQL Server 204 to 2022, migrating from MySQL to SQL Server, moving from monolithic database to microservices databases, or on-premise to cloud migration. Guide through compatibility assessment, testing strategies, data migration validation, performance comparison, and rollback planning. Evaluate my migration proposals for risks and feasibility.”
43. Cross-Functional Database Collaboration
“Simulate scenarios requiring collaboration with application developers (defining API data requirements), BI analysts (creating optimized views for reporting), DevOps engineers (database deployment automation), and security teams (implementing data encryption and access controls). Teach effective communication, understanding different priorities, and finding technical compromises.”
44. Database Technical Debt Management
“Present a database with technical debt including deprecated stored procedures, missing foreign key constraints, no indexing strategy, lack of documentation, and performance issues. Help me prioritize improvements using impact/effort matrix, estimate time required, create a phased refactoring plan, balance new feature development with debt reduction, and communicate technical needs to stakeholders.”
45. Database Scalability Challenges
“Database experiencing 0x query volume increase, table sizes growing beyond management capacity, increased concurrent connections causing timeouts, and slower response times. Guide through identifying bottlenecks with monitoring tools, implementing read replicas, database sharding strategies, caching layers (Redis), horizontal vs vertical scaling decisions, and load testing. Evaluate solutions for effectiveness and operational complexity.”
Advanced SQL Techniques
46. Recursive Queries and Hierarchical Data
“Teach me recursive CTEs for handling hierarchical data like organizational charts, category trees, bill of materials, or folder structures. Provide 5 progressively complex problems requiring recursive query solutions. Explain termination conditions, performance considerations, and when to use recursive queries vs alternative approaches like materialized path or nested sets.”
47. Window Functions Mastery
“Deep dive into window functions (ROW_NUMBER, RANK, DENSE_RANK, NTILE, LAG, LEAD, FIRST_VALUE, LAST_VALUE) with PARTITION BY and ORDER BY clauses. Create 0 business analytics scenarios requiring window functions for running totals, moving averages, year-over-year comparisons, top N per group, and gap analysis. Evaluate my solutions for correctness and performance.”
48. Dynamic SQL and Parameterization
“Explain when to use dynamic SQL appropriately, how to build safe dynamic queries avoiding SQL injection, using sp_executesql with parameters, handling variable column/table names, and performance implications. Present scenarios requiring dynamic SQL (configurable reporting, dynamic pivot tables, metadata-driven queries) and evaluate my secure implementations.”
49. Query Optimization with Query Hints
“Teach advanced query optimization using SQL Server query hints (FORCE ORDER, OPTIMIZE FOR, RECOMPILE, MAXDOP, INDEX hints) and when each is appropriate. Present poorly performing queries with parameter sniffing issues, suboptimal join orders, or parallelism problems. Guide me through systematic optimization using hints, plan guides, and statistics updates.”
50. JSON and XML Data Handling in SQL
“Explain working with JSON and XML data types in SQL Server including FOR JSON, OPENJSON, JSON_VALUE, JSON_QUERY for JSON processing, and FOR XML, OPENXML, XQuery for XML processing. Create scenarios requiring parsing JSON API responses, generating JSON output for web services, and querying hierarchical XML documents. Evaluate my solutions for correctness and performance.”
💡Apply what you’ve learned!
Practice with SQL Hands-On Exercises & Real How to Guide
Module 3: Communication Skills and Behavioural Interview Preparation
Advanced SQL Techniques
This comprehensive guide prepares SQL Database Analyst/Developer candidates for behavioral and communication aspects of technical interviews, complementing the technical SQL knowledge from Parts.
Understanding the STAR Method
STAR Framework for SQL Professionals
The STAR method structures behavioral responses using Situation (20%), Task (0%), Action (60%), and Result (0%). Focus the majority of the response on actions taken, using “I” rather than “we” to showcase personal contributions. This framework delivers clear, compelling stories demonstrating relevant skills and experiences for SQL Database Developer/Analyst roles.
Structure breakdown for database professionals:
- Situation (20%): Describe the database-related context, business environment, or technical challenge requiring intervention
- Task (0%): Define the specific database problem, performance issue, or data requirement needing resolution
- Action (60%): Detail the SQL queries written, optimization techniques applied, database design decisions made, and collaboration with stakeholders
- Result (0%): Quantify improvements in query performance, data accuracy, reporting efficiency, or business impact
Common Behavioral Questions for SQL Professionals
1. Tell me about a challenging database problem you solved.
Describe a specific technical challenge involving complex query optimization, slow-running reports, data inconsistency issues, or database migration problems. Explain the business impact showing urgency (e.g., “Dashboard load time was 5 minutes affecting executive decision-making”). Detail your analysis using execution plans, index analysis, query statistics, and wait times. Describe multiple approaches considered with trade-offs like adding indexes vs query rewriting vs database denormalization. Highlight SQL-specific solutions implemented such as indexed views, partitioning, query hints, or stored procedures. Quantify outcomes like “Reduced query time from 5 minutes to 8 seconds” or “Improved dashboard refresh rate by 85%”.
2. Describe a time you had to learn a new database technology quickly.
Explain the business need driving the learning requirement such as migration from SQL Server to PostgreSQL, implementing data warehouse with Power BI, or adopting cloud database services. Describe your structured learning approach including official documentation, online tutorials (Udemy, Coursera), practice databases, and consulting experienced colleagues. Detail how knowledge was applied to deliver value through successful migration, optimized queries, or new reporting capabilities. Address challenges encountered like syntax differences, feature gaps, or performance tuning nuances. Demonstrate enthusiasm for continuous learning essential in rapidly evolving database technology landscape.
3. How do you handle disagreements about database design approaches?
Describe a technical debate about normalization vs denormalization decisions, indexing strategies, partitioning approaches, or stored procedure usage. Explain your perspective with technical reasoning backed by performance metrics or best practices. Describe alternative viewpoints from team members and how evidence was gathered through proof-of-concept testing, execution plan analysis, or benchmark comparisons. Detail how you facilitated discussion using data-driven decision making, prototype testing results, and trade-off analysis. Present the resolution reached and positive project impact demonstrating collaboration and professional maturity.
4. Tell me about a time you made a database mistake and how you handled it.
Describe the error honestly such as dropping wrong table, incorrect UPDATE without WHERE clause, missing backup before major change, or deploying untested stored procedure to production. Explain immediate actions taken including assessing data impact, notifying stakeholders transparently, implementing rollback or data recovery procedures. Detail root cause analysis conducted examining why safeguards failed and what process gaps existed. Describe preventive measures established like mandatory WHERE clause reviews, automated backup verification, deployment checklists, or peer review processes. Emphasize lessons learned and how they influenced future database practices demonstrating accountability and growth.
5. Describe working under tight deadlines with multiple database priorities.
Present a high-pressure situation with competing demands such as urgent data extraction for executive presentation, production database issue needing immediate resolution, and scheduled migration project. Explain prioritization framework used including business impact assessment (revenue-affecting vs reporting delays), stakeholder communication about realistic timelines, and task breakdown into manageable pieces. Detail organizational strategies like maintaining priority lists, communicating blockers early, delegating simpler queries to junior team members, and negotiating scope adjustments. Present successful delivery outcomes despite constraints demonstrating time management and composure under pressure.
6. How do you ensure data quality and accuracy in your work?
Discuss data validation practices including constraint implementation (PRIMARY KEY, FOREIGN KEY, CHECK, NOT NULL), data type selection, and referential integrity enforcement. Explain personal standards for query validation such as testing with sample data, verifying joins produce expected row counts, checking NULL handling, and validating aggregate calculations. Describe team practices established including peer review of complex queries, automated testing for stored procedures, data reconciliation processes, and documentation standards. Quantify quality improvements like “Reduced data discrepancy incidents by 70%” or “Achieved 99.9% accuracy in automated reports”.
7. Tell me about a time you mentored someone or helped a colleague.
Describe the mentoring context such as onboarding new analyst to database tools, teaching SQL best practices to junior developer, or helping business analyst write complex queries. Explain the knowledge gap identified and teaching approach taken including hands-on coding sessions, query optimization workshops, or creating reference documentation. Detail how you adapted explanations to learner’s level using analogies for database concepts, visual ER diagrams, or step-by-step query building. Present evidence of mentee’s progress like independently writing complex JOINs, optimizing slow queries, or presenting data insights to stakeholders. This demonstrates leadership potential valued even in individual contributor roles
8. Describe a database project you’re most proud of.
Choose a project demonstrating technical depth and business value such as data warehouse implementation, database performance overhaul, migration to cloud database, or automated reporting system. Explain project scope including data volume, complexity, and your specific role in requirements gathering, design, implementation, or optimization. Detail innovative solutions or technical excellence like dimensional modeling for analytics, creative indexing strategies, efficient ETL processes, or Power BI integration. Quantify results with metrics such as “Processed 50 million records daily,” “Enabled real-time reporting for 200 users,” “Reduced storage costs by 40%,” or “Improved query performance by 0x”. Make the impact tangible and business-relevant.
9. How do you handle receiving critical feedback on your database work?
Describe feedback received about query performance issues, database design decisions, documentation quality, or communication style with specific context. Explain initial reaction focusing on processing feedback objectively, seeking clarification through follow-up questions, and understanding the perspective behind the critique. Detail specific actions taken such as studying query optimization techniques, attending database design workshop, improving code commenting practices, or soliciting follow-up feedback after improvements. Present evidence of improvement like measurably better query performance, positive comments on subsequent work, or expanded responsibilities demonstrating coachability. Hiring managers value candidates who grow from feedback.
10. Explain a complex database concept to non-technical stakeholders.
Describe a situation requiring technical translation such as explaining database normalization benefits to business users, justifying index creation overhead to management, or clarifying data warehouse vs transactional database to product managers. Explain the challenge of bridging knowledge gaps while maintaining technical accuracy. Detail techniques used including business-focused analogies (database indexes like book indexes), visual ER diagrams showing relationships, incremental explanations building from simple concepts, and avoiding technical jargon. Present outcomes like stakeholder understanding achieved, buy-in secured for database improvements, successful project approval, or enhanced collaboration. This skill is crucial for database professionals working across business and technical teams.
Common Behavioral Questions for SQL Professionals
11. Articulating Database Problem-Solving During Interviews
Verbalize your thought process by explaining problem understanding, data analysis approach, query strategy consideration, and optimization trade-offs. Use structured frameworks like “First, I analyze the execution plan… Second, I identify bottlenecks… Third, I consider indexing vs query rewrite approaches”. Start with high-level database architecture before diving into specific SQL syntax when discussing solutions. Explain the “why” behind technical decisions connecting choices to business requirements (reporting speed), data integrity needs (constraints), or maintainability goals (stored procedures). Use clear analogies for complex concepts and check interviewer understanding by pausing for questions.
12. Explaining SQL Queries and Design Decisions
When discussing SQL solutions, explain query logic step-by-step including JOIN reasoning, WHERE clause logic, GROUP BY necessity, and aggregate function choices. Discuss alternative approaches considered such as subquery vs JOIN, window functions vs self-join, or CTE vs temporary table. Explain trade-offs in readability (CTEs more readable), performance (JOINs often faster than subqueries), and maintainability (stored procedures centralize logic). Reference specific SQL Server/MySQL/PostgreSQL features when relevant showing depth of platform knowledge. Connect technical decisions to business outcomes like “I used indexed view because reports run every hour and need sub-second response”.
13. Handling “I Don’t Know” Gracefully
Acknowledge knowledge gaps honestly rather than fabricating answers demonstrating intellectual honesty valued in data-driven roles. Follow immediately with related knowledge or logical approach like “I haven’t used that specific SQL Server feature, but based on my experience with similar indexing patterns, I would approach it by…”. This shows problem-solving resourcefulness and honesty valued in team environments. Alternatively, explain how you would research the answer through official documentation, testing in development environment, or consulting experienced colleagues. Interviewers respect candidates who acknowledge limits while demonstrating learning ability.
14. Active Listening in Technical Database Discussions
Take notes during problem statements capturing data requirements, performance expectations, and business context. Ask clarifying questions before jumping to SQL solutions such as “What’s the expected data volume?”, “How frequently will this query run?”, or “Are there existing indexes on these tables?”. Paraphrase requirements confirming understanding like “So you need daily sales aggregated by region, filtered for last 90 days, with year-over-year comparison?”. This prevents solving the wrong problem and demonstrates attention to detail crucial in database work where small errors have large impacts. Interviewers often provide hints during discussions that active listeners catch.
15. Managing Interview Nervousness
Control anxiety through breathing techniques (inhale 4 counts, hold 4 counts, exhale 4 counts), positive self-talk (“I’m well-prepared”), and reframing nervousness as excitement. If stuck during SQL problem solving, verbalize: “Let me take a moment to think through this query systematically”. Thinking aloud and maintaining composure under pressure impresses interviewers more than silent freezing. Remember that some nervousness is normal and expected even for experienced database professionals. Interviewers evaluate not just technical knowledge but also how candidates handle pressure relevant for production database issues.
Teamwork and Collaboration
16. SQL Code Review Best Practices
Demonstrate openness to feedback on query efficiency, index usage, naming conventions, and commenting practices. Explain how code reviews are learning opportunities to discover new SQL techniques, optimization approaches, or platform features. Describe techniques for delivering tactful feedback such as “Have you considered using a CTE here for readability?” rather than “This subquery is wrong”. Discuss balancing perfectionism with pragmatism knowing when “good enough” queries meet business needs vs when optimization is critical. This reveals collaboration skills and ego management crucial for team success.
17. Contributing to Database Team Knowledge Sharing
Describe initiatives like documenting common query patterns, creating SQL best practices wiki, conducting lunch-and-learn sessions on query optimization, or sharing interesting problems solved in team channels. Explain motivation to help team level up collectively and reduce redundant problem-solving. Discuss how knowledge sharing builds team capability and your reputation as technical resource. Examples include “Created query optimization guide reducing average query tuning time by 30%” or “Mentored 3 analysts on window functions enabling advanced analytics”. Leadership through knowledge contribution valued even in non-management roles.
18. Working in Agile/Cross-Functional Teams
Describe experience with Agile ceremonies including sprint planning (estimating database story points), daily standups (reporting query completion or database blockers), retrospectives (discussing database process improvements), and sprint reviews (demoing new reports or data models). Explain how you contribute to story refinement by clarifying data requirements, estimation by assessing query complexity, and identifying blockers like missing database permissions or data quality issues. Discuss adapting to changing reporting requirements and maintaining velocity under evolving business priorities. Database professionals often work iteratively with analysts and developers requiring Agile adaptability.
19. Cross-Functional Database Collaboration
Share examples of working with business analysts (translating requirements into data models), application developers (defining API data requirements and optimizing database calls), BI analysts (creating optimized views for Power BI/Tableau), and DevOps engineers (database deployment automation and backup strategies). Demonstrate ability to understand different perspectives such as developer preference for denormalized data vs DBA preference for normalization. Explain finding technical compromises like creating materialized views satisfying both performance and integrity needs. Show you communicate technical database concepts appropriately to each audience’s expertise level.
SQL Professional-Specific Behavioral Questions
20. Why did you choose SQL and database work for your career?
Discuss SQL’s strengths including universal applicability across industries, demand for data skills, logical problem-solving nature, and tangible business impact of data work. Explain personal attraction to discovering insights from data, satisfaction of query optimization, or enjoyment of building data systems enabling better decisions. Connect to career goals such as becoming database architect, data engineer, or business intelligence specialist. Share defining moment that sparked database interest like successful data analysis project or solving challenging query problem.
21. How do you stay updated with SQL and database technologies?
Mention specific habits including following SQL blogs (SQLServerCentral, Brent Ozar, Mode Analytics blog), attending virtual conferences or meetups, completing online courses (Udemy, Coursera, DataCamp), and experimenting with new database features. Discuss recent features learned such as SQL Server window functions, PostgreSQL JSON support, or cloud database services (Azure SQL, AWS RDS). Explain how you evaluate which technologies to learn based on job market trends, project needs, or personal curiosity. Demonstrate commitment to continuous learning in rapidly evolving data landscape.
22. Describe your experience with database optimization.
Discuss progression starting with basic query writing, advancing to execution plan analysis, then mastering indexing strategies, query rewriting, and database configuration tuning. Explain favorite optimization techniques with reasoning such as “I prefer covering indexes for frequently-run reporting queries because they eliminate table lookups”. Share specific optimization projects like “Reduced month-end report from 2 hours to 5 minutes through partitioning and indexed views”. Demonstrate systematic approach to performance problems using profiling tools, analyzing wait statistics, and measuring improvements.
23. How do you approach database design for new projects?
Describe methodology starting with requirements gathering (understanding business entities and relationships), creating ER diagrams, applying normalization principles (usually to 3NF), defining primary/foreign keys and constraints, and considering future scalability. Explain balancing normalization for data integrity with denormalization for query performance based on access patterns. Discuss incorporating stakeholder feedback through iterative reviews of data models. Share example project showcasing thoughtful design decisions and positive outcomes.
24. What’s your approach to data quality and validation?
Describe philosophy emphasizing prevention over correction through database constraints (PRIMARY KEY, FOREIGN KEY, CHECK, NOT NULL, UNIQUE), appropriate data types, and default values. Explain practices like input validation at application layer, data profiling before migration, reconciliation queries comparing source and target counts, and automated data quality monitoring. Discuss balancing strict validation preventing bad data with flexibility for edge cases. Share metrics demonstrating data quality improvements from your initiatives.
25. How do you handle legacy database systems?\
Describe strategies including understanding before changing (analyzing existing queries and dependencies), documenting as you learn (creating ER diagrams for undocumented databases), adding tests incrementally before modifications, and gradual refactoring rather than big-bang rewrites. Explain patience required when working with technical debt and balancing improvements with new feature development. Share specific legacy database success stories like “Safely migrated 0-year-old database to modern schema with zero data loss through phased approach”.
Questions to Ask Interviewers
26. About the Database Technology Stack
- What database platform and version is the team using? Are there plans to upgrade
- What’s the data volume and growth rate?
- How does the team handle database schema changes and versioning?
- What tools do you use for database monitoring and performance tuning?
- Is the database on-premise, cloud, or hybrid?
27. About Database Development Practices
- What does the query review process look like?
- How frequently do database changes get deployed to production?
- What’s the approach to database testing and quality assurance?
- How does the team handle database technical debt?
- What’s the process for optimizing slow-running queries?
28. About Data and Analytics Team
- How is the data team structured (DBAs, data engineers, analysts, BI developers)?
- What’s the balance between ad-hoc analysis and production database work?
- How does the team collaborate with business stakeholders?
- What BI tools does the organization use (Power BI, Tableau, etc.)?
29. About Growth and Challenges
- What are the biggest database challenges the team is currently facing?
- What opportunities exist for learning new database technologies?
- How does the team share knowledge and mentor junior database professionals?
- What does career progression look like for SQL/database roles here?
- What keeps you excited about database work at this company?
30. About the Specific Role
- What does success look like in the first 90 days for this role?
- What’s the split between development work (new queries/databases) and maintenance?
- How much autonomy will I have in database design decisions?
- What’s the team’s approach to work-life balance during critical database issues?

Managing Interview Stress and Anxiety
31. Pre-Interview Physical Preparation
Get 7-8 hours sleep the night before interviews ensuring mental sharpness for complex SQL problem-solving. Eat a balanced breakfast providing sustained energy while avoiding heavy foods causing sluggishness. Light exercise like walking or stretching before the interview releases nervous energy and improves focus. Stay hydrated throughout preparation and interview day maintaining cognitive performance.
32. Mental Preparation Techniques
Visualize successful interview performance including confidently explaining query optimization and answering behavioral questions building confidence. Practice positive self-talk replacing “I might struggle with complex JOINs” with “I’ve solved challenging database problems before and I’m well-prepared”. Review key database achievements and successful projects boosting confidence in abilities. Remember that confidence comes from competence and thorough preparation.
33. Breathing and Relaxation Methods
Practice deep breathing techniques: inhale for 4 counts, hold for 4 counts, exhale for 4 counts before and during interviews. Focus on breathing when feeling overwhelmed by difficult SQL questions bringing attention back to the present moment. Progressive muscle relaxation (tense and release muscle groups) reduces physical tension before interviews. These techniques lower heart rate and reduce anxiety symptoms enabling clearer thinking.
34. Reframing Nervousness Positively
Recognize nervousness as a normal response even for experienced database professionals. Reframe anxiety as excitement and readiness for the challenge changing the physiological interpretation. Remember that interviewers want candidates to succeed and are generally supportive not adversarial. View interviews as conversations and learning opportunities rather than interrogations.
35. Recovery from Mistakes During SQL Interviews
When making query syntax errors or logical mistakes, acknowledge without excessive apology: “Let me correct this JOIN condition” then fix and continue. Don’t dwell on mistakes—maintain forward momentum and positive attitude. Interviewers expect some errors; recovery and problem-solving approach matter more than perfection. Learn from mistakes in real-time showing adaptability like “I realize this subquery approach won’t scale; let me try a CTE instead”.
Interview Preparation Timeline
30 Days Before Interview
- Review all 200+ technical SQL questions covering fundamentals, joins, optimization, and advanced topics
- Practice 30-50 SQL query problems on platforms like LeetCode, HackerRank, or SQLZoo covering various difficulty levels
- Build or polish 2-3 database portfolio projects showcasing design, optimization, and Power BI integration skills
- Research the company’s industry, data challenges, and technology stack thoroughly
- Prepare 8-0 STAR behavioral stories covering different competencies (problem-solving, collaboration, learning, conflict resolution)
Week Before Interview
- Review company-specific SQL database information including database platforms used, data scale, and team structure
- Conduct 2-3 mock SQL interviews with peers, mentors, or online platforms
- Review key database projects with technical details ready to discuss (data volumes, performance metrics, optimization techniques)
- Prepare 0-5 thoughtful questions for interviewers about database technology, team practices, and growth opportunities
- Test all technical equipment for virtual interviews including screen sharing for SQL queries
Night Before Interview
- Light review of core SQL concepts without cramming new material
- Prepare professional environment and materials (SQL Server Management Studio or preferred tool ready)
- Get 7-8 hours quality sleep prioritizing rest over last-minute studying
- Visualization exercise of successful interview outcomes
- Avoid intensive studying—focus on rest and confidence building
Interview Day
- Healthy breakfast and light exercise for mental clarity
- Arrive or login 0-5 minutes early showing punctuality
- Breathing exercises before starting to manage nervousness
- Have water, notepad, resume, and portfolio links accessible
- Maintain positive mindset and confidence throughout
Post-Interview Follow-Up Excellence
36. Thank-You Email Timing and Structure
Send thank-you email within 24 hours, ideally same day while conversation is fresh in interviewer’s mind. Use clear subject line: “Thank You – [Your Name] – SQL Database Analyst Position”. Keep email concise (50-200 words) expressing gratitude, referencing specific discussion points about database challenges or SQL techniques, reiterating interest, and offering additional information if needed. Professional communication extends positive impression beyond the interview.
37. Personalizing Follow-Up Messages
Customize each email referencing unique conversation aspects like technical discussion about query optimization techniques, interviewer’s questions about your Power BI experience, shared interest in database performance tuning, or specific company database challenges discussed. Mention specific projects or problems discussed demonstrating attentiveness and genuine engagement. Generic templates appear insincere—personalization shows authentic interest and attention to detail valued in data-focused roles.
38. Sample Thank-You Email for SQL Professional
Subject: Thank You – [Your Name] – SQL Database Developer Position
Dear [Interviewer Name],
Thank you for discussing the SQL Database Developer role at [Company] today. I enjoyed learning about your data warehouse modernization project and the opportunity to discuss my experience optimizing complex analytical queries.
Our conversation about implementing incremental refresh strategies in Power BI particularly resonated with my recent project where I reduced dashboard load times by 75% through similar techniques. I’m especially excited about the opportunity to work on [specific project discussed] and contribute my expertise in query performance tuning and database design.
Please let me know if you need additional information about my experience with [specific technology discussed]. I look forward to the next steps in your process.
Best regards,
[Your Name]
[LinkedIn URL] | [GitHub/Portfolio URL]
39. Learning from Interview Experience
Create post-interview reflection document capturing questions asked, SQL topics covered, what went well, areas needing improvement, and new concepts encountered requiring further study. Review technical SQL questions you struggled with and study those specific topics deeply for future interviews. Track interview patterns across companies identifying common focus areas like window functions, optimization techniques, or specific database platforms. Each interview regardless of outcome improves skills and preparation for subsequent opportunities.
40. Professional Response to Rejection
If rejected, send brief, gracious response thanking them for the opportunity and expressing interest in future database openings. Request feedback on areas for improvement: “I’d appreciate any feedback to help strengthen my SQL skills for future opportunities”. Professional handling of rejection maintains positive relationships—many companies remember courteous candidates for future database roles. Use rejection as learning opportunity identifying skill gaps or interview techniques needing refinement.
🚀 Master CREATE, ALTER & UPDATE with ease!
Read our SQL How-to Guides for quick references.
Module 4: Additional Preparation Elements
This final section provides practical strategies for managing preparation time, completing SQL assignments with excellence, handling interview stress, and executing professional follow-up for SQL Database Analyst/Developer roles.
Time Management and Study Planning
1. Creating a Realistic SQL Study Schedule
Structure preparation based on available timeframe before interviews using focused blocks. For 30-day preparation, dedicate 2-3 hours daily divided into: 45 minutes reviewing SQL fundamentals (DDL, DML, joins, subqueries), 60 minutes practicing query problems from platforms like LeetCode SQL, HackerRank SQL, or SQLZoo, and 30 minutes studying database design or Power BI integration. For 60-day preparation, add depth with advanced topics like query optimization, indexing strategies, window functions, and stored procedures. For 90-day preparation, include comprehensive portfolio database projects, Power BI dashboards, and extensive system design preparation.
2. Weekly Study Goal Framework
Break down preparation into weekly goals with measurable outcomes enabling progress tracking. Week -2: Master SQL fundamentals covering SELECT statements, filtering with WHERE, sorting with ORDER BY, and basic aggregate functions (COUNT, SUM, AVG). Week 3-4: Advanced querying with INNER/OUTER/CROSS joins, subqueries, correlated subqueries, and set operations (UNION, INTERSECT, EXCEPT). Week 5-6: Database design principles including normalization (NF, 2NF, 3NF), ER diagrams, cardinality, and constraint implementation. Week 7-8: Performance optimization covering indexing strategies, execution plan analysis, query tuning, and statistics management. Week 9-0: Stored procedures, functions, triggers, transactions, and error handling in T-SQL or PL/SQL. Week -2: Power BI integration, data warehousing concepts, and interview preparation.
3. Daily Study Routine Optimization
Structure daily preparation using time blocks matched to energy levels and learning patterns. Morning sessions (high energy) best for complex topics like query optimization, execution plan analysis, or database design requiring deep concentration. Afternoon sessions ideal for practicing SQL query problems, building muscle memory for common patterns, and hands-on database work. Evening sessions suitable for lighter activities like reviewing flashcards, reading documentation, watching tutorial videos, or behavioral interview preparation. Include 5-minute breaks between study blocks preventing burnout and maintaining focus throughout preparation period.
4. Prioritization Matrix for SQL Topics
Categorize topics using urgency/importance framework focusing effort where it creates maximum interview impact. High priority (70% time): Core SQL (SELECT, WHERE, JOIN, GROUP BY, aggregates), query optimization basics, database design fundamentals, common interview patterns (top N per group, running totals, date calculations). Medium priority (25% time): Window functions (ROW_NUMBER, RANK, LAG, LEAD), CTEs (Common Table Expressions), indexing strategies, transactions and concurrency, Power BI basics. Lower priority (5% time): Advanced SQL Server features (partitioning, columnstore indexes), database administration tasks, cloud database services, niche platform-specific features. Adjust distribution based on specific job descriptions and identified weak areas from practice assessments.
5. Efficient Learning Techniques for SQL
Use Pomodoro technique (25-minute focused sessions, 5-minute breaks) maintaining concentration during intensive query problem solving or database design exercises. Apply spaced repetition for retaining SQL syntax patterns, join types, normalization rules, and common query patterns. Practice active recall by attempting query problems before reviewing solutions, explaining query logic aloud to yourself or peers, and teaching concepts to others reinforcing understanding. Create concise reference notes for SQL syntax patterns, optimization techniques, and database design principles enabling quick review before interviews. Maintain error journals documenting common mistakes in queries (missing JOIN conditions, incorrect GROUP BY usage) with corrected versions.
SQL Assignment Best Practices
6. Understanding Assignment Scope and Requirements
Read assignment instructions 2-3 times carefully taking detailed notes on required tables, relationships, queries needed, and evaluation criteria. Identify must-have features like specific tables with constraints, required queries with expected outputs, and data population requirements versus nice-to-have enhancements like stored procedures, views, or advanced optimizations. Estimate time needed realistically considering database design time, query complexity, testing requirements, and documentation preparation. If critical requirements are ambiguous (expected data volume, query performance requirements, platform choice), ask clarifying questions early rather than making assumptions that might be wrong.
7. Database Design Planning Before Coding
Create comprehensive implementation plan before writing SQL including entity identification, relationship mapping (:, :M, M:M), normalization analysis to 3NF, primary/foreign key selection, constraint definition (CHECK, UNIQUE, NOT NULL), and index planning for performance. Sketch ER diagrams on paper or using tools like draw.io, Lucidchart, or DbSchema visualizing table relationships and cardinality. Define sample queries needed to fulfill requirements listing expected inputs and outputs. Initialize project structure with organized folders for schema definitions, data population scripts, query files, and documentation. Good planning saves significant time during implementation and demonstrates systematic database approach.
8. SQL Code Quality Standards
Write production-quality SQL following platform-specific naming conventions (e.g., Pascal case for tables, camelCase for columns, or snake_case consistently), proper indentation and formatting for readability, and consistent SQL keyword capitalization. Use meaningful names for tables, columns, constraints, and indexes that clearly indicate purpose: CustomerOrders not CO, idx_Customers_Email not idx. Implement proper constraints including primary keys on all tables, foreign keys for referential integrity, CHECK constraints for business rules, NOT NULL for required fields. Add inline comments explaining complex query logic, business rules implemented, or non-obvious design decisions. Use consistent formatting with proper indentation showing query structure clearly: JOIN clauses aligned, WHERE conditions readable, subqueries properly nested.
9. Testing Strategy for SQL Assignments
Include comprehensive test data covering normal cases, boundary conditions, and edge cases (NULL values, empty strings, duplicate prevention, referential integrity violations). Create verification queries proving requirements are met: row counts match expectations, relationships work correctly, constraints prevent invalid data, aggregate calculations produce correct results. Test query performance with larger datasets if possible showing awareness of scalability concerns and optimization needs. Document test cases in separate file listing scenario tested, expected result, actual result, and verification query used. Testing demonstrates quality consciousness and professional database development practices valued by employers.
10. Comprehensive Assignment Documentation
Write detailed README including project description and purpose, database schema with ER diagram, setup instructions (database creation, prerequisites), data population instructions, query examples with descriptions, sample outputs showing results, assumptions made during design, technologies used (SQL Server, MySQL, PostgreSQL), and potential future improvements. Include schema diagram as image showing tables, relationships, and key constraints visually. Provide sample queries demonstrating key functionality with expected outputs clearly labeled. Add data dictionary documenting each table’s purpose, column descriptions, data types, and constraints. Quality documentation significantly differentiates candidates showing communication skills and professionalism.
11. Version Control for SQL Assignments
Initialize Git repository at project start tracking changes systematically throughout development. Create logical, incremental commits showing development progression: initial schema design, table creation scripts, constraint additions, data population, basic queries, complex queries, optimization, documentation. Write meaningful commit messages describing what changed and why: “Add Customer and Order tables with foreign key relationship”, “Implement query to find top 0 customers by revenue”. Clean Git history demonstrates organized work approach, version control proficiency, and systematic development process. Avoid single massive commit containing all work which appears rushed and unprofessional.
12. Going Beyond Basic Requirements
After completing core requirements, consider value-added enhancements demonstrating advanced database skills: stored procedures for common operations encapsulating business logic, views simplifying complex queries for reporting, indexes with analysis showing performance improvements, triggers implementing automated data validation or audit trails, functions for reusable calculations. Add Power BI integration if relevant creating sample dashboard connecting to database, showing understanding of BI tools. Include query optimization analysis showing execution plans before/after optimization with performance metrics. Document additional features clearly in README explaining purpose and implementation. Balance enhancements with time constraints avoiding over-engineering that delays submission.
13. Pre-Submission Assignment Checklist
Verify all requirements met by checking against original assignment description systematically. Test fresh database setup by running all scripts in sequence on new database instance ensuring no environment-specific dependencies. Review SQL syntax for errors using database client query validation or linting tools. Check documentation completeness ensuring README covers setup, usage, and design decisions thoroughly. Test sample queries manually verifying results match expected outputs documented. Review code formatting ensuring consistent style throughout all SQL files. Professional polish in final submission creates strong positive impression with evaluators.
14. Time Management for SQL Assignments
For multi-day assignments (3-5 days), aim to complete core requirements in 60-70% of allocated time leaving buffer for polish, testing, documentation, and unexpected challenges. Break work into manageable chunks spreading over multiple sessions: Day (schema design and planning), Day 2 (table creation and constraints), Day 3 (data population and basic queries), Day 4 (complex queries and optimization), Day 5 (documentation and polish). Track time spent on each component ensuring balanced attention across design, implementation, testing, and documentation. Early completion demonstrates efficiency and strong time management; late submission suggests poor planning or technical struggles.
Managing Interview Stress and Anxiety
15. Pre-Interview Physical Preparation
Get 7-8 hours quality sleep the night before interviews ensuring mental sharpness for complex SQL problem-solving and clear technical communication. Eat balanced breakfast providing sustained energy (complex carbs, protein) while avoiding heavy foods causing sluggishness or excessive caffeine triggering anxiety. Engage in light exercise like 5-minute walk or stretching before interview releasing nervous energy and improving focus through increased blood flow. Stay well hydrated throughout preparation and interview day maintaining cognitive performance and preventing dry mouth from nervousness.
16. Mental Preparation Techniques
Practice visualization exercises imagining successful interview performance including confidently explaining query optimization, smoothly writing complex JOINs on whiteboard, and building rapport with interviewers. Use positive self-talk replacing negative thoughts (“I might struggle with window functions”) with affirmations (“I’ve practiced extensively and understand SQL deeply”). Review key database achievements and successful projects boosting confidence in abilities and providing concrete examples ready for behavioral questions. Remember confidence comes from competence—thorough preparation naturally builds genuine self-assurance.
17. Breathing and Relaxation Methods
Practice box breathing technique before and during interviews: inhale for 4 counts, hold for 4 counts, exhale for 4 counts, hold for 4 counts, repeat. Focus on controlled breathing when feeling overwhelmed by difficult SQL questions bringing attention back to present moment and reducing fight-or-flight response. Use progressive muscle relaxation before interviews by systematically tensing and releasing muscle groups from toes to head reducing physical tension manifestations. These physiological techniques lower heart rate, reduce anxiety symptoms, and enable clearer analytical thinking for complex database problems.
18. Reframing Nervousness Positively
Recognize nervousness as normal even for experienced database professionals—it shows you care about the opportunity and want to perform well. Reframe anxiety as excitement using identical language: “I’m excited for this challenge” rather than “I’m nervous about this interview”—the physiological state is similar but interpretation differs. Remember interviewers want success—they’re generally supportive, invested in finding qualified candidates, and hoping you’re the right fit. View interviews as professional conversations and learning opportunities about the company rather than adversarial interrogations.
19. Recovery from SQL Mistakes During Interviews
When making query syntax errors or logical mistakes, acknowledge briefly without excessive apology: “Let me correct this JOIN condition” then fix error and continue forward]. Don’t dwell on mistakes—maintain forward momentum and positive attitude showing resilience under pressure. Interviewers expect some errors; recovery approach and problem-solving process matter more than perfection. Learn from mistakes in real-time demonstrating adaptability: “I realize this subquery approach won’t scale for large datasets; let me try using a CTE with indexing instead”.
20. Building Confidence Through Mock SQL Interviews
Conduct 5-0 mock interviews with peers, mentors, or online platforms before actual interviews building familiarity with format and reducing anxiety. Record yourself answering behavioral questions and explaining SQL solutions identifying areas for improvement in communication clarity, pacing, and technical accuracy. Use platforms like Pramp or interviewing.io for realistic SQL interview practice with feedback from experienced practitioners. Repeated exposure reduces anxiety through familiarity—the tenth interview feels much less stressful than the first.
Whiteboard and Live Coding Best Practices
21. Understanding SQL Whiteboard Format
SQL whiteboard interviews typically last 45-60 minutes structured as: 5-0 minutes problem introduction and context, 5 minutes asking clarifying questions about tables/relationships/requirements, 0-5 minutes discussing solution approach and query strategy, 20-30 minutes writing SQL query on whiteboard or shared editor, 5-0 minutes testing with examples and discussing optimization. Interviewers evaluate problem-solving approach, SQL knowledge depth, query optimization awareness, communication skills during coding, and handling of feedback beyond just correct query syntax.
22. Structured Approach to SQL Problems
Follow systematic process demonstrating organized thinking: restate problem in own words confirming understanding of business requirement, ask clarifying questions about table schemas, data volumes, expected result format, performance requirements, and edge cases, discuss query approach before writing SQL explaining join strategy, filtering logic, aggregation needs, and optimization considerations. Then write clean SQL with proper formatting and aliasing, test with provided examples including edge cases, and discuss time/space complexity or query performance characteristics. This structured approach shows professional database problem-solving even if final solution isn’t perfect.
23. Communication During SQL Whiteboard Coding
Think aloud throughout the problem-solving process explaining reasoning: “I’m using INNER JOIN here because we only need matching records”, “I’ll add an index hint here for query optimization”, “This GROUP BY aggregates sales data by customer”. Verbalization helps interviewers follow logic and provide hints when needed, plus demonstrates clear thinking process. Silence signals struggle; continuous communication shows engagement, confidence, and collaborative problem-solving approach valued in database teams. Welcome interviewer hints treating them as collaboration opportunities rather than failures.
24. SQL-Specific Whiteboard Tips
Write clean SQL syntax with proper capitalization (SELECT, FROM, WHERE in capitals), appropriate indentation showing query structure (JOINs aligned, WHERE conditions indented), meaningful table aliases (c for Customers, o for Orders, not a, b, c), and proper column qualification with table aliases. Use SQL standard functions and syntax appropriate to platform discussed (SQL Server: TOP, DATEPART; MySQL: LIMIT, DATE_FORMAT; PostgreSQL: LIMIT, EXTRACT). Demonstrate familiarity with modern SQL features like window functions (ROW_NUMBER, RANK), CTEs (WITH clauses), and set operations when appropriate to problem. Comment complex logic explaining non-obvious business rules or optimization techniques.
25. Testing and Edge Cases for SQL Queries
Walk through query with provided sample data showing intermediate results after each clause (after WHERE filter, after JOIN, after GROUP BY, final SELECT output). Identify and discuss edge cases: NULL values in join columns, empty tables, zero-row results, aggregates on empty groups, division by zero, date boundary conditions. Explain how query handles each edge case referencing specific SQL clauses: “The LEFT JOIN ensures we show customers even without orders”, “COALESCE handles NULL values in the calculation”. Time permitting, trace through edge case completely demonstrating thoroughness and attention to data quality.
Post-Interview Follow-Up Excellence
26. Thank-You Email Timing and Structure
Send thank-you email within 24 hours, ideally same day while conversation is fresh in interviewer’s memory and demonstrates promptness. Use clear subject line: “Thank You – [Your Name] – SQL Database Analyst Position” enabling easy identification and filing. Keep email concise (50-200 words) including: expression of gratitude for time and consideration, reference to specific discussion points about database challenges or SQL techniques, reiteration of interest in role and company, offer to provide additional information if needed, professional closing with contact information. Professional communication extends positive impression beyond the interview itself.
27. Personalizing Follow-Up Messages
Customize each email referencing unique conversation aspects like technical discussion about query optimization strategies, interviewer’s questions about your Power BI dashboard experience, shared interest in database performance tuning methodologies, or specific company database challenges discussed during interview. Mention specific projects or problems discussed demonstrating attentiveness and genuine engagement during conversation: “I enjoyed discussing your migration from MySQL to SQL Server and challenges with query translation”. Generic templates appear insincere—personalization shows authentic interest and attention to detail highly valued in data-focused roles.
28. Sample Thank-You Email for SQL Professional
Subject: Thank You – [Your Name] – SQL Database Analyst Position
Dear [Interviewer Name],
Thank you for discussing the SQL Database Analyst role at [Company] today. I greatly enjoyed learning about your data warehouse modernization project and the opportunity to discuss my experience optimizing complex analytical queries and designing efficient database schemas.
Our conversation about implementing columnstore indexes for your reporting workload particularly resonated with my recent project where I reduced dashboard load times by 80% through similar optimization techniques. I’m especially excited about the opportunity to contribute to [specific project discussed] and apply my expertise in query performance tuning and Power BI integration.
Please let me know if you need additional information about my experience with [specific SQL technology or technique discussed]. I look forward to the next steps in your selection process.
Best regards,
[Your Name]
[LinkedIn URL] | [GitHub/Portfolio URL]
29. Learning from SQL Interview Experience
Create post-interview reflection document capturing: specific SQL questions asked (query problems, optimization scenarios, design questions), database topics covered (normalization, indexing, transactions, Power BI), what went well (strong areas, good explanations), areas needing improvement (struggled topics, unclear explanations), new concepts encountered requiring further study. Review technical SQL questions you struggled with and study those specific topics deeply ensuring better preparedness for future interviews. Track interview patterns across multiple companies identifying common focus areas like window functions, query optimization, specific join types, or database design principles. Each interview regardless of outcome improves skills and interview readiness through experience and targeted learning.
30. Professional Response to Rejection
If rejected, send brief, gracious response thanking them for opportunity and expressing interest in future database openings demonstrating professionalism and maturity. Request feedback on areas for improvement: “I’d appreciate any specific feedback to help strengthen my SQL skills and interview performance for future opportunities”. Professional handling of rejection maintains positive relationships—many companies remember courteous candidates when future database roles open or when hiring managers move to new companies. Use rejection as learning opportunity identifying skill gaps through self-reflection or feedback, focusing improvement efforts where they’ll have maximum impact.
Final SQL Interview Preparation Checklist
30 Days Before Interview
 Review all 200+ technical SQL questions covering fundamentals through advanced topics
Review all 200+ technical SQL questions covering fundamentals through advanced topics- Complete 50+ SQL query problems on LeetCode SQL, HackerRank SQL, or SQLZoo with increasing difficulty
- Build or polish 2-3 database portfolio projects showcasing design, optimization, and Power BI integration
- Study database design fundamentals and practice 5-0 schema design scenarios
- Prepare 8-0 STAR behavioral stories covering problem-solving, collaboration, learning, and conflict resolution
Week Before Interview
- Conduct 2-3 mock SQL interviews with peers, mentors, or online platforms
- Review company technology stack (SQL Server/MySQL/PostgreSQL), database scale, and recent company news
- Prepare 0-5 thoughtful questions for interviewers about database technology, team practices, and growth opportunities
- Test technical equipment for virtual interviews including SQL Server Management Studio or preferred database client
- Review key database projects with technical details ready: data volumes, query performance metrics, optimization techniques
Night Before Interview
- Light review of core SQL concepts without cramming new material
- Prepare professional environment and materials (notepad, resume, project links)
- Get 7-8 hours quality sleep prioritizing rest over late-night studying
- Visualization exercise of successful interview outcomes
- Avoid intensive studying—focus on rest and confidence building
Interview Day
- Healthy breakfast and light exercise for mental clarity
- Arrive or login 0-5 minutes early demonstrating punctuality
- Breathing exercises before starting to manage nervousness
- Have water, notepad, resume accessible during interview
- Maintain positive mindset and confidence throughout
Within 24 Hours After Interview
- Send personalized thank-you email to each interviewer
- Follow up with any promised materials (SQL scripts, portfolio projects)
- Document interview questions and personal reflection notes
- Practice self-care and stress management after intense interview
- Continue applying and preparing for other SQL opportunities
