Java Full Stack Developer Interview Preparation Guide
This guide provides a comprehensive framework for both fresh graduates and experienced professionals to excel in Java Full Stack Developer interviews. The material is structured for step-by-step progression through all critical interview preparation aspects.
What you’ll master in this guide:
- Module 1: 220 Technical Interview Questions & Answers
- Module 2: 45 Self-Preparation Prompts Using ChatGPT
- Module 3: Communication Skills and Behavioural Interview Preparation
- Module 4: Time Management, Assignments, Stress Management, and Follow-up

⚡ Become a Job-Ready Java Full Stack Developer
Master Core Java, Spring Boot, Microservices, React & DevOps with our
Java Full Stack Developer Course.
1. Module : 220 Technical Interview Questions & Answers
- Core Java Programming (Questions 1-50) + Additional Q&A (15)
- Object-Oriented Programming in Java (Questions 9-13)
- Java 8 Features (Questions 51-70)
- Spring Framework and Spring Boot (Questions 14-90)
- RESTful API Development with Spring (Questions 21-25)
- Database Management with Hibernate/JPA (Questions 26-160)
- Frontend Technologies Integration (Questions 33-38)
- System Design Fundamentals (Questions 39-40)
- Spring Security & JWT (Questions 101-130)
- Design Patterns (Questions 161-180)
- Build Tools, Testing & DevOps (Questions 181-200)
- Microservices, Kafka & Cloud (Questions 201-220)
Core Java Programming :
- What are the key features of Java?
Java offers platform independence through the Java Virtual Machine (JVM), object-oriented programming principles, automatic memory management via garbage collection, robust exception handling, multithreading support, and strong security features. Java’s “Write Once, Run Anywhere” capability makes it ideal for enterprise applications requiring cross-platform compatibility. The language emphasizes simplicity, reliability, and performance for full stack development.
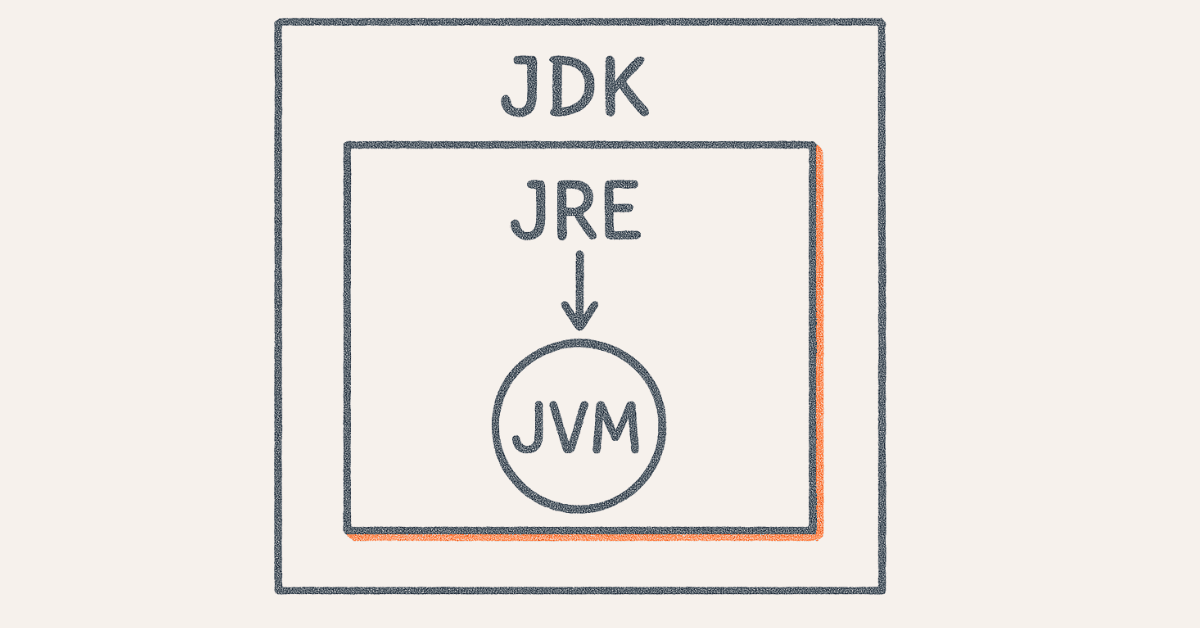
- Explain the difference between JDK, JRE, and JVM.
JDK (Java Development Kit) is the complete development environment containing compiler, debugger, and development tools needed to create Java applications. JRE (Java Runtime Environment) provides libraries and JVM required to run Java applications but cannot compile code. JVM (Java Virtual Machine) executes Java bytecode and provides platform independence by translating bytecode to machine-specific instructions.
- What is the difference between == and equals() in Java?
The == operator compares object references (memory addresses) for equality, while the equals() method compares object content or values. For primitive types, == compares values directly, but for objects like String, equals() should be used to compare actual content. Overriding equals() allows custom comparison logic for user-defined classes.
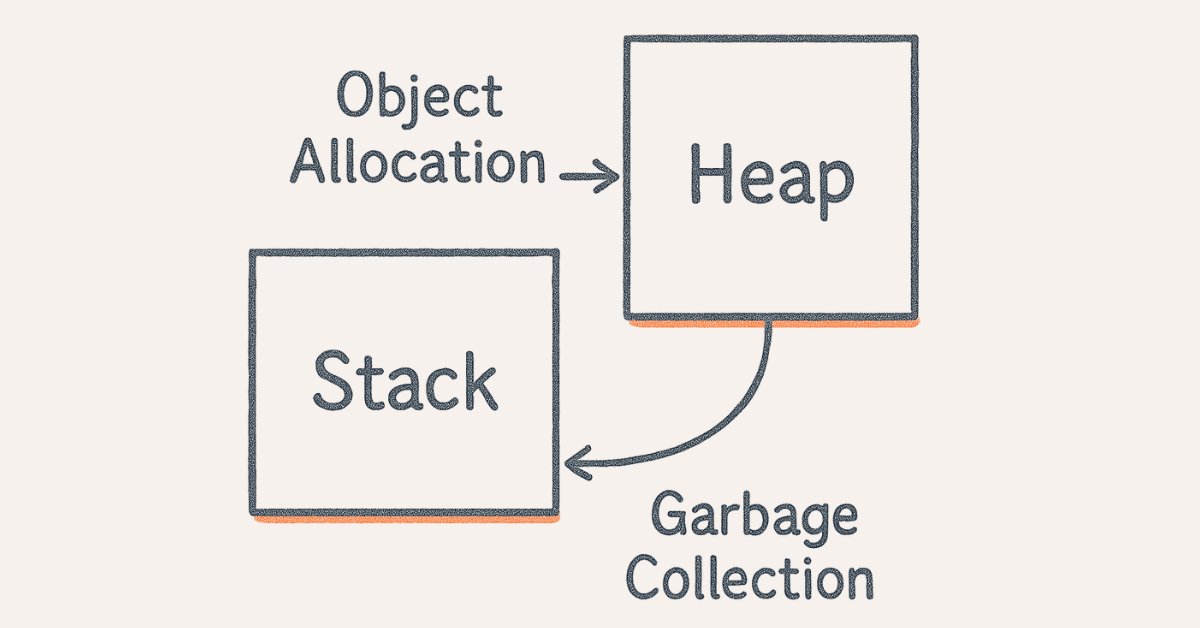
- Explain Java’s memory management and garbage collection.
Java uses heap memory for object storage and stack memory for method execution and local variables. Garbage collection automatically reclaims memory from objects no longer referenced, preventing memory leaks. The garbage collector uses generational algorithms (Young Generation, Old Generation, Permanent Generation) to optimize collection efficiency based on object lifecycle patterns.
- What are the differences between String, StringBuilder, and StringBuffer?
String is immutable, meaning any modification creates a new object, making it thread-safe but inefficient for frequent concatenation. StringBuilder is mutable and not thread-safe, offering the best performance for single-threaded string manipulation. StringBuffer is mutable and thread-safe with synchronized methods, suitable for multi-threaded environments but slower than StringBuilder.
- Explain exception handling in Java.
Java uses try-catch-finally blocks to handle exceptions, with try containing code that might throw exceptions, catch blocks handling specific exception types, and finally executing regardless of exception occurrence for cleanup operations. Checked exceptions (compile-time) must be caught or declared, while unchecked exceptions (runtime) like NullPointerException don’t require explicit handling. Custom exceptions extend Exception or RuntimeException classes for application-specific error handling.
- What are functional interfaces and lambda expressions?
Functional interfaces contain exactly one abstract method and enable lambda expressions, introduced in Java 8 for functional programming. Lambda expressions provide concise syntax for implementing functional interfaces: (parameters) -> expression. Common functional interfaces include Predicate, Consumer, Function, and Supplier for various operations on data streams.
- Explain the Stream API in Java.
The Stream API provides a functional approach to processing collections with operations like filter, map, reduce, and collect. Streams support lazy evaluation, executing operations only when terminal operations are called, improving performance for large datasets. Parallel streams enable concurrent processing across multiple threads, leveraging multi-core processors automatically.
Object-Oriented Programming in Java
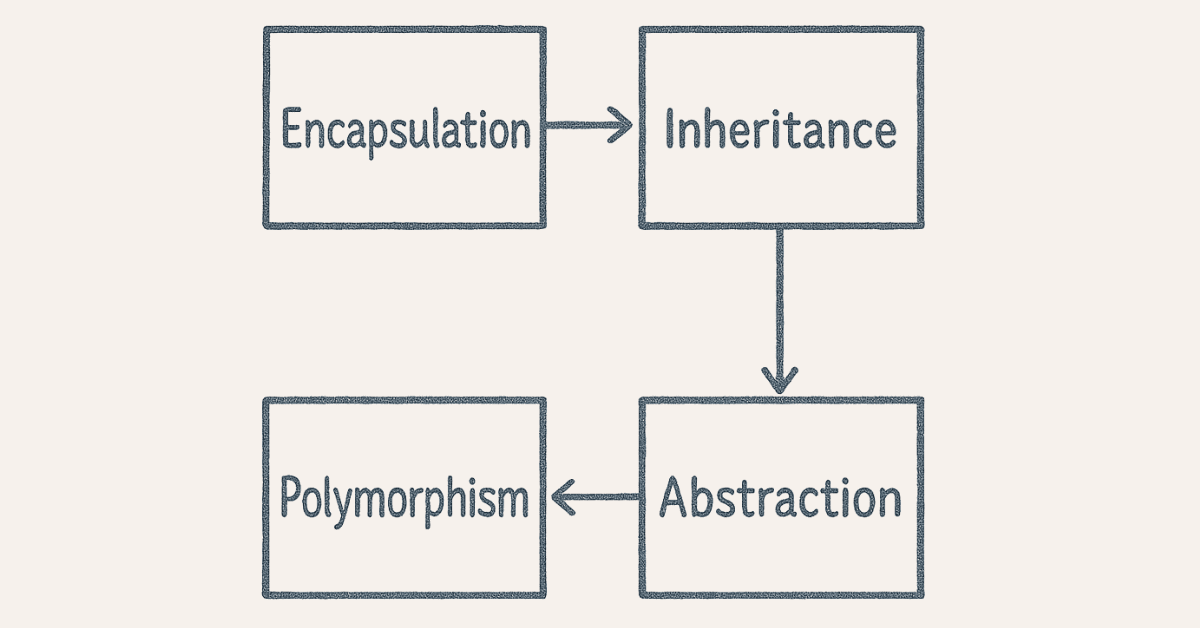
- What are the four pillars of OOP?
Encapsulation bundles data and methods while hiding internal implementation details through access modifiers. Inheritance allows classes to acquire properties and methods from parent classes, promoting code reusability. Polymorphism enables objects to take multiple forms through method overloading (compile-time) and method overriding (runtime). Abstraction hides complex implementation details, exposing only essential features through abstract classes and interfaces.
- What is the difference between abstract classes and interfaces?
Abstract classes can have both abstract and concrete methods, constructors, instance variables, and any access modifiers. Interfaces (pre-Java 8) contained only abstract methods and constants, but Java 8 introduced default and static methods. A class can implement multiple interfaces but extend only one abstract class, making interfaces more flexible for achieving multiple inheritance. Interfaces define contracts while abstract classes provide partial implementation and shared behavior.
- Explain method overloading vs. method overriding.
Method overloading occurs within the same class with methods having identical names but different parameters (number, type, or order), resolved at compile-time. Method overriding happens when a subclass provides specific implementation for a method already defined in its superclass, maintaining the same signature and resolved at runtime. Overloading demonstrates compile-time polymorphism while overriding demonstrates runtime polymorphism.
- What is the purpose of final, finally, and finalize?
The final keyword makes variables constants, prevents method overriding, and prohibits class inheritance. finally is a block that executes after try-catch regardless of exception occurrence, typically used for resource cleanup. finalize() is a method called by garbage collector before destroying objects, though deprecated in modern Java versions in favor of try-with-resources.
- Explain Java Collections Framework.
The Collections Framework provides unified architecture for storing and manipulating groups of objects through interfaces (List, Set, Map, Queue) and implementations (ArrayList, HashSet, HashMap, LinkedList). List maintains insertion order and allows duplicates, Set prevents duplicates, Map stores key-value pairs, and Queue follows FIFO principle. Generics ensure type safety, and Collections utility class provides static methods for sorting, searching, and synchronizing collections.
Spring Framework and Spring Boot
- What is Spring Boot and how does it differ from Spring Framework?
Spring Boot is an opinionated framework built on top of Spring Framework that simplifies application setup through auto-configuration, embedded servers, and starter dependencies. Spring Framework requires extensive XML or Java configuration, while Spring Boot provides sensible defaults and convention-over-configuration approach. Spring Boot eliminates boilerplate code, enables rapid development, and includes production-ready features like health checks and metrics through Spring Boot Actuator.
- What are the key features of Spring Boot?
Auto-configuration automatically configures Spring application based on classpath dependencies, eliminating manual configuration. Starter dependencies provide pre-configured dependency bundles for specific functionalities like spring-boot-starter-web for web applications. Embedded servers (Tomcat, Jetty, Undertow) eliminate external server deployment requirements. Spring Boot Actuator provides production-ready monitoring and management endpoints.
- Explain Dependency Injection in Spring.
Dependency Injection is a design pattern where Spring container injects object dependencies rather than objects creating their own dependencies. Constructor injection (recommended) provides dependencies through class constructors, ensuring immutability and testability. Setter injection uses setter methods for optional dependencies, while field injection (less preferred) uses @Autowired annotation directly on fields. DI promotes loose coupling and easier unit testing.
- What is the purpose of @SpringBootApplication annotation?
@SpringBootApplication is a composite annotation combining @Configuration, @EnableAutoConfiguration, and @ComponentScan. It marks the main class, enables auto-configuration of Spring beans based on classpath settings, and scans the package and sub-packages for Spring components. This single annotation simplifies Spring Boot application setup and bootstrapping.
- Explain different Spring Bean scopes.
Singleton scope (default) creates one bean instance per Spring IoC container, shared across all requests. Prototype scope creates a new instance every time the bean is requested. Request scope creates one instance per HTTP request in web applications. Session scope maintains one instance per HTTP session, while Application scope creates one instance per ServletContext.
- What are Spring Profiles?
Spring Profiles enable environment-specific configuration by activating different beans and properties for development, testing, and production environments. Profiles are activated using spring.profiles.active property or @Profile annotation on configuration classes. This allows separate database configurations, logging levels, and feature flags per environment without code changes.
- How does Spring Boot handle externalized configuration?
Spring Boot supports configuration through multiple sources: application.properties, application.yml, environment variables, command-line arguments, and @ConfigurationProperties classes. Properties are loaded in specific order of precedence, with command-line arguments overriding file-based configuration. @Value annotation injects individual property values, while @ConfigurationProperties binds entire property groups to Java objects
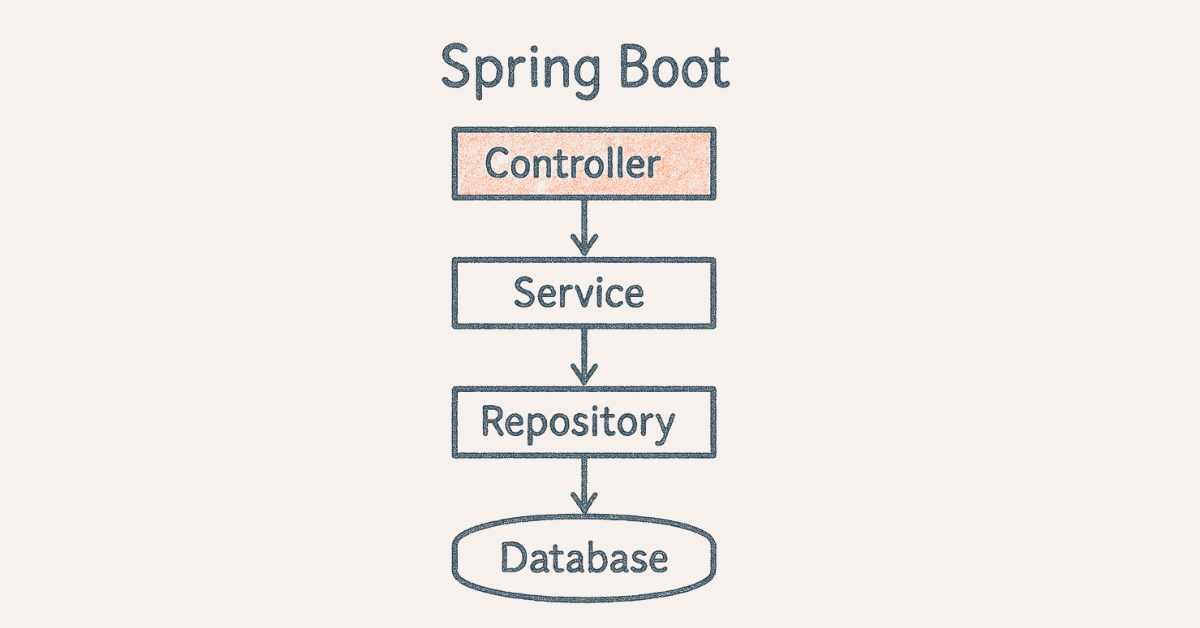
RESTful API Development with Spring
- How do you create REST APIs in Spring Boot?
REST APIs are created using @RestController annotation combining @Controller and @ResponseBody. HTTP method annotations (@GetMapping, @PostMapping, @PutMapping, @DeleteMapping) map URL paths to controller methods. Request data is captured using @PathVariable, @RequestParam, and @RequestBody annotations. ResponseEntity provides control over HTTP status codes, headers, and response body.
- Explain the different HTTP methods and their usage.
GET retrieves resources without side effects and is idempotent, POST creates new resources, PUT updates entire resources or creates if non-existent (idempotent), PATCH partially updates resources, and DELETE removes resources (idempotent). Proper method usage ensures RESTful principles and predictable API behavior. Safe methods (GET, HEAD) don’t modify server state, while idempotent methods (GET, PUT, DELETE) produce same result on repeated calls.
- What are HTTP status codes in REST APIs?
2xx series indicates success (200 OK, 201 Created, 204 No Content), 3xx series indicates redirection (301 Moved Permanently, 304 Not Modified). 4xx series represents client errors (400 Bad Request, 401 Unauthorized, 403 Forbidden, 404 Not Found). 5xx series represents server errors (500 Internal Server Error, 503 Service Unavailable). Appropriate status codes help clients handle responses correctly and debug issues efficiently.
- How do you handle exceptions in Spring Boot REST APIs?
@ExceptionHandler annotation handles specific exceptions within a controller, while @ControllerAdvice creates global exception handlers across all controllers. Custom exception classes extend RuntimeException with meaningful messages and HTTP status mappings. @ResponseStatus annotation maps exceptions to specific HTTP status codes. Structured error responses include timestamp, status code, error message, and path for client debugging.
- What is RestTemplate and WebClient?
RestTemplate is Spring’s synchronous client for consuming REST APIs, providing methods for common HTTP operations like getForObject(), postForEntity(), etc.. WebClient is the modern, reactive alternative supporting both synchronous and asynchronous operations with non-blocking I/O. RestTemplate is in maintenance mode, and WebClient is recommended for new projects due to better performance and scalability. Both handle request/response serialization automatically using HttpMessageConverters.
Database Management with Hibernate/JPA
- What is JPA and how does it differ from Hibernate?
JPA (Java Persistence API) is a specification defining standard ORM (Object-Relational Mapping) APIs for persisting Java objects to relational databases. Hibernate is the most popular JPA implementation providing the actual functionality defined by JPA specification. JPA offers portability across different ORM providers, while Hibernate provides additional features beyond JPA specification like caching strategies and custom types. Using JPA interfaces allows switching ORM implementations without major code changes.
- Explain the JPA entity lifecycle.
Transient state represents newly created objects not associated with persistence context or database. Persistent state occurs when entities are managed by EntityManager, with changes automatically synchronized to database. Detached state happens when persistent entities are no longer managed by EntityManager but still exist in memory. Removed state marks entities for deletion from database. Understanding lifecycle states is crucial for managing transactions and avoiding LazyInitializationException.
- What are the differences between @Entity annotations and mapping configurations?
@Entity marks a class as JPA entity mapped to database table, while @Table specifies table name if different from class name. @Id designates primary key field, with @GeneratedValue defining key generation strategy (AUTO, IDENTITY, SEQUENCE, TABLE). @Column customizes column mapping with attributes like name, nullable, length, and unique constraints. Relationship annotations (@OneToOne, @OneToMany, @ManyToOne, @ManyToMany) define entity associations.
- Explain lazy loading vs. eager loading in JPA.
Lazy loading (FetchType.LAZY) defers loading of related entities until explicitly accessed, reducing initial query overhead. Eager loading (FetchType.EAGER) loads related entities immediately with parent entity, suitable for frequently accessed associations. Lazy loading can cause LazyInitializationException if accessing relationships outside transaction scope. @OneToMany and @ManyToMany default to lazy, while @ManyToOne and @OneToOne default to eager.
- What is the N+1 select problem and how do you solve it?
N+1 problem occurs when loading a collection of entities triggers one query for the parent and N additional queries for each child relationship, severely impacting performance. Solutions include JOIN FETCH in JPQL to fetch associations in single query, @EntityGraph annotation defining fetch plan, and batch fetching to reduce query count. Hibernate’s @BatchSize annotation loads relationships in batches rather than individually. Monitoring SQL logs helps identify and resolve N+1 issues.
- Explain different transaction management strategies in Spring.
Declarative transaction management uses @Transactional annotation to define transaction boundaries, with Spring handling commit/rollback automatically. Programmatic transaction management provides explicit control using TransactionTemplate or PlatformTransactionManager. Transaction propagation behaviors (REQUIRED, REQUIRES_NEW, NESTED, etc.) control how transactions interact with existing transactions. Isolation levels (READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE) prevent concurrency issues like dirty reads and phantom reads.
- What are JPQL and Criteria API?
JPQL (Java Persistence Query Language) is object-oriented query language operating on entities rather than tables, using entity and field names instead of table/column names. Criteria API provides programmatic, type-safe approach to building queries using Java code, preventing syntax errors at compile-time. Named queries defined with @NamedQuery annotation provide reusable, pre-compiled queries. Native SQL queries are supported when database-specific features are required.
Frontend Technologies Integration
- What is the role of frontend technologies in Java Full Stack development?
Frontend technologies handle client-side presentation and user interaction using HTML for structure, CSS for styling, and JavaScript for dynamic behavior. Modern Java full stack applications integrate frameworks like React or Angular for component-based UIs communicating with Spring Boot backends via REST APIs. Single Page Applications (SPAs) load once and dynamically update content through asynchronous API calls, providing smooth user experiences. RESTful communication enables clean separation between frontend and backend development.
- How does React differ from Angular for Java full stack development?
React is a JavaScript library focused on building user interfaces using component-based architecture and virtual DOM for efficient rendering. Angular is a complete TypeScript-based framework providing comprehensive solutions including routing, forms, HTTP client, and dependency injection. React offers more flexibility with third-party library choices, while Angular provides opinionated, integrated tooling. Both integrate seamlessly with Spring Boot backends through RESTful APIs and handle authentication tokens for secure communication.
- What are the key concepts in React for full stack developers?
Components are reusable UI building blocks defined as functions or classes receiving props and managing state. State management controls component data that changes over time, with hooks like useState and useReducer managing local state. Props enable parent-to-child data flow in component hierarchy, while Context API handles global state without prop drilling. React Router manages navigation in SPAs, and lifecycle methods or useEffect hook handle side effects.
- What are Angular’s core features for Java developers?
Two-way data binding synchronizes model and view automatically, reducing boilerplate code for form handling. Dependency Injection manages component dependencies, similar to Spring’s DI pattern familiar to Java developers. TypeScript provides static typing, interfaces, and object-oriented features aligning with Java’s type system. Angular CLI generates components, services, and modules with best practices, accelerating development. RxJS observables handle asynchronous operations and event streams elegantly.
- How do you secure frontend-backend communication?
JWT (JSON Web Tokens) authenticate API requests by including signed tokens in HTTP headers after successful login. Spring Security validates tokens, verifies signatures, and extracts user information for authorization decisions. CORS (Cross-Origin Resource Sharing) configuration in Spring Boot allows controlled cross-domain API access from frontend applications. HTTPS encrypts data in transit, preventing man-in-the-middle attacks. Input validation on both frontend and backend prevents injection attacks.
- Explain the role of AJAX and Fetch API.
AJAX (Asynchronous JavaScript and XML) enables asynchronous communication with servers without page reloads, creating responsive user experiences. Fetch API is modern, promise-based interface for making HTTP requests, replacing older XMLHttpRequest approach. Axios is popular third-party library simplifying HTTP requests with features like request/response interceptors and automatic JSON transformation. These technologies enable SPAs to consume Spring Boot REST APIs dynamically.
System Design Fundamentals
- What is microservices architecture?
Microservices architecture decomposes applications into small, independent services communicating via lightweight protocols like HTTP/REST. Each microservice owns its domain logic and data, enabling independent deployment, scaling, and technology stack choices. Service discovery (Eureka), API gateway (Zuul/Spring Cloud Gateway), and circuit breakers (Hystrix/Resilience4j) support distributed system patterns. Microservices offer scalability and maintainability but introduce complexity in distributed transactions and testing.
- How do you implement caching in Spring Boot applications?
Spring’s caching abstraction uses annotations like @Cacheable, @CachePut, and @CacheEvict to declaratively manage caching. Cache providers include EhCache, Hazelcast, Redis, and Caffeine, configured through spring-boot-starter-cache dependency. @Cacheable stores method results, @CachePut updates cache, and @CacheEvict removes entries. Caching reduces database load and improves response times for frequently accessed data. Cache keys, TTL (time-to-live), and eviction policies must be configured appropriately.
- What is multithreading and why is it important?
Multithreading enables concurrent execution of multiple threads within a single program, maximizing CPU utilization and improving application performance. Threads share the same memory space making inter-thread communication efficient compared to separate processes. Multithreading is crucial for building responsive UIs, handling multiple client requests simultaneously in servers, and performing background tasks without blocking main execution.
- How do you create a thread in Java?
Threads are created by extending the Thread class and overriding the run() method, or implementing the Runnable interface and passing it to a Thread constructor. The Runnable approach is preferred as it allows class inheritance and promotes better separation of concerns. For Java 8+, lambda expressions simplify Runnable implementation: new Thread(() -> { // code }).start().
- Explain thread lifecycle states in Java.
Thread states include NEW (created but not started), RUNNABLE (executing or ready to execute), BLOCKED (waiting for monitor lock), WAITING (waiting indefinitely for another thread), TIMED_WAITING (waiting for specified time), and TERMINATED (execution completed). Transitions occur through methods like start(), wait(), notify(), sleep(), and join(). Understanding lifecycle helps debug threading issues and optimize concurrent applications.
- What is synchronization and why is it needed?
Synchronization prevents thread interference and memory consistency errors when multiple threads access shared resources. Synchronized methods acquire the object’s intrinsic lock before execution, ensuring only one thread executes at a time. Synchronized blocks provide granular control by locking specific objects rather than entire methods, improving performance. Without synchronization, race conditions lead to unpredictable results.
- Explain the volatile keyword in Java.
The volatile keyword guarantees visibility of variable changes across threads by preventing CPU caching and instruction reordering. When a variable is declared volatile, reads and writes happen directly to main memory rather than thread-local caches. Volatile is suitable for flags and status variables but doesn’t provide atomicity for compound operations like increment. For atomic operations, use AtomicInteger and related classes.
- What is a deadlock and how do you prevent it?
Deadlock occurs when two or more threads permanently block each other, each holding resources the others need. Prevention strategies include acquiring locks in consistent order across all threads, using timeout with tryLock(), avoiding nested locks, and using concurrent utilities instead of manual synchronization. The classic dining philosophers problem illustrates deadlock scenarios. Tools like ThreadMXBean help detect deadlocks in running applications.
- What is the difference between wait() and sleep()?
wait() releases the object’s monitor lock and must be called from synchronized context, while sleep() retains locks and can be called from anywhere. wait() is used for inter-thread communication with corresponding notify() or notifyAll() calls, whereas sleep() simply pauses execution for specified duration. wait() requires exception handling for InterruptedException. Spurious wakeups require wait() to be called in loops with condition checks.
- Explain the Executor Framework in Java.
The Executor Framework provides thread pool management separating task submission from execution mechanics. ExecutorService offers methods like submit(), invokeAll(), and shutdown() for managing tasks. Thread pools (FixedThreadPool, CachedThreadPool, ScheduledThreadPool) reuse threads, reducing overhead of thread creation. Callable and Future interfaces enable tasks that return results and handle exceptions better than Runnable.
- What is CompletableFuture in Java 8?
CompletableFuture represents asynchronous computation result that can be explicitly completed and supports functional-style callbacks. Methods like thenApply(), thenAccept(), thenCompose(), and thenCombine() enable chaining asynchronous operations. CompletableFuture handles exceptions through exceptionally() and handle() methods. It simplifies complex asynchronous workflows compared to traditional Future interface.
- Explain ConcurrentHashMap and its advantages.
ConcurrentHashMap allows concurrent read and write operations without locking the entire map, using lock striping to lock individual segments. Multiple threads can read simultaneously, and write operations lock only affected segments rather than the entire map. It provides better performance than Collections.synchronizedMap() or Hashtable in multi-threaded environments. ConcurrentHashMap doesn’t allow null keys or values, ensuring thread-safe iteration without ConcurrentModificationException.
This Keyword in Java
Q1. What is the this keyword in Java and when is it used?
The this keyword is a reference variable that refers to the current object instance within a class. It is primarily used to differentiate between instance variables and parameters when they have the same name, invoke current class methods explicitly, pass the current object as a parameter to other methods, and return the current instance from methods for method chaining. The this keyword cannot be used in static contexts since static members belong to the class rather than instances.
Q2. How does this resolve naming conflicts between instance variables and parameters?
When a method parameter has the same name as an instance variable, this explicitly refers to the instance variable while the parameter name alone refers to the parameter.
Example:
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name; // this.name refers to instance variable
this.age = age; // name alone refers to parameter
}
}
Without this, the assignment would refer to the parameter itself, not updating the instance variable.
Q3. Explain constructor chaining using this().
Constructor chaining using this() calls another constructor in the same class, reducing code duplication. The this() call must be the first statement in the constructor and can pass different arguments to invoke overloaded constructors.
Example:
public class Product {
private String name;
private double price;
public Product(String name) {
this(name, 0.0); // Calls two-parameter constructor
}
public Product(String name, double price) {
this.name = name;
this.price = price;
}
}
This approach centralizes initialization logic in one constructor while providing convenient overloads.
Super Keyword in Java
Q4. What is the super keyword and how does it differ from this?
The super keyword refers to the immediate parent class object and is used to access parent class members, invoke parent class constructors, and call overridden methods from the parent class. While this refers to the current class instance, super refers to the parent class instance. The super keyword enables child classes to reuse and extend parent functionality rather than completely replacing it.
Q5. How do you use super() to invoke parent class constructors?
The super() call invokes the parent class constructor and must be the first statement in the child class constructor. If not explicitly called, Java automatically inserts a no-argument super() call, which fails if the parent class doesn’t have a default constructor.
Example:
public class Vehicle {
protected String brand;
public Vehicle(String brand) {
this.brand = brand;
}
}
public class Car extends Vehicle {
private int doors;
public Car(String brand, int doors) {
super(brand); // Must be first statement
this.doors = doors;
}
}
This ensures proper initialization of parent class state before child class initialization.
Q6. Explain method overriding with super to access parent methods.
When a child class overrides a parent method, super.methodName() calls the parent’s version of the method. This is useful when extending functionality rather than completely replacing it. Example:
public class Animal {
public void makeSound() {
System.out.println(“Animal makes a sound”);
}
}
public class Dog extends Animal {
@Override
public void makeSound() {
super.makeSound(); // Calls parent method
System.out.println(“Dog barks”);
}
}
This pattern allows child classes to build upon parent behavior while adding specialized functionality.
Constructors in Java
Q7. What are the different types of constructors in Java?
Java supports two types of constructors: default (no-argument) constructors automatically provided by the compiler if no constructor is defined, and parameterized constructors that accept arguments for object initialization. Copy constructors, while not built-in like C++, can be manually implemented to create objects by copying another object’s state. Private constructors prevent instantiation and are commonly used in singleton patterns or utility classes.
Q8. What are constructor chaining rules and restrictions?
Constructor chaining allows one constructor to call another using this() for same-class constructors or super() for parent-class constructors. The chaining call must be the first statement in the constructor, and both this() and super() cannot be used in the same constructor. Constructors cannot be recursive—a constructor cannot call itself directly or indirectly through chaining.
Q9. Can constructors be final, static, or abstract in Java?
Constructors cannot be declared as final, static, or abstract in Java. The final keyword is meaningless for constructors since they cannot be inherited or overridden. Constructors cannot be static because they initialize instance-specific state and must be called on object creation. Abstract constructors are contradictory since abstract classes cannot be instantiated directly.
DOM (Document Object Model)
Q10. What is the DOM and how does it relate to Java Full Stack development?
The DOM (Document Object Model) is a platform-independent programming interface that represents HTML and XML documents as tree structures, where each node represents part of the document. In Java Full Stack development, while frontend JavaScript directly manipulates the DOM through frameworks like React or Angular, Java developers understand DOM concepts for server-side rendering, web scraping using libraries like JSoup, and integrating with frontend technologies. The DOM enables dynamic content updates without full page reloads in Single Page Applications that consume Java REST APIs.
Q11. How do Java developers interact with DOM structures?
Java developers interact with DOM through libraries like JSoup for HTML parsing and manipulation, Java’s built-in DOM API (org.w3c.dom) for XML processing, and understanding how frontend frameworks modify DOM based on API responses. JSoup provides jQuery-like selectors for extracting and manipulating HTML elements server-side. When building REST APIs, Java developers structure JSON responses that frontend frameworks use to update DOM elements dynamically.
Q12. Explain the relationship between DOM manipulation and REST APIs.
REST APIs serve data that frontend JavaScript uses to manipulate the DOM dynamically. When a React or Angular component receives JSON from a Spring Boot API, it updates virtual DOM (React) or real DOM (Angular) to reflect new data without page reloads. Java backend developers design API responses with frontend DOM updates in mind, ensuring proper data structure, pagination, and error handling. This separation allows independent frontend and backend development while maintaining clear communication contracts.
Arrays in Java (Enhanced Coverage)
Q13. What are the different ways to declare and initialize arrays in Java?
Arrays can be declared using type[] arrayName or type arrayName[] syntax, though the first is preferred. Initialization methods include declaring size int[] numbers = new int[^6], initializing with values int[] numbers = {1, 2, 3, 4, 5}, or creating and initializing separately. Multi-dimensional arrays use multiple brackets: int[][] matrix = new int[^4][^5] creates a 3×4 matrix, and jagged arrays allow rows of different lengths.
Q14. Explain the difference between arrays and ArrayList in Java.
Arrays have fixed size determined at creation and can store primitives or objects directly. ArrayList is a resizable implementation from the Collections framework that only stores objects (primitives are autoboxed) and provides methods like add(), remove(), and contains(). Arrays offer better performance for fixed-size collections and direct index access, while ArrayList provides flexibility for dynamic sizing and rich API methods. Arrays use length property while ArrayList uses size() method.
Q15. How do you copy arrays in Java and what are the best practices?
Arrays can be copied using System.arraycopy() for efficiency, Arrays.copyOf() for creating new arrays with specified length, or clone() method for shallow copies. For deep copying of object arrays, manual iteration with object cloning is required to avoid shared references. Java 8+ streams provide functional copying: int[] copy = Arrays.stream(original).toArray(). Best practice is using Arrays.copyOf() for clarity and avoiding manual loops unless deep copying is required.
🗺️ Follow the Complete Java Full Stack Roadmap
Beginner → Java → Spring Boot → Microservices → React → DevOps.
Java 8 Features
- What are Lambda Expressions?
Lambda expressions provide concise syntax for implementing functional interfaces using arrow notation (parameters) -> expression. They enable functional programming style in Java, making code more readable and maintainable. Lambda expressions can access effectively final local variables from enclosing scope. They’re extensively used with Stream API and functional interfaces like Predicate, Consumer, Function, and Supplier.
- Explain the Stream API in detail.
Stream API processes collections in declarative manner using functional operations like filter, map, reduce, collect, and forEach. Streams support intermediate operations (lazy evaluation) and terminal operations (trigger computation). Parallel streams enable concurrent processing across multiple CPU cores automatically. Streams don’t modify source collections; they create new result streams maintaining immutability.
- What is the difference between map() and flatMap()?
`map()` transforms each element to another object, maintaining stream structure with one-to-one mapping. `flatMap()` transforms each element to a stream and flattens all resulting streams into single stream, useful for nested structures. For example, map converts `Stream<String>` to `Stream<Integer>`, while flatMap converts `Stream<List<String>>` to `Stream<String>`. flatMap is essential for operations on nested collections.[^9][^11][^7][^8]
- Explain Optional class in Java 8.
Optional is a container object that may or may not contain a non-null value, preventing NullPointerException. Methods like isPresent(), orElse(), orElseGet(), orElseThrow(), and ifPresent() provide safe value handling. Optional encourages explicit handling of absence rather than relying on null checks. Avoid using get() without checking presence; prefer functional methods for safer code.
- What are Method References in Java 8?
Method references provide shorthand syntax for lambda expressions that simply call existing methods using :: operator. Four types exist: static method reference (Class::staticMethod), instance method reference (instance::instanceMethod), arbitrary object method reference (Class::instanceMethod), and constructor reference (Class::new). They make code more concise and readable compared to equivalent lambda expressions. Method references can only be used when lambda body contains single method call.
- Explain the Date/Time API introduced in Java 8.
Java 8 introduced java.time package with immutable, thread-safe classes like LocalDate, LocalTime, LocalDateTime, ZonedDateTime, and Instant. The new API fixes issues with legacy Date and Calendar classes including mutability and confusing indexing. Period and Duration represent time-based amounts, while DateTimeFormatter handles parsing and formatting. The API supports comprehensive timezone handling through ZoneId and ZoneOffset.
- What are Default Methods in Interfaces?
Default methods allow interfaces to have method implementations using the default keyword, enabling interface evolution without breaking existing implementations. Multiple inheritance of behavior becomes possible, though diamond problem is resolved through specific override rules. Default methods cannot override Object class methods. They’re extensively used in Java 8’s Collection interfaces for backward compatibility.
- What are Static Methods in Interfaces?
Interfaces can contain static methods with implementation, providing utility methods related to the interface. Static interface methods belong to the interface itself, not instances, and cannot be overridden. They’re called using interface name: InterfaceName.staticMethod(). Static methods help group related utility functionality with interfaces.
- Explain Functional Interfaces in Java 8.
Functional interfaces contain exactly one abstract method and can be annotated with @FunctionalInterface for compile-time checking. They enable lambda expressions and method references, forming the foundation of functional programming in Java. Common functional interfaces include Predicate (boolean test), Consumer (accepts input, no return), Function (transforms input to output), and Supplier (provides output, no input). Custom functional interfaces can be created for domain-specific operations.
- What is the forEach() method and how does it work?
forEach() is a terminal operation on streams and a default method in Iterable interface that performs an action for each element. It accepts a Consumer functional interface, often implemented as lambda expression. forEach() doesn’t guarantee order for parallel streams; use forEachOrdered() when order matters. It’s more concise than traditional for loops but doesn’t support break or continue.
- Explain filter(), map(), and reduce() operations.
filter() selects elements matching a predicate, creating a stream with fewer elements. map() transforms each element by applying a function, maintaining stream size. reduce() combines elements using an associative accumulation function to produce single result. These operations form the core of stream processing pipelines for data transformation.
- What is the collect() method in Streams?
collect() is a terminal operation that transforms stream elements into different mutable collections using Collectors. Collectors utility class provides common collectors: toList(), toSet(), toMap(), groupingBy(), partitioningBy(), and joining(). Custom collectors can be created using Collector.of() for specialized accumulation logic. The collect operation is highly flexible for aggregating stream results.
- How do you handle grouping and partitioning in Streams?
groupingBy() collector groups elements by classifier function into Map with category keys and element lists as values. Downstream collectors enable nested grouping and aggregation operations. partitioningBy() is special case of grouping that splits elements into two groups based on predicate, returning Map<Boolean, List>. These operations replace complex looping logic with declarative expressions.
- Explain parallel streams and when to use them.
Parallel streams divide stream into multiple substreams processed concurrently across multiple CPU cores. Enable parallelism using parallelStream() or parallel() method on streams. Parallel streams benefit CPU-intensive operations on large datasets but add overhead for small collections. Ensure operations are stateless and associative for correct parallel execution; avoid shared mutable state.
- What are Stream’s peek() and distinct() methods?
peek() is intermediate operation primarily for debugging, allowing inspection of elements without modifying them. It accepts Consumer and returns stream with same elements, useful for logging or validation in pipelines. distinct() returns stream with unique elements based on equals() and hashCode() methods. distinct() is stateful operation requiring memory to track seen elements.
- Explain anyMatch(), allMatch(), and noneMatch().
anyMatch() returns true if at least one element matches the predicate, short-circuiting when match is found. allMatch() returns true only if all elements match, short-circuiting on first non-match. noneMatch() returns true if no elements match the predicate. All three are terminal operations returning boolean and are optimized for parallel streams.
- What is findFirst() and findAny() in Streams?
findFirst() returns Optional containing first element in encounter order, useful when order matters. findAny() returns any element from stream, optimized for parallel streams where first element extraction is expensive. Both are short-circuiting terminal operations that don’t need to process entire stream. Return Optional.empty() for empty streams.
- How do you create infinite streams in Java 8?
Stream.generate() creates infinite stream by repeatedly invoking Supplier function. Stream.iterate() creates infinite stream by applying UnaryOperator to previous element starting from seed value. Limit infinite streams using limit() operation to prevent infinite loops. Infinite streams are useful for generating test data or mathematical sequences.
- Explain the String API enhancements in Java 8.
Java 8 added join() static method for concatenating strings with delimiter. Stream support through chars(), codePoints() methods enables functional string processing. The lines() method in BufferedReader returns Stream<String> for efficient file processing. These enhancements align String handling with functional programming paradigms.
- What are the limitations of Stream API?
Streams are single-use; once terminal operation is called, stream cannot be reused. Debugging stream pipelines is challenging due to chained operations. Stream operations add overhead compared to simple loops for small collections. Checked exceptions in lambda expressions require verbose try-catch blocks or wrapper methods.
Spring Boot Advanced
- What is Spring Boot Actuator?
Spring Boot Actuator provides production-ready features like monitoring, metrics, and health checks through HTTP endpoints. Built-in endpoints include /health, /metrics, /info, /env, and /loggers. Custom endpoints can be created using @Endpoint annotation. Actuator integrates with monitoring tools like Prometheus and Grafana for comprehensive application observability.
- How do you secure Spring Boot Actuator endpoints?
Actuator endpoints are secured using Spring Security by configuring endpoint exposure through management.endpoints.web.exposure.include and exclude properties. Apply role-based access control using Spring Security’s HttpSecurity configuration. Sensitive endpoints like /shutdown should be disabled or heavily restricted in production. Use management port separation to isolate actuator endpoints from main application.
- What is Spring Boot DevTools?
Spring Boot DevTools provides development-time features like automatic restart, live reload, and enhanced logging. It automatically restarts application when classpath files change, significantly faster than manual restart. DevTools is automatically disabled in production when running packaged jar files. Remote debugging and remote update features enable development on remote servers.
- Explain Spring Boot’s auto-configuration mechanism.
Auto-configuration uses conditional annotations like @ConditionalOnClass, @ConditionalOnMissingBean, and @ConditionalOnProperty to conditionally apply configuration. Spring Boot scans classpath and automatically configures beans based on dependencies present. The @EnableAutoConfiguration annotation triggers auto-configuration scanning. Developers can exclude specific auto-configurations using exclude attribute or properties.
- How do you customize Spring Boot’s default configuration?
Configuration is customized through application.properties or application.yml files with hierarchical property structures. Java configuration classes annotated with @Configuration override defaults programmatically. Command-line arguments and environment variables override file-based properties following Spring Boot’s property precedence order. @ConfigurationProperties binds external properties to Java objects for type-safe configuration.
- What is Spring Boot Starter?
Starters are dependency descriptors providing curated sets of dependencies for specific functionality. Common starters include spring-boot-starter-web, spring-boot-starter-data-jpa, spring-boot-starter-security. Starters simplify dependency management by handling transitive dependencies and version compatibility. Custom starters can be created for organizational standards.
- Explain @Conditional annotations in Spring Boot.
@ConditionalOnClass activates configuration when specified classes are present on classpath. @ConditionalOnMissingBean creates beans only when specific bean types aren’t already defined. @ConditionalOnProperty enables configuration based on property values. These annotations provide flexible auto-configuration based on application context.
- What is the role of SpringApplication class?
SpringApplication bootstraps Spring Boot application, creating ApplicationContext and registering beans. It handles command-line arguments, configures logging, and triggers auto-configuration. Customization is possible through SpringApplicationBuilder for fluent configuration or by registering ApplicationListeners. The run() method starts the embedded server and initializes the application.
- How do you implement health checks in Spring Boot?
Implement HealthIndicator interface to create custom health checks evaluating application dependencies like databases, external services. Spring Boot provides built-in health indicators for common dependencies. Health status aggregation combines multiple indicators into overall application health. Configure health check details exposure through management.endpoint.health.show-details property.
- What are ApplicationListeners and ApplicationEvents?
ApplicationListener interface enables beans to receive and respond to application events like startup, shutdown, or custom events. Implement ApplicationEventPublisher to publish custom events throughout the application. Event-driven architecture decouples components by communicating through events rather than direct method calls. @EventListener annotation simplifies event handling on regular bean methods.
- How do you implement validation in Spring Boot?
Use Bean Validation API (javax.validation) with annotations like @NotNull, @Size, @Email, @Pattern on model fields. @Valid annotation on controller method parameters triggers validation. MethodArgumentNotValidException is thrown for validation failures, which can be globally handled using @ControllerAdvice. Custom validators implement ConstraintValidator interface for complex validation logic.
- What is Spring Boot’s Embedded Server?
Spring Boot includes embedded Tomcat, Jetty, or Undertow servers, eliminating external server deployment. Configuration properties customize server behavior: port, context path, SSL, compression. Embedded servers simplify deployment as self-contained jar files including all dependencies. Exclude default embedded server and add alternative using starter dependencies.
- How do you configure multiple data sources in Spring Boot?
Define separate DataSource beans with @Primary annotation on default source and @Qualifier for specific injection. Configure separate EntityManagerFactory and TransactionManager for each data source. Use @ConfigurationProperties with different prefixes for each database connection configuration. Repository packages are assigned to specific data sources using @EnableJpaRepositories basePackages and entityManagerFactoryRef attributes.
- What is CommandLineRunner and ApplicationRunner?
CommandLineRunner and ApplicationRunner interfaces execute code after Spring Boot application startup. CommandLineRunner receives raw String arguments, while ApplicationRunner receives ApplicationArguments with parsed options. Multiple runners can be ordered using @Order annotation for execution sequence. Common use cases include database initialization, cache warming, or scheduled job setup.
- How do you implement async processing in Spring Boot?
Enable async execution with @EnableAsync on configuration class and @Async annotation on methods. Configure thread pool executor through AsyncConfigurer interface or property-based configuration. Methods return CompletableFuture, Future, or void for asynchronous results. @Async methods must be public and called from outside the same class to enable proxy-based interception.
- What is Spring Boot’s banner and how do you customize it?
Banner is ASCII art displayed during application startup, customizable through banner.txt file in resources. Properties like application version, Spring Boot version can be included using placeholders. Disable banner using spring.main.banner-mode=off or programmatically with SpringApplication.setBannerMode(). Custom Banner interface implementation provides full control over banner display.
- How do you handle CORS in Spring Boot?
Configure CORS globally using WebMvcConfigurer’s addCorsMappings() method specifying allowed origins, methods, headers. @CrossOrigin annotation provides controller or method-level CORS configuration. Configure CORS with Spring Security for secure applications through CorsConfigurationSource. Proper CORS configuration prevents cross-origin security issues while enabling frontend-backend communication.
- What is Content Negotiation in Spring Boot?
Content Negotiation determines response format based on Accept header or URL extension/parameter. Spring Boot supports JSON, XML, and custom media types through HttpMessageConverters. Configure preferred media types and content negotiation strategy through WebMvcConfigurer. Produces and consumes attributes in @RequestMapping specify supported media types explicitly.
- How do you implement caching in Spring Boot?
Enable caching with @EnableCaching and use @Cacheable, @CachePut, @CacheEvict annotations on methods. Configure cache manager and underlying cache provider (EhCache, Redis, Caffeine) through dependencies and properties. Define cache names, keys using SpEL expressions, and time-to-live in configuration. Cache abstraction allows switching providers without code changes.
- What is Spring Boot’s Logging framework?
Spring Boot uses Logback as default logging implementation with Commons Logging API. Configure logging levels, patterns, and output destinations through application.properties. Support for multiple logging frameworks (Log4j2, Java Util Logging) through exclusions and dependencies. Logging groups enable configuring related loggers together with single property.
- How do you implement pagination and sorting in Spring Boot?
Spring Data provides Pageable and Sort parameters in repository methods for automatic pagination/sorting. Return Page or Slice objects containing results and metadata like total pages, elements. URL parameters like ?page=0&size=10&sort=name,desc are automatically bound to Pageable. Custom pagination logic can be implemented using PageRequest and Sort classes.
- What is Spring Boot’s testing support?
@SpringBootTest loads full application context for integration tests with configurable environment and properties. @WebMvcTest tests MVC controllers with minimal context including only web layer. @DataJpaTest configures in-memory database and JPA components for repository testing. MockMvc, TestRestTemplate, and WebTestClient provide different approaches for testing web layers.
- How do you mock dependencies in Spring Boot tests?
@MockBean creates Mockito mocks and adds them to Spring application context, replacing real beans. @SpyBean wraps existing beans allowing partial mocking of methods. Mockito’s when().thenReturn() and verify() methods define mock behavior and assert interactions. @Mock and @InjectMocks work outside Spring context for pure unit testing.
- What is @DataJpaTest annotation?
@DataJpaTest configures embedded database, JPA repositories, EntityManager, and test infrastructure. It applies auto-configuration relevant to JPA tests only, excluding web and other layers. Transactions are rolled back automatically after each test method execution. TestEntityManager provides alternative to EntityManager optimized for test scenarios.
- How do you test REST controllers in Spring Boot?
Use @WebMvcTest with MockMvc to test controllers without starting full HTTP server. MockMvc’s perform() method executes requests with fluent API for assertions: status, content, headers. @SpringBootTest with TestRestTemplate or WebTestClient tests against running server. Mock service layer dependencies using @MockBean to isolate controller testing.
- What is Spring Boot’s @TestConfiguration?
@TestConfiguration defines test-specific beans without affecting main application configuration. It’s detected and loaded automatically when used as nested class in test class. Explicit import using @Import is needed for external test configuration classes. Test configurations override or supplement auto-configuration for testing scenarios.
- How do you implement file upload/download in Spring Boot?
Use MultipartFile parameter in controller methods annotated with @PostMapping for file uploads. Configure maximum file size and request size through spring.servlet.multipart.max-file-size properties. Return ResponseEntity with InputStreamResource or byte array for file downloads with appropriate Content-Type and Content-Disposition headers. Store files in filesystem or cloud storage (S3, Azure Blob) based on requirements.
- What is Spring Boot’s Scheduled Tasks support?
Enable scheduling with @EnableScheduling and use @Scheduled annotation with cron, fixedRate, or fixedDelay attributes. Configure thread pool for scheduled tasks through properties or TaskScheduler bean. Cron expressions provide flexible scheduling: minute, hour, day, month, weekday patterns. Scheduled methods must be void return type and cannot accept parameters.
- How do you implement email sending in Spring Boot?
Use spring-boot-starter-mail with JavaMailSender interface for sending emails. Configure SMTP server properties: host, port, username, password, protocol. MimeMessage and MimeMessageHelper classes handle complex emails with attachments and HTML content. Templates engines like Thymeleaf or FreeMarker generate dynamic email content.
- What is Spring Boot’s support for WebSockets?
Spring Boot supports WebSocket protocol for bidirectional, full-duplex communication. Configure WebSocket endpoints using @EnableWebSocketMessageBroker and STOMP protocol. MessageMapping and SendTo annotations define server-side message handlers and destinations. SockJS provides fallback options for browsers without native WebSocket support.
Spring Security & JWT
- What is Spring Security?
Spring Security is a comprehensive authentication and authorization framework providing declarative security for Spring applications. It handles common security vulnerabilities including CSRF, session fixation, and clickjacking out-of-the-box. Spring Security integrates seamlessly with Spring Boot through auto-configuration and starter dependencies. The framework supports multiple authentication mechanisms including form-based, basic, OAuth2, and JWT.
- Explain the difference between Authentication and Authorization.
Authentication verifies user identity by validating credentials like username/password combinations. Authorization determines what authenticated users are permitted to access based on their roles and permissions. Authentication answers “Who are you?”, while authorization answers “What can you do?”. Spring Security separates these concerns through AuthenticationManager for authentication and AccessDecisionManager for authorization.
- What is the role of SecurityContext in Spring Security?
SecurityContext stores security information about the current user, including authentication details and granted authorities. It’s held by SecurityContextHolder using ThreadLocal storage making it accessible throughout request processing. The context persists across the entire request-response cycle and is cleared afterward. Multiple storage strategies exist: MODE_THREADLOCAL (default), MODE_INHERITABLETHREADLOCAL, and MODE_GLOBAL.
- How does Spring Security Filter Chain work?
Spring Security uses a chain of servlet filters intercepting requests before reaching controllers. The DelegatingFilterProxy delegates to FilterChainProxy managing multiple SecurityFilterChain instances. Common filters include UsernamePasswordAuthenticationFilter, BasicAuthenticationFilter, and CsrfFilter executing in specific order. Custom filters can be added at specific positions using addFilterBefore(), addFilterAfter(), or addFilterAt() methods.
- What is UserDetailsService?
UserDetailsService is a core interface retrieving user information from data sources during authentication. It contains a single method loadUserByUsername() returning UserDetails object with username, password, authorities, and account status. Custom implementations typically query databases or LDAP directories for user credentials and roles. InMemoryUserDetailsManager and JdbcUserDetailsManager provide built-in implementations.
- Explain PasswordEncoder in Spring Security.
PasswordEncoder encodes passwords securely before storage and verifies credentials during authentication. BCryptPasswordEncoder is recommended using adaptive hashing with configurable strength levels. Never store plain text passwords; always encode them before persisting to database. DelegatingPasswordEncoder supports multiple encoding schemes for password migration scenarios.
- What is JWT (JSON Web Token)?
JWT is a compact, URL-safe token format containing JSON payload digitally signed for integrity verification. JWTs consist of three Base64-encoded parts: header (algorithm), payload (claims), and signature separated by dots. Stateless authentication uses JWTs eliminating server-side session storage, improving scalability. JWTs contain expiration time, issuer, subject, and custom claims for user information.
- How do you implement JWT authentication in Spring Boot?
Create JwtTokenProvider generating tokens with secret key and expiration time configuration. Implement JwtAuthenticationFilter extracting tokens from Authorization header and validating signatures. Configure Spring Security to use stateless session management and JWT filter before UsernamePasswordAuthenticationFilter. Store JWT in client (localStorage/sessionStorage) and include in subsequent request headers.
- What are JWT claims and their types?
Claims are statements about entities (typically users) and additional metadata in JWT payload. Registered claims are predefined standard claims like iss (issuer), exp (expiration), sub (subject), aud (audience). Public claims are custom-defined but should avoid collisions using namespaced naming. Private claims are application-specific custom data like userId, roles, permissions.
- How do you handle JWT token refresh?
Implement refresh token mechanism issuing short-lived access tokens (15-30 min) and long-lived refresh tokens (days/weeks). When access token expires, client requests new access token using refresh token without re-authentication. Store refresh tokens securely in database with user association and rotation on each use. Revoke refresh tokens on logout or suspicious activity.
- What is OAuth2 and how does it work with Spring Security?
OAuth2 is an authorization framework enabling third-party applications to obtain limited access to user accounts. Four grant types exist: Authorization Code (web apps), Implicit (deprecated), Password (legacy), Client Credentials (service-to-service). Spring Security OAuth2 provides client and resource server support with auto-configuration. OAuth2 involves authorization server, resource server, client application, and resource owner roles.
- Explain role-based vs permission-based authorization.
Role-based authorization grants access based on user roles like ADMIN, USER, MANAGER prefixed with ROLE_. Permission-based authorization provides fine-grained control through specific permissions like READ_USERS, WRITE_POSTS. Roles represent job functions while permissions represent specific actions. Spring Security supports both through hasRole(), hasAuthority(), and SpEL expressions.
- How do you secure REST APIs with Spring Security?
Configure HTTP security with antMatchers() defining URL patterns and required authorities. Disable CSRF for stateless REST APIs and enable CORS for cross-origin requests. Implement JWT or OAuth2 token-based authentication for API security. Use @PreAuthorize and @PostAuthorize annotations for method-level security.
- What is CSRF and how does Spring Security prevent it?
Cross-Site Request Forgery tricks authenticated users into executing unwanted actions on web applications. Spring Security generates unique CSRF tokens for each session, validating tokens on state-changing requests. CSRF protection is enabled by default for form-based authentication but should be disabled for stateless REST APIs. Synchronizer token pattern embeds tokens in forms and validates on submission.
- What is CORS and how do you configure it?
Cross-Origin Resource Sharing allows controlled access to resources from different domains. Configure CORS globally using WebMvcConfigurer or per-controller with @CrossOrigin annotation. Specify allowed origins, methods, headers, and whether credentials are permitted. Proper CORS configuration is essential for SPAs communicating with backend APIs on different domains.
- Explain method-level security in Spring.
Method-level security applies authorization at service layer using annotations on methods. @PreAuthorize checks conditions before method execution, @PostAuthorize after execution. @Secured and @RolesAllowed provide simpler role-based method protection. Enable method security with @EnableGlobalMethodSecurity annotation specifying prePostEnabled, securedEnabled, jsr250Enabled.
- What is the difference between hasRole() and hasAuthority()?
hasRole() automatically adds ROLE_ prefix to the specified role name. hasAuthority() expects the exact authority string without modification. Roles are special cases of authorities representing broader access levels. Use hasRole(“ADMIN”) or hasAuthority(“ROLE_ADMIN”) interchangeably depending on preference.
- How do you implement custom authentication logic?
Create custom AuthenticationProvider implementing authenticate() method with business-specific validation logic. Override loadUserByUsername() in UserDetailsService for custom user retrieval logic. Register custom provider with AuthenticationManagerBuilder during security configuration. Custom providers enable multi-factor authentication, biometric validation, or external identity provider integration.
- What is session management in Spring Security?
Session management controls user session creation, fixation protection, and concurrent session control. Session fixation protection generates new session IDs after authentication preventing session hijacking. Concurrent session control limits simultaneous logins per user account. Stateless session management disables server-side sessions for REST APIs using token-based authentication.
- How do you implement Remember Me functionality?
Remember Me authentication uses persistent tokens stored in cookies enabling auto-login without credentials. Token-based approach stores hashed tokens in database with username and expiration. Configure rememberMe() in security configuration specifying token validity duration and key. Always use secure, HTTP-only cookies for remember-me tokens to prevent XSS attacks.
- What is Spring Security’s SecurityFilterChain?
SecurityFilterChain defines security configurations for specific request matchers in Spring Security 5.7+. Multiple filter chains can coexist with different security requirements for various URL patterns. SecurityFilterChain replaces deprecated WebSecurityConfigurerAdapter with functional approach. Chains are evaluated in order, with first matching chain handling the request.
- How do you handle authentication failures?
Configure AuthenticationFailureHandler to customize behavior on authentication failure. Implement onAuthenticationFailure() method to log attempts, increment failure counters, or redirect users. Spring Security provides default handlers like SimpleUrlAuthenticationFailureHandler. Account lockout mechanisms prevent brute force attacks by temporarily disabling accounts after multiple failures.
- What is AuthenticationManager and how does it work?
AuthenticationManager is the primary interface for authentication in Spring Security. It coordinates with AuthenticationProviders to authenticate credentials against configured sources. ProviderManager is the default implementation iterating through provider list until successful authentication. Each provider attempts authentication and throws exception on failure or returns Authentication object on success.
- Explain Spring Security’s access decision voting mechanism.
Access decisions use voters (AccessDecisionVoter) to grant or deny authorization requests. Three voters exist: RoleVoter, AuthenticatedVoter, and WebExpressionVoter for different authorization strategies. AccessDecisionManager aggregates voter results using strategies: affirmative (one grant sufficient), consensus (majority), unanimous (all must grant). Custom voters implement complex business logic for authorization decisions.
- How do you implement logout functionality?
Configure logout URL, success URL, and invalidate HTTP session in security configuration. LogoutHandler implementations perform cleanup like clearing security context, invalidating cookies, removing persistent tokens. LogoutSuccessHandler customizes post-logout behavior like redirects or custom responses. Always implement CSRF-protected logout for form-based authentication or token invalidation for stateless APIs.
- What is Spring Security’s @AuthenticationPrincipal annotation?
@AuthenticationPrincipal injects currently authenticated user directly into controller method parameters. It eliminates boilerplate code for extracting user from SecurityContext. Custom user details can be injected by implementing UserDetails in domain user class. SpEL expressions enable extracting specific properties from authentication principal.
- How do you implement API rate limiting?
Implement custom filter tracking request counts per user/IP using caching solutions like Redis. Use Bucket4j or Resilience4j RateLimiter for token bucket algorithm-based rate limiting. Configure rate limits per endpoint or globally based on user roles or authentication status. Return HTTP 429 Too Many Requests status with Retry-After header when limits exceeded.
- What is password policy enforcement in Spring Security?
Implement custom validators checking password complexity requirements (length, special chars, uppercase, numbers). Use PasswordEncoder’s upgradeEncoding() for migrating legacy passwords to stronger algorithms. Configure password expiration policies forcing periodic password changes. Store password history preventing reuse of recent passwords.
- How do you implement two-factor authentication?
Generate TOTP (Time-based One-Time Password) secrets for users using libraries like GoogleAuthenticator. Store encrypted secrets in database and validate time-based codes during login. Implement custom AuthenticationProvider combining password and TOTP validation. Provide QR code generation for mobile authenticator app enrollment.
- What are Spring Security Test utilities?
@WithMockUser annotation creates mock authenticated user for testing secured methods. @WithUserDetails loads actual user from UserDetailsService for integration tests. SecurityMockMvcRequestPostProcessors provide fluent API for authentication in MockMvc tests. TestSecurityContextHolder manages security context in test environments.
Hibernate/JPA Advanced
- What are the different fetching strategies in Hibernate?
SELECT fetching executes separate queries for associations, suitable for rarely accessed relationships. JOIN fetching uses outer join in single query loading entity with associations simultaneously. SUBSELECT fetching loads associations using subquery for entire collection. BATCH fetching loads associations in batches reducing query count compared to SELECT.
- Explain first-level and second-level cache in Hibernate.
First-level cache is session-scoped, enabled by default, storing entities within single session’s lifecycle. Second-level cache is SessionFactory-scoped, optional, shared across sessions for frequently accessed data. Cache providers include EhCache, Infinispan, Hazelcast with different characteristics. Query cache stores query results keyed by query string and parameters.
- What is the difference between save(), persist(), and merge()?
save() returns generated identifier and assigns ID to entity immediately. persist() returns void, making entity persistent but ID generation may be delayed until flush. merge() returns managed copy of detached entity, useful for updating detached instances. persist() is preferred for new entities as it’s semantically clearer.
- Explain Hibernate entity states and transitions.
Transient objects exist in memory without database representation or session association. Persistent objects are associated with session and have database representation. Detached objects were persistent but session is closed, changes aren’t tracked. Removed objects are marked for deletion, removed from database on transaction commit.
- What is dirty checking in Hibernate?
Dirty checking automatically detects changes to persistent entity fields without explicit update calls. Hibernate compares current entity state with snapshot taken at load time. Modified entities are automatically updated in database during flush operation. This eliminates boilerplate update code improving developer productivity.
- How do you handle optimistic locking in JPA?
Add @Version annotation to entity field (typically integer or timestamp) for optimistic concurrency control. JPA increments version on each update, throwing OptimisticLockException if version mismatch detected. Optimistic locking allows concurrent reads while preventing lost updates. Pessimistic locking uses database-level locks but reduces concurrency.
- What is Hibernate’s flush mode?
Flush mode controls when session state is synchronized with database. AUTO (default) flushes before queries to ensure query results reflect pending changes. COMMIT flushes only on transaction commit, improving performance but risking stale query results. MANUAL requires explicit flush() calls giving complete control.
- Explain cascading operations in JPA.
Cascade types propagate operations from parent to child entities automatically. CascadeType.ALL propagates all operations, PERSIST only persist, MERGE only merge, etc.. REMOVE deletes child entities when parent deleted, preventing orphan records. @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true) ensures child deletion.
- What is the difference between @JoinColumn and mappedBy?
@JoinColumn specifies foreign key column on owning side of relationship. mappedBy attribute on non-owning side references owning side field name. Owning side contains foreign key and is responsible for relationship management. Bidirectional relationships require one side as owner and other side using mappedBy.
- How do you implement inheritance in JPA?
SINGLE_TABLE strategy stores all classes in one table with discriminator column. JOINED strategy creates separate tables for each class with foreign key joins. TABLE_PER_CLASS strategy creates complete tables for each concrete class. Each strategy has tradeoffs between normalization, query performance, and complexity.
- What is Hibernate Criteria API?
Criteria API provides type-safe programmatic query building without string-based queries. CriteriaBuilder creates query elements like predicates, selections, and ordering. CriteriaQuery represents typed query definition with root entity and query clauses. Metamodel classes provide compile-time checking of entity attributes.
- Explain native SQL queries in JPA.
Native SQL queries use database-specific SQL syntax for complex queries or performance optimization. @NamedNativeQuery defines reusable native queries on entity classes. ResultSetMapping maps native query results to entities or custom result classes. Native queries bypass JPA abstraction sacrificing portability for flexibility.
- What are entity listeners and callbacks?
Entity listeners execute logic at specific entity lifecycle points using annotations. @PrePersist executes before entity insertion, @PostPersist after insertion. @PreUpdate runs before update, @PostUpdate after update. @PostLoad executes after entity loading from database.
- How do you handle bidirectional relationships?
Define relationship on both sides with @OneToMany and @ManyToOne annotations. Specify mappedBy on non-owning side referencing owning side field. Create convenience methods maintaining both sides of relationship consistently. Bidirectional relationships enable navigation in both directions but require careful synchronization.
- What is the fetch join in JPQL?
Fetch join eagerly loads associated entities in single query preventing lazy initialization exceptions. Syntax: SELECT e FROM Entity e JOIN FETCH e.association. Multiple fetch joins can cause cartesian product with collection associations. Pagination with fetch joins requires careful handling to avoid incorrect results.
- Explain pagination in JPA.
Pagination uses setFirstResult() and setMaxResults() on Query for limiting results. Spring Data Pageable interface provides abstraction with page number, size, and sort. Return Page object containing results, total elements, total pages metadata. Database-specific SQL is generated for efficient pagination.
- What is EntityGraph in JPA?
EntityGraph defines fetch plan controlling which relationships are eagerly loaded. @NamedEntityGraph annotation declares reusable entity graphs on entities. Dynamic entity graphs created programmatically for flexible fetch strategies. Entity graphs provide alternative to fetch joins with cleaner separation of concerns.
- How do you implement soft delete in JPA?
Add boolean deleted flag or deletedDate timestamp to entities. Override @Where(clause = “deleted = false”) for automatic filtering. Implement custom repository methods handling soft delete logic. Soft delete preserves data for auditing while hiding from normal queries.
- What is Hibernate’s StatelessSession?
StatelessSession provides lightweight session without caching or automatic dirty checking. Useful for bulk operations where caching overhead isn’t beneficial. Entities loaded through stateless session are immediately detached. StatelessSession offers better performance for batch processing scenarios.
- Explain transaction management in JPA.
@Transactional annotation demarcates transaction boundaries declaratively. REQUIRED propagation (default) joins existing transaction or creates new one. REQUIRES_NEW suspends current transaction starting independent transaction. Isolation levels control concurrent transaction visibility and locking behavior.
- What is the difference between save() and saveAndFlush()?
save() persists entity to persistence context, delaying database write until flush/commit. saveAndFlush() persists entity and immediately flushes changes to database. Use saveAndFlush() when generated IDs or trigger logic needed immediately. Flush incurs performance overhead, use sparingly for performance-critical operations.
- How do you implement audit fields in JPA?
Enable JPA auditing with @EnableJpaAuditing and create @EntityListeners(AuditingEntityListener.class). Add @CreatedDate, @LastModifiedDate, @CreatedBy, @LastModifiedBy to base entity. Implement AuditorAware interface providing current user for audit tracking. Auditing tracks who created/modified entities and when automatically.
- What are embeddable objects in JPA?
@Embeddable classes are value objects embedded into entity tables without separate table. Multiple entities can reuse embeddable objects like Address, ContactInfo. @Embedded annotation includes embeddable object in entity. Attribute overrides customize column mappings for embedded objects.
- Explain composite primary keys in JPA.
@IdClass annotation defines separate class containing primary key fields. @EmbeddedId uses embeddable object as primary key with @Embeddable. Composite key classes must implement Serializable and override equals/hashCode. Use composite keys only when genuinely needed as they increase complexity.
- What is JPQL vs Criteria API vs QueryDSL?
JPQL provides string-based object-oriented query language similar to SQL. Criteria API offers type-safe programmatic query building preventing syntax errors. QueryDSL provides fluent, type-safe query API with better readability than Criteria. Choose based on complexity, type safety requirements, and team familiarity.
- How do you handle large result sets efficiently?
Use pagination limiting results per page rather than loading all records. Stream API with Spring Data enables processing results without loading all into memory. Stateless sessions suitable for read-only batch processing. Projection queries fetch only needed columns reducing memory consumption.
- What is the difference between Hibernate and JPA?
JPA is specification defining standard API for object-relational mapping. Hibernate is implementation of JPA specification plus additional features. Code to JPA interfaces enables swapping Hibernate for other providers. Hibernate-specific features include caching strategies, custom types, advanced fetching.
- Explain query result transformation.
ResultTransformer shapes query results into desired format like DTOs or collections. Projections select specific fields creating lightweight result objects. Constructor expressions in JPQL directly instantiate result objects: SELECT new DTO(fields). Transformations reduce memory footprint and improve performance.
- How do you implement multi-tenancy in JPA?
Separate schema approach creates database schema per tenant. Separate database uses different databases per tenant with connection routing. Shared schema with discriminator column includes tenant ID in all tables. Hibernate multi-tenancy support requires custom MultiTenantConnectionProvider and CurrentTenantIdentifierResolver.
- What is Hibernate’s batch processing?
Batch processing accumulates multiple operations executing them in single batch. Configure hibernate.jdbc.batch_size for optimal batch size. Call session.flush() and session.clear() periodically to prevent memory issues. Batch processing dramatically improves performance for bulk inserts/updates.
Design Patterns
- What are Design Patterns and why are they important?
Design patterns are reusable solutions to commonly occurring software design problems within specific contexts. They provide proven development paradigms accelerating development process and improving code maintainability. Patterns communicate design intent clearly among team members using shared vocabulary. Understanding patterns is essential for writing scalable, flexible enterprise applications.
- Explain the Singleton pattern and its implementation.
Singleton ensures a class has only one instance providing global access point. Implementation uses private constructor, static instance variable, and public static getInstance() method. Thread-safe variants include synchronized method, double-checked locking, or eager initialization. Use cases include database connection pools, configuration managers, and logging frameworks.
- What is the Factory pattern?
Factory pattern creates objects without exposing creation logic to clients, referring to newly created objects using common interface. Simple Factory uses single factory class, Factory Method uses inheritance, Abstract Factory handles families of related objects. Factory pattern promotes loose coupling by eliminating direct object instantiation. Used extensively in frameworks like Spring for bean creation.
- Explain the Builder pattern.
Builder pattern constructs complex objects step-by-step separating object construction from representation. It uses fluent interface with method chaining returning builder instance. Builder pattern improves readability for objects with many optional parameters avoiding telescoping constructors. Lombok’s @Builder annotation generates builder classes automatically.
- What is the Adapter pattern?
Adapter pattern converts interface of class into another interface clients expect, enabling incompatible interfaces to work together. Class adapter uses inheritance, object adapter uses composition. Common use case is adapting legacy code or third-party libraries to work with application interfaces. Spring’s JPA repository adapters exemplify this pattern.
- Explain the Decorator pattern.
Decorator pattern attaches additional responsibilities to object dynamically providing flexible alternative to subclassing. Decorators wrap original object, implementing same interface and forwarding calls. Multiple decorators can be stacked adding behaviors incrementally. Java’s InputStream classes (BufferedInputStream, GZIPInputStream) demonstrate decorator pattern.
- What is the Strategy pattern?
Strategy pattern defines family of algorithms, encapsulates each one, and makes them interchangeable. Context class delegates to strategy interface allowing algorithm selection at runtime. Strategy eliminates conditional statements replacing them with polymorphic behavior. Used in Spring for transaction management, caching strategies, and sorting algorithms.
- Explain the Observer pattern.
Observer pattern defines one-to-many dependency where state changes in subject notify all dependent observers automatically. Observers register with subject receiving updates when subject state changes. Promotes loose coupling between subject and observers. Event-driven architectures and reactive programming use observer extensively.
- What is the Template Method pattern?
Template Method defines algorithm skeleton in base class, deferring some steps to subclasses without changing algorithm structure. Abstract methods in template represent customizable steps. This pattern promotes code reuse for common algorithm structures with varying implementations. Spring’s JdbcTemplate and RestTemplate use template method pattern.
- Explain the Proxy pattern.
Proxy pattern provides surrogate or placeholder controlling access to another object. Virtual proxy delays expensive object creation, protection proxy controls access rights, remote proxy represents objects in different address spaces. Spring AOP proxies enable cross-cutting concerns like transactions and security. Dynamic proxies create proxy classes at runtime.
- What is Dependency Injection pattern?
Dependency Injection inverts control flow by injecting dependencies from external source rather than objects creating their own. Constructor injection provides dependencies through constructors, setter injection through setters, interface injection through methods. DI promotes testability, loose coupling, and configuration flexibility. Spring framework extensively implements DI pattern.
- Explain the Repository pattern.
Repository pattern mediates between domain and data mapping layers using collection-like interface for accessing domain objects. Repositories encapsulate data access logic hiding storage implementation details. Spring Data JPA repositories provide abstraction over JPA entity management. Repository pattern centralizes common data access functionality.
- What is the Service Layer pattern?
Service Layer pattern defines application boundary with set of available operations coordinating application responses in each operation. Services contain business logic, orchestrate transactions, and delegate to repositories. Service layer promotes separation of concerns keeping controllers thin. Spring’s @Service annotation marks service layer components.
- Explain the DTO (Data Transfer Object) pattern.
DTO pattern transfers data between software application subsystems using objects designed specifically for data transfer. DTOs reduce number of method calls, encapsulate serialization, and decouple internal models from API contracts. MapStruct or ModelMapper libraries facilitate DTO-entity conversions. DTOs prevent over-fetching and exposure of sensitive entity details.
- What is the Circuit Breaker pattern?
Circuit Breaker prevents application from repeatedly trying to execute operation likely to fail, allowing it to continue without waiting for fault to be fixed. States include Closed (normal), Open (failures exceed threshold), Half-Open (testing recovery). Resilience4j and Hystrix provide circuit breaker implementations. Essential for microservices resilience and cascade failure prevention.
- Explain the Saga pattern.
Saga pattern manages distributed transactions across microservices using sequence of local transactions where each transaction updates database and publishes event triggering next transaction. Choreography-based sagas use events, orchestration-based sagas use central coordinator. Compensating transactions handle failures by undoing completed steps. Saga maintains data consistency without distributed transactions.
- What is the CQRS pattern?
Command Query Responsibility Segregation separates read and write operations using different models. Commands change state without returning data, queries return data without changing state. CQRS enables independent scaling, optimization, and security for reads vs writes. Event sourcing commonly pairs with CQRS.
- Explain the Event Sourcing pattern.
Event Sourcing stores application state as sequence of events rather than current state snapshots. Events are immutable, append-only records of state changes. Application state reconstructed by replaying events from beginning. Benefits include complete audit trail, temporal queries, and debugging capabilities.
- What is the API Composition pattern?
API Composition pattern implements queries joining data from multiple services by invoking respective services and combining results. API composer calls multiple services in parallel or sequence, aggregating responses. Challenges include higher latency, inconsistent data, and complex error handling. Used when data ownership is distributed across microservices.
- Explain the Strangler Fig pattern.
Strangler Fig pattern gradually migrates legacy system by incrementally replacing functionality with new services. Facade routes requests to legacy system or new services based on migrated functionality. This enables risk-free migration without big-bang rewrites. Pattern named after strangler fig trees that grow around host trees.
Build Tools, Testing & DevOps
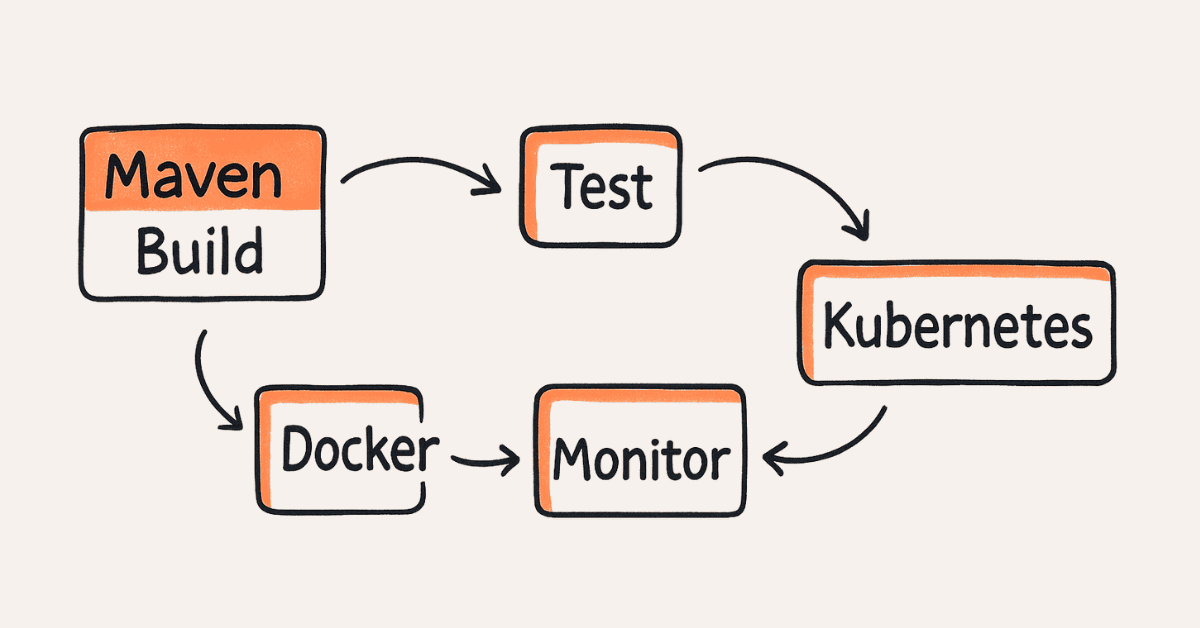
- What is Maven and its purpose?
Maven is build automation and project management tool using XML (pom.xml) for configuration. It manages dependencies, builds projects, runs tests, and packages applications following convention-over-configuration. Maven Central Repository hosts millions of libraries with transitive dependency resolution. Multi-module projects managed through parent-child POM relationships.
- Explain Maven’s project lifecycle.
Maven has three built-in lifecycles: default (handles project deployment), clean (handles project cleaning), site (handles site documentation). Default lifecycle phases include validate, compile, test, package, verify, install, deploy. Each phase executes in order with all preceding phases. Plugins bind to lifecycle phases to perform actual work.
- What is the difference between Maven and Gradle?
Maven uses XML for configuration, Gradle uses Groovy/Kotlin DSL offering more flexibility. Gradle builds faster through incremental builds and build caching. Maven follows strict conventions, Gradle provides more customization. Gradle gaining popularity for Android and modern Java projects.
- What are Maven scopes?
Compile scope (default) makes dependencies available in all classpaths. Provided scope expects JDK or container to provide dependency at runtime. Runtime scope needed for execution but not compilation. Test scope available only for test compilation and execution.
- Explain Maven dependency management.
Maven downloads dependencies from repositories (local, central, remote) automatically. Transitive dependencies pulled automatically reducing manual configuration. Dependency mediation resolves version conflicts using nearest definition or first declaration. Exclusions remove unwanted transitive dependencies.
- What is JUnit and why is it important?
JUnit is popular testing framework for Java enabling test-driven development and regression testing. Annotations like @Test, @Before, @After structure test cases. JUnit assertions verify expected behavior with methods like assertEquals(), assertTrue(). Continuous Integration relies on automated JUnit tests.
- Explain JUnit 5 architecture.
JUnit 5 comprises JUnit Platform (foundation), JUnit Jupiter (programming model), and JUnit Vintage (backward compatibility). Platform launches testing frameworks on JVM. Jupiter provides annotations, assertions, and assumptions for writing tests. Vintage runs JUnit 3 and 4 tests.
- What are JUnit annotations?
@Test marks method as test case. @BeforeEach runs before each test method, @AfterEach runs after. @BeforeAll runs once before all tests, @AfterAll runs once after. @Disabled skips test execution, @DisplayName provides readable test names.
- What is Mockito?
Mockito is mocking framework creating mock objects for unit testing, isolating code under test. Mock objects simulate real object behavior without executing actual implementation. When-thenReturn syntax defines mock behavior, verify checks method invocations. Mockito essential for testing with external dependencies.
- Explain test doubles: Mock, Stub, Spy.
Mock objects verify interactions recording method calls for later verification. Stubs provide predefined responses to method calls without verification. Spies wrap real objects allowing partial mocking with real method calls. Each serves different testing purposes based on verification needs.
- What is Test-Driven Development (TDD)?
TDD writes tests before implementation following Red-Green-Refactor cycle. Red: write failing test, Green: write minimum code to pass, Refactor: improve code without changing behavior. TDD improves code quality, design, and confidence in changes. Tests serve as living documentation.
- What is CI/CD?
Continuous Integration automatically builds and tests code changes frequently throughout the day. Continuous Deployment automatically deploys passing builds to production. CI/CD pipelines automate building, testing, and deployment reducing manual errors. Jenkins, GitLab CI, GitHub Actions are popular tools.
- What is Docker?
Docker is containerization platform packaging applications with dependencies into portable containers. Containers are lightweight, isolated environments sharing host OS kernel unlike VMs. Docker images built from Dockerfile instructions define application environment. Containers ensure consistency across development, testing, production.
- Explain Docker vs Virtual Machine.
Containers share host OS kernel making them lightweight (MBs) compared to VMs (GBs). Containers start in seconds, VMs take minutes. VMs provide stronger isolation through hypervisor, containers offer process-level isolation. Containers better suited for microservices, VMs for running different OS.
- What is Kubernetes?
Kubernetes (K8s) is container orchestration platform automating deployment, scaling, and management of containerized applications. Key concepts include Pods (smallest deployable units), Services (network abstraction), Deployments (declarative updates). K8s provides self-healing, automatic scaling, rolling updates, service discovery. Essential for managing microservices at scale.
- Explain Kubernetes Pods and Services.
Pods are groups of one or more containers sharing storage and network. Pods are ephemeral, destroyed and recreated by controllers. Services provide stable network endpoints for pods enabling load balancing. Service types include ClusterIP (internal), NodePort (external), LoadBalancer (cloud).
- What is Git and its importance?
Git is distributed version control system tracking code changes and enabling collaboration. Every developer has complete repository history enabling offline work. Branching and merging facilitate parallel development and feature isolation. Git enables collaboration through platforms like GitHub, GitLab, Bitbucket.
- Explain Git branching strategies.
Git Flow uses main, develop, feature, release, hotfix branches for structured workflow. GitHub Flow uses main branch with feature branches for simpler workflow. Trunk-based development uses short-lived branches merging frequently to main. Choose strategy based on team size, release frequency, and deployment model.
- What are Git merge vs rebase?
Merge creates merge commit preserving complete history including branch structure. Rebase rewrites history moving commits to new base creating linear history. Merge maintains context of feature development, rebase creates cleaner history. Never rebase public branches, only local feature branches.
- Explain Git commands: pull, fetch, push.
Git fetch downloads changes from remote without merging into local branch. Git pull combines fetch and merge in single command. Git push uploads local commits to remote repository. Pull before pushing to avoid conflicts and keep history synchronized.
Microservices, Kafka & Cloud
- What are Microservices?
Microservices architecture structures application as collection of loosely coupled, independently deployable services. Each service owns its data, communicates via APIs, and can use different technology stacks. Benefits include scalability, resilience, faster deployment, technology flexibility. Challenges include distributed system complexity, data consistency, testing.
- What is Service Discovery?
Service Discovery enables services to find and communicate with each other dynamically without hard-coded addresses. Client-side discovery (Eureka) has clients query registry and load balance. Server-side discovery uses load balancer querying registry. Essential for dynamic cloud environments where instances come and go.
- Explain Netflix Eureka.
Eureka is service registry for resilient load balancing and failover. Eureka Server maintains registry of service instances with heartbeat mechanism. Eureka Client registers services and fetches registry for service discovery. Self-preservation mode prevents cascading failures during network partitions.
- What is API Gateway pattern?
API Gateway provides single entry point for clients routing requests to appropriate microservices. Gateway handles cross-cutting concerns: authentication, rate limiting, monitoring, request transformation. Spring Cloud Gateway offers non-blocking, reactive gateway with routing and filtering. Gateway reduces client complexity and enables centralized security.
- How does Spring Cloud Gateway work?
Spring Cloud Gateway uses Routes (ID, URI, predicates, filters) for request matching. Predicates evaluate request attributes determining route matching. Filters modify requests/responses before/after routing. Built on Spring WebFlux for reactive, non-blocking request handling.
- What is Apache Kafka?
Kafka is distributed streaming platform for building real-time data pipelines and streaming applications. It provides publish-subscribe messaging with high throughput, fault tolerance, and durability. Kafka stores messages in topics partitioned for parallelism and replication. Used for event streaming, log aggregation, metrics collection.
- Explain Kafka architecture components.
Producers publish messages to Kafka topics. Brokers are servers storing topic partitions and serving clients. Topics are categories or feed names for messages, divided into partitions. Consumers read messages from topics, organized into consumer groups. ZooKeeper manages cluster metadata though KRaft mode replacing it.
- What are Kafka topics and partitions?
Topics categorize messages into logical feeds. Partitions divide topics enabling parallelism and scalability. Each partition is ordered, immutable sequence of messages. Partitions enable multiple consumers reading simultaneously from different partitions. Partition key determines message partition assignment.
- Explain Kafka consumer groups.
Consumer group enables multiple consumers to coordinate consuming topic partitions. Each partition assigned to exactly one consumer in group ensuring parallel processing. Consumer groups enable horizontal scaling and fault tolerance. Rebalancing redistributes partitions when consumers join/leave group.
- What is Kafka offset?
Offset is unique sequential ID assigned to each message in partition. Consumers track their position using offsets. Kafka stores offsets in special topic enabling consumer recovery. Manual offset management provides control over message processing guarantees.
- How does Kafka ensure fault tolerance?
Kafka replicates partitions across multiple brokers for redundancy. Each partition has one leader and multiple follower replicas. Leaders handle reads/writes, followers replicate data passively. Leader election occurs automatically when leader fails. In-sync replica set ensures committed messages aren’t lost.
- What is Kafka message retention?
Kafka retains messages for configured period regardless of consumption. Time-based retention deletes messages older than specified duration. Size-based retention limits total partition size. Compacted topics retain only latest value per key. Retention enables replay and multiple consumer groups reading same data.
- Explain load balancing in microservices.
Load balancing distributes requests across multiple service instances improving availability and scalability. Client-side load balancing (Ribbon) allows clients to choose instances. Server-side load balancing uses dedicated load balancers (NGINX, HAProxy). Spring Cloud LoadBalancer provides abstraction over client-side load balancing.
- What is distributed tracing?
Distributed tracing tracks requests as they flow through multiple microservices. Correlation IDs link related requests across services. Spring Cloud Sleuth adds trace and span IDs to logs. Zipkin and Jaeger provide UI for visualizing traces. Essential for debugging distributed system issues.
- Explain centralized logging.
Centralized logging aggregates logs from all microservices into single location for analysis. ELK Stack (Elasticsearch, Logstash, Kibana) popular for log management. Structured logging (JSON format) enables better searching and filtering. Correlation IDs link logs across services. Centralized logging essential for monitoring distributed systems.
- What is container orchestration?
Container orchestration automates deployment, scaling, networking, and availability of containerized applications. Kubernetes is de facto standard for orchestration. Orchestration handles service discovery, load balancing, rolling updates, self-healing. Essential for managing microservices in production at scale.
- Explain blue-green deployment.
Blue-green deployment maintains two identical production environments (blue and green). New version deployed to inactive environment while active serves traffic. After testing, traffic switched to new version instantly. Easy rollback by switching back to previous environment. Minimizes downtime and risk during deployments.
- What is canary deployment?
Canary deployment gradually rolls out changes to small subset of users before full rollout. Traffic gradually shifted from old version to new version. Monitoring detects issues early with minimal user impact. Rollback possible at any stage during gradual rollout. Reduces risk compared to big-bang deployments.
- Explain database per service pattern.
Each microservice owns its database preventing tight coupling through shared database. Services access other service data only through APIs maintaining loose coupling. Enables independent scaling, technology choices, and schema evolution per service. Challenges include data consistency, joins, and transactions across services.
- What is the Backend for Frontend (BFF) pattern?
BFF pattern creates separate backend services for different frontend types (web, mobile, IoT). Each BFF optimized for specific frontend needs aggregating multiple service calls. Reduces frontend complexity and network overhead. Different teams can own frontend and corresponding BFF. Enables frontend-specific optimization and evolution.
🧩 Master Java Full Stack Hands-On Skills
Practice real tasks: APIs, JPA, Microservices, React Integration & Deployments.
2. Module : Self-Preparation Prompts Using ChatGPT

Coding Problem Practice Prompts
- Java Core Concepts Mastery
“I’m preparing for Java Full Stack interviews. Generate a medium-difficulty problem requiring implementation of [Collections, Streams, Multithreading, Design Patterns]. Include problem statement, constraints, example inputs/outputs, and edge cases. After I submit my solution, analyze time/space complexity and suggest Java-specific optimizations using modern Java features.”
- Spring Boot Application Debugging
“Present a Spring Boot application with subtle bugs in [dependency injection, transaction management, REST API design, JPA queries]. Don’t reveal bugs initially. Let me identify and fix them through code review, then provide detailed explanations of root causes and best practices for preventing similar issues.”
- Algorithm Pattern Recognition for Java
“Explain the [two pointers/sliding window/dynamic programming/backtracking] pattern with Java implementations. Provide 3 progressively difficult LeetCode-style problems using this pattern. For each problem, wait for my Java solution before revealing optimal approach with detailed complexity analysis.”
- Spring Framework Deep Dive
“I need to master [Spring Security JWT, Spring Data JPA optimization, Spring Cloud microservices, Spring Boot testing]. Create a comprehensive learning path with practical exercises building on each other. Include real-world scenarios, common pitfalls, and hands-on coding challenges.”
- Microservices Design Challenge
“Create a real-world microservices scenario requiring design of [e-commerce order system/banking transaction system/social media platform]. Guide me through service decomposition, API gateway design, service discovery, data consistency, and inter-service communication. Ask clarifying questions about scalability and fault tolerance.”
Technical Concept Clarification Prompts
- Java Memory Management Deep Dive
“I’m confused about [Java garbage collection algorithms, memory leaks in Java, heap vs stack memory, OutOfMemoryError troubleshooting]. Explain as if teaching an intermediate Java developer. Use real-world analogies, code examples demonstrating memory issues, and JVM tuning recommendations. Then quiz me with 3 scenario-based questions.”
- Hibernate/JPA Performance Optimization
“Explain N+1 query problem, lazy vs eager loading trade-offs, second-level caching strategies, and query optimization techniques. Provide code examples showing performance issues and solutions. Create 5 challenging exercises demonstrating these concepts with actual database queries.”
- Multithreading and Concurrency Mastery
“Deep dive into [Java concurrency utilities, thread pools, locks, volatile keyword, CompletableFuture]. Explain thread safety issues with examples, then present 5 concurrency problems requiring thread-safe implementations. Evaluate my solutions for correctness, performance, and best practices.”
- REST API Best Practices
“I need to master RESTful API design with Spring Boot. Cover HTTP methods, status codes, pagination, versioning, HATEOAS, error handling, and documentation with Swagger. Provide a complete API design exercise where I design endpoints for [specific domain], then critique my design decisions.”
- Design Pattern Application
“For each GoF design pattern [Singleton, Factory, Builder, Strategy, Observer, etc.], explain the problem it solves in Spring Boot context. Show Java implementation with Spring annotations. Then present a real-world scenario requiring pattern application and evaluate my implementation.”
Mock Interview Simulation Prompts
- Technical Screening Round Simulation
“Act as interviewer for Java Full Stack Developer position at FAANG company. Conduct 45-minute technical screening covering Java 8+ features, Spring Boot fundamentals, REST API design, and database optimization. Ask one question at a time, evaluate comprehensively, provide detailed feedback on technical accuracy and communication.”
- Live Coding Interview – Data Structures
“Simulate live coding interview presenting medium-hard algorithm problem from [arrays, trees, graphs, dynamic programming]. Give 30 minutes to solve. As I explain approach, ask clarifying questions and hint if stuck. After submission, critique solution efficiency, code quality, edge case handling, and problem-solving methodology.”
- System Design Interview – E-commerce Platform
“Conduct system design interview for designing [Amazon-like e-commerce/Netflix streaming/Uber ride-sharing]. Guide through requirements gathering, capacity estimation, database schema, microservices architecture, caching strategy, message queues. Challenge decisions with follow-up questions about trade-offs and scalability.”
- Spring Boot Architecture Review
“Present a Spring Boot microservices application with architectural issues: tight coupling, missing error handling, poor transaction management, security vulnerabilities, performance bottlenecks. Give 20 minutes to identify problems and propose improved architecture with Spring Cloud components.”
- Database Design and Optimization Interview
“Conduct interview on database design for [complex domain]. Cover normalization, indexing strategies, query optimization, transaction isolation, N+1 problem solutions, caching strategies. Present slow queries requiring optimization through indexing, rewriting, or application-level caching.”
Code Review and Feedback Prompts
- Spring Boot Code Quality Assessment
“Review this Spring Boot controller/service/repository code for: proper layering, exception handling, transaction management, validation, logging, testing coverage, Spring best practices. Identify code smells, security issues, performance problems. Provide refactored version with explanations.”
- Java Security Vulnerability Analysis
“Analyze this Java REST API for security vulnerabilities: SQL injection, XSS, CSRF, authentication bypass, insecure deserialization, sensitive data exposure. Explain each vulnerability’s impact and provide secure implementation using Spring Security best practices.”
- Microservices Communication Review
“Review this microservices implementation checking: service boundaries, API contracts, error propagation, distributed tracing, circuit breakers, retry mechanisms, eventual consistency handling. Identify antipatterns and suggest improvements using Spring Cloud components.”
- JPA Query Performance Optimization
“Analyze these JPA repositories for performance issues: N+1 queries, cartesian products, missing indexes, inefficient fetching. Show query execution plans, explain bottlenecks, provide optimized versions using fetch joins, entity graphs, or native queries with performance metrics.”
- Testing Strategy Evaluation
“Review this Spring Boot testing suite covering unit tests, integration tests, and API tests. Evaluate test coverage, mock usage, test data management, assertion quality. Suggest improvements using JUnit 5, Mockito, TestContainers, and Spring Boot test annotations.”
Problem-Solving Strategy Prompts
- Debugging Production Issues
“Simulate production issue: [memory leak, high CPU usage, slow database queries, intermittent failures]. Guide me through: analyzing logs, heap dumps, thread dumps, database query plans. Don’t give solutions immediately; ask diagnostic questions helping me identify root cause systematically.”
- Multiple Implementation Approaches
“For this problem [business logic requirement], generate 3 different Java solutions: basic approach, optimized approach using Java 8 streams, and highly performant approach with caching/parallelization. Compare trade-offs: readability, performance, memory usage, maintainability.”
- Refactoring Legacy Code
“Present legacy Spring application code with: poor structure, lack of tests, hard-coded values, tight coupling, no dependency injection. Guide me through refactoring to modern Spring Boot application: extracting interfaces, adding DI, writing tests, externalizing configuration.”
- Architectural Decision Making
“For [specific technical decision like SQL vs NoSQL, monolith vs microservices, synchronous vs asynchronous, REST vs GraphQL], present trade-offs considering: team size, scalability needs, consistency requirements, operational complexity, budget constraints. Help me make justified decision.”
- Spring Boot vs Plain Java Trade-offs
“Present scenarios where I must choose between Spring Boot, plain Java, or alternative frameworks. Discuss: startup time, resource consumption, development speed, testing complexity, deployment options. Help evaluate based on project constraints and team expertise.”
Technical Communication Prompts
- Explaining Complex Java Concepts Simply
“I need to explain [Java garbage collection, Spring AOP, JPA caching, microservices patterns] to: junior developer, product manager, and tech lead. Evaluate each explanation for: appropriate complexity, use of analogies, clarity, engagement. Provide improved versions tailored to each audience.”
- Technical Documentation Writing
“Review my: API documentation, README file, architectural decision record, runbook. Evaluate for: completeness, clarity, code examples, setup instructions, troubleshooting guides. Suggest improvements following documentation best practices for enterprise Java applications.”
- Architecture Presentation Preparation
“I’m presenting microservices architecture to technical leadership. Prepare me for questions about: service boundaries, data consistency, deployment strategy, monitoring, disaster recovery. Simulate tough questions and evaluate my responses for technical accuracy and business justification.”
- Code Review Communication
“Simulate code review where I must provide constructive feedback on: poor naming, missing tests, inefficient queries, security issues. Teach me to: identify issues diplomatically, suggest alternatives, explain rationale, balance perfectionism with pragmatism.”
- Technical Interview Question Clarification
“Present intentionally ambiguous technical questions about: system design, data modeling, performance optimization. Train me to ask clarifying questions about: scale expectations, consistency requirements, existing infrastructure, non-functional requirements before proposing solutions.”
Specialized Java Full Stack Topics
- Spring Security Advanced Implementation
“Deep dive into: JWT token management, OAuth2 flows, role-based access control, method-level security, CORS configuration, CSRF protection. Create 10 scenario-based security requirements and evaluate my Spring Security implementations for correctness and best practices.”
- Kafka Integration with Spring Boot
“Guide me through: producer/consumer configuration, topic design, partition strategies, offset management, error handling, exactly-once semantics. Present real-world event-driven architecture scenarios requiring Kafka integration and evaluate my design decisions.”
- Docker and Kubernetes for Java Apps
“Explain: Dockerizing Spring Boot apps, multi-stage builds, container optimization, Kubernetes deployments, service discovery, config maps, secrets management. Walk me through deploying microservices to Kubernetes cluster with proper health checks and resource limits.”
- Performance Tuning Java Applications
“Present slow Java application requiring optimization. Guide through: profiling with JProfiler/VisualVM, analyzing thread dumps, optimizing JVM parameters, database connection pooling, caching strategies. Help identify bottlenecks and implement performance improvements with before/after metrics.”
- CI/CD Pipeline for Java Projects
“Design CI/CD pipeline for Spring Boot microservices using: Jenkins/GitLab CI, Maven/Gradle builds, unit/integration tests, Docker builds, Kubernetes deployments, rollback strategies. Include: code quality checks, security scanning, automated testing, blue-green deployments.”
Progressive Learning Prompts
- 90-Day Java Full Stack Mastery Plan
“Create structured 90-day plan covering: Core Java advanced topics (weeks 1-2), Spring Framework/Boot (weeks 3-6), Microservices and Spring Cloud (weeks 7-9), Frontend integration (weeks 10-11), DevOps and deployment (week 12). Include daily goals, projects, and weekly assessments.”
- LeetCode Problem-Solving Strategy
“I’m solving LeetCode problems for Java interviews. Help me develop strategy for: categorizing problems by patterns, tracking progress, learning from mistakes. Review my solutions providing: algorithmic improvements, Java-specific optimizations, pattern recognition insights.”
- Building Complete Portfolio Project
“Guide me building comprehensive Java Full Stack project: [e-commerce platform, task management system, social network]. At each phase (requirements, database design, backend APIs, frontend, testing, deployment), explain best practices, review implementation, suggest enhancements.”
- Open Source Contribution Preparation
“Prepare me for contributing to Spring Framework or popular Java open source projects. Guide through: finding good first issues, understanding codebase, following contribution guidelines, writing tests, creating pull requests. Review my proposed contributions before submission.”
- Interview Simulation Series – Progressive Difficulty
“Conduct 5 mock interviews increasing difficulty: phone screening, technical deep-dive, live coding, system design, hiring manager round. After each, provide comprehensive feedback: strengths demonstrated, areas needing improvement, specific topics to review, practice recommendations.”
Real-World Scenario Practice
- Production Incident Response
“Simulate production incidents: database connection pool exhaustion, memory leak causing OutOfMemoryError, Redis cache failures, Kafka consumer lag. Guide me through: incident detection, impact assessment, immediate mitigation, root cause analysis, long-term fixes.”
- Code Migration Scenarios
“Present migration scenarios: Java 8 to Java 17, monolith to microservices, SQL to NoSQL, REST to GraphQL. Guide through: impact analysis, migration strategy, backward compatibility, testing approach, rollout plan. Evaluate my migration proposals for risks and feasibility.”
- Cross-Functional Collaboration
“Simulate scenarios requiring collaboration with: frontend developers (API contract design), DevOps (deployment requirements), QA (testability improvements), product managers (technical feasibility). Teach effective communication and compromise in each situation.”
- Technical Debt Management
“Present codebase with technical debt: deprecated dependencies, missing tests, hard-to-maintain code, performance issues. Help me prioritize improvements, estimate effort, create refactoring plan, balance new features with debt reduction, communicate needs to stakeholders.”
- Scalability Challenge Scenarios
“System experiencing: 10x traffic growth, database becoming bottleneck, increased latency, higher error rates. Guide through: identifying bottlenecks, implementing caching, database sharding, horizontal scaling, load testing. Evaluate solutions for effectiveness and operational complexity.
✨ Follow Your Java Full Stack Learning Path
Step-by-step growth: Core Java → Spring Boot → Microservices → Frontend.
3. Module : Communication Skills and Behavioural Interview Preparation
Understanding the STAR Method
The STAR method structures behavioral responses using Situation (20%), Task (10%), Action (60%), and Result (10%). Focus majority of response on actions taken, using “I” rather than “we” to showcase personal contributions. This framework delivers clear, compelling stories demonstrating relevant skills and experiences for Java Full Stack developer roles.

Common Behavioral Questions for Java Developers
- Tell me about a challenging technical problem you solved.
Describe specific technical challenge involving [complex algorithm, system design, performance issue, integration problem]. Explain the business impact and urgency, detail analysis and research conducted, describe multiple approaches considered with trade-offs. Highlight Java-specific solutions implemented, testing conducted, and quantified outcomes like performance improvements or cost savings.
- Describe a time you had to learn a new technology quickly.
Explain business need driving the learning requirement [new framework, cloud platform, message queue]. Describe structured learning approach: documentation, tutorials, sample projects, mentors consulted. Detail how knowledge was applied to deliver value, challenges encountered during learning, and long-term benefits gained. Demonstrate enthusiasm for continuous learning essential in Java ecosystem.
- How do you handle disagreements about technical approaches?
Describe technical debate about [architectural decision, technology choice, design pattern]. Explain your perspective and reasoning, alternative viewpoints from team members, and how evidence was gathered. Detail how you facilitated discussion using: proof-of-concepts, performance benchmarks, trade-off analysis, consensus-building. Present resolution reached and positive project impact demonstrating collaboration.
- Tell me about a time you made a mistake and how you handled it.
Describe error honestly [production bug, architectural mistake, missed requirement] and its context. Explain immediate actions taken: identifying scope, communicating stakeholders, implementing hotfix. Detail root cause analysis conducted, preventive measures established: improved testing, code reviews, monitoring. Emphasize lessons learned and how they influenced future development practices.
- Describe working under tight deadlines with multiple priorities.
Present high-pressure situation with competing demands [multiple projects, urgent production issues, tight release schedules]. Explain prioritization framework used: business impact assessment, stakeholder communication, task breakdown. Detail organizational strategies: daily standups, Kanban boards, delegation to teammates, scope negotiation. Present successful delivery outcomes despite constraints demonstrating time management.
- How do you ensure code quality in your projects?
Discuss code quality practices: unit testing with JUnit, integration testing, code reviews, static analysis tools. Explain personal standards: meaningful naming, SOLID principles, design patterns, comprehensive documentation. Describe team practices established: review guidelines, testing standards, CI/CD pipelines catching issues early. Quantify quality improvements: reduced bugs, increased coverage, faster development cycles.
- Tell me about mentoring or helping junior developers.
Describe mentorship situation: onboarding new developer, teaching Spring Boot, reviewing code. Explain teaching approach customized to learning style: pair programming, code walkthroughs, resource recommendations. Detail specific guidance provided on: best practices, debugging techniques, architectural patterns. Present measurable improvements in mentee’s performance or confidence demonstrating leadership potential.
- Describe a project you’re most proud of.
Choose project demonstrating technical depth and business value [microservices migration, performance optimization, greenfield development]. Explain project scope, your specific role and responsibilities within team context. Detail innovative solutions or technical excellence: architectural decisions, performance optimizations, scalability implementations. Quantify results: user adoption, performance gains, cost savings, or technical metrics making impact tangible.
- How do you handle receiving critical feedback?
Describe feedback received about [code quality, architectural decision, communication style] and context. Explain initial reaction: processing feedback objectively, seeking clarification, understanding perspective. Detail specific actions taken: improving practices, seeking additional training, soliciting follow-up feedback. Present evidence of improvement and positive outcomes from implementing changes demonstrating coachability.
- Explain a complex technical concept to non-technical stakeholders.
Describe situation requiring technical translation [microservices benefits, cloud migration, API design] for business audiences. Explain challenge of bridging knowledge gaps while maintaining accuracy. Detail techniques used: business-focused analogies, visual diagrams, incremental explanations, avoiding jargon. Present outcomes: stakeholder understanding achieved, buy-in secured, successful project approval.
Effective Technical Communication
- Articulating Problem-Solving During Interviews
Verbalize thought process by explaining: problem understanding, constraint identification, solution exploration, trade-off evaluation. Use structured frameworks: “First, I analyze requirements; Second, I consider these approaches; Third, I evaluate trade-offs”. This demonstrates organized thinking helping interviewers follow reasoning even if final solution isn’t perfect.
- Explaining Java Code and Architecture Decisions
Start with high-level architecture before implementation details when walking through Spring Boot applications. Explain “why” behind decisions connecting technical choices to: business requirements, performance goals, maintainability needs. Use clear analogies for complex concepts and check understanding by pausing for questions.
- Handling “I Don’t Know” Gracefully
Acknowledge knowledge gaps honestly rather than fabricating answers demonstrating intellectual honesty. Follow immediately with related knowledge or logical approach: “I haven’t used that Spring Cloud component, but based on my experience with similar patterns, I would…”. This shows problem-solving resourcefulness and honesty valued in team environments.
- Active Listening in Technical Discussions
Take notes during problem statements, ask clarifying questions before jumping to solutions, paraphrase requirements confirming understanding. This prevents solving wrong problems and demonstrates attention to detail crucial in full stack development. Interviewers often provide hints during discussions that active listeners catch.
- Managing Interview Nervousness
Control anxiety through breathing techniques, positive self-talk, reframing nervousness as excitement. If stuck during coding: “Let me take a moment to think through this systematically”. Thinking aloud and maintaining composure under pressure impresses interviewers more than silent freezing.
Teamwork and Collaboration
- Code Review Best Practices
Demonstrate openness to feedback and constructive approach to reviewing others’ code. Explain how reviews are learning opportunities, techniques for delivering tactful feedback, incorporating suggestions to improve quality. This reveals collaboration skills and ego management crucial for team success.[48][51][47]
- Contributing to Team Knowledge Sharing
Provide concrete examples: creating documentation, conducting brown bag sessions, writing technical blog posts, mentoring teammates. Demonstrate commitment to collective success beyond individual contributions. Knowledge sharing essential in full stack roles spanning multiple technology domains.
- Working in Agile Teams
Describe experience with Agile ceremonies: sprint planning, daily standups, retrospectives, sprint reviews. Explain how you contribute to: story refinement, estimation, identifying blockers, continuous improvement. Discuss adapting to changing requirements and maintaining velocity under uncertainty.
- Cross-Functional Collaboration
Share examples working with: frontend developers on API contracts, DevOps on deployment strategies, QA on testability, product managers on technical feasibility. Demonstrate ability to: understand different perspectives, find compromises, communicate technical concepts appropriately.
Java Developer-Specific Behavioral Questions
- Why did you choose Java for your career?
Discuss Java’s strengths: enterprise adoption, rich ecosystem, strong community, backward compatibility, versatility. Explain personal attraction: robust frameworks like Spring, career opportunities, continuous evolution, large-scale system capabilities. Connect to career goals and passion for building scalable, maintainable applications.
- How do you stay updated with Java ecosystem?
Mention specific habits: following Java blogs, attending conferences/meetups, contributing to open source, completing online courses. Discuss recent Java features learned (Java 17, Virtual Threads, Records) and their applications. Demonstrate commitment to continuous learning in rapidly evolving landscape.
- Describe your experience with Spring Framework.
Discuss progression: starting with Spring Boot, expanding to Spring Data, Spring Security, Spring Cloud. Explain favorite features and why: dependency injection for testability, auto-configuration for productivity, comprehensive ecosystem. Share specific projects where Spring solved complex problems effectively.
- How do you approach microservices development?
Discuss principles followed: domain-driven design, API-first approach, database per service, observability. Explain challenges encountered: distributed tracing, eventual consistency, service communication, and solutions implemented. Demonstrate understanding of when microservices are appropriate vs monolith.
- What’s your testing philosophy?
Describe testing pyramid approach: unit tests (70%), integration tests (20%), end-to-end tests (10%). Explain practices: TDD when appropriate, test coverage goals, mutation testing, contract testing for microservices. Discuss balance between test coverage and development velocity.
- How do you handle legacy Java code?
Describe strategies: understanding before changing, adding tests incrementally, strangler fig pattern for rewrites, documenting as you learn. Explain patience required and balancing improvements with new features. Share specific refactoring successes and lessons learned.
Questions to Ask Interviewers
- About the Technology Stack
“What Java version and Spring Boot version is the team using? Are there plans to upgrade?”
“How does the team handle database migrations and schema evolution?”
“What’s the testing strategy and expected code coverage?”
- About Development Practices
“What does the code review process look like?”
“How frequently do you deploy to production?”
“What monitoring and observability tools are in place?”
“How does the team handle technical debt?”
- About Team and Growth
“What opportunities exist for learning new technologies?”
“How does the team share knowledge and mentor junior developers?”
“What does career progression look like for Java developers here?”
“Are there opportunities to contribute to architectural decisions?”
- About the Challenges
“What are the biggest technical challenges the team is currently facing?”
“How does the team balance feature development with system reliability?”
“What keeps you excited about working here?”
- About the Role
“What does success look like in the first 90 days?”
“What’s the team’s approach to work-life balance?”
“How much of the work is maintenance vs new development?”
“What’s the split between frontend and backend work in this role?
💼 Become Interview-Ready With Hands-On Training
Master real-time projects & interview-specific topics in our
Java Full Stack Course.
4. Module : Time Management, Assignments, Stress Management, and Follow-up
Time Management Strategies During Interviews
- Interview Time Allocation Framework
During 45-60 minute Java coding interviews, allocate time strategically: 5-7 minutes understanding problem and clarifying requirements, 8-10 minutes planning solution approach and discussing trade-offs, 25-30 minutes implementing with proper Java syntax and best practices, 12-15 minutes testing with edge cases and explaining complexity. This structured breakdown prevents rushing through implementation or running out of time before demonstrating test cases.
- Preparation Timeline for Java Developers
Entry-level developers (0-2 years experience) should allocate 4-6 months with 2-3 hours daily covering: Core Java fundamentals, data structures, algorithms, Spring Boot basics, and 50+ LeetCode problems. Mid-level developers (2-5 years) need 2-4 months with 1-2 hours daily focusing on: advanced Spring topics, system design, microservices patterns, and 100+ coding problems. Senior developers (5+ years) require 1-2 months reviewing: architectural patterns, leadership scenarios, advanced system design, and domain-specific problems.
- Daily Practice Schedule
Structure daily preparation: 30 minutes reviewing Java concepts (alternating core Java, Spring, JPA, microservices), 60 minutes solving coding problems (2-3 problems with increasing difficulty), 30 minutes studying system design or behavioral questions. Include 15-minute breaks between sessions and weekly progress reviews adjusting focus areas. Weekend time for building portfolio projects and mock interviews.
- Prioritization Matrix for Study Topics
Categorize topics using urgency/importance matrix: High priority (Core Java, Spring Boot, REST APIs, SQL, data structures), Medium priority (Spring Cloud, Kafka, Docker, system design), Lower priority (advanced JVM tuning, niche frameworks). Focus 70% time on high priority, 25% on medium, 5% on lower priority topics. Adjust based on job descriptions and identified weak areas.
- Efficient Learning Techniques
Use Pomodoro technique (25-minute focused sessions, 5-minute breaks) maintaining concentration during intensive study periods. Apply spaced repetition for retaining Java concepts and Spring annotations. Practice active recall: attempt problems before reviewing solutions, explain concepts aloud, teach others to reinforce learning. Create concise notes and flashcards for quick review before interviews.

Whiteboard Interview Best Practices
- Understanding Whiteboard Format
Whiteboard coding interviews typically last 45-60 minutes with 5-10 minutes problem introduction, 5 minutes clarification, 10-15 minutes solution design discussion, 20-30 minutes implementation on whiteboard, 5-10 minutes testing and optimization discussion. Interviewers evaluate problem-solving approach, code quality, communication skills, and handling of feedback beyond just correct solution.
- Structured Approach to Whiteboard Problems
Follow systematic process: restate problem confirming understanding, ask clarifying questions about inputs/outputs/constraints, discuss approach before coding explaining trade-offs, write clean code with proper Java syntax, test with examples including edge cases, discuss time/space complexity. This structure demonstrates organized thinking even if solution isn’t perfect.
- Communication During Whiteboard Coding
Think aloud throughout the process explaining reasoning: “I’m choosing HashMap for O(1) lookup”, “I’ll handle null inputs separately”, “This loop iterates n times giving O(n) complexity”. Verbalization helps interviewers follow logic and provide hints when needed. Silence signals struggle; continuous communication shows engagement and problem-solving process.
- Whiteboard Space Management
Plan layout before starting: reserve top-left for problem statement and examples, use center for main solution, keep right side for helper methods or scratch work. Write legibly in size visible from interviewer’s distance. Leave space between lines for insertions and corrections. Good spatial organization demonstrates planning and attention to detail.
- Handling Whiteboard Coding Challenges
When stuck, step back and verbalize the challenge: “I’m reconsidering the approach since this seems inefficient”. Welcome interviewer hints treating them as collaborators rather than adversaries. If making mistakes, acknowledge, cross out cleanly, and correct rather than erasing completely. Time management awareness without constant clock-checking through practiced internal pacing.
- Java-Specific Whiteboard Tips
Write clean Java syntax with proper: class structure, access modifiers, generics where appropriate, exception handling. Use Java Collections framework (ArrayList, HashMap, HashSet) rather than implementing from scratch. Demonstrate familiarity with Java 8+ features: streams, lambdas, Optional when appropriate. Comment complex logic explaining non-obvious algorithms.
- Testing and Edge Cases on Whiteboard
Walk through solution with provided example showing intermediate states. Identify and discuss edge cases: null inputs, empty collections, boundary values, large inputs. Explain how code handles each edge case referencing specific lines. Time permitting, trace through one edge case completely demonstrating thoroughness.
Take-Home Coding Assignment Excellence
- Understanding Assignment Scope
Read instructions 2-3 times taking detailed notes on requirements, constraints, and evaluation criteria. Identify must-have features vs nice-to-have enhancements prioritizing effort accordingly. Estimate time needed being realistic about scope achievable in given timeframe. If critical requirements are ambiguous, ask clarifying questions early rather than guessing.
- Project Planning Before Coding
Create implementation plan: database schema design, API endpoint list, component structure, test cases needed. Set up project structure properly: Maven/Gradle configuration, proper package organization, Spring Boot starters, development properties. Initialize Git repository with README outlining your plan and assumptions. Good planning saves time and demonstrates professionalism.
- Code Quality Standards
Write production-quality code following Java naming conventions, Spring Boot best practices, SOLID principles. Proper layering: controllers handling HTTP, services containing business logic, repositories managing data access. Meaningful variable/method names, consistent formatting, appropriate comments explaining complex logic. Use Spring annotations correctly: @RestController, @Service, @Repository, @Transactional.
- Testing Strategy for Assignments
Include unit tests for business logic using JUnit 5 and Mockito for mocking dependencies. Integration tests for API endpoints using @SpringBootTest and MockMvc. Repository tests using @DataJpaTest with H2 in-memory database. Aim for 70-80% coverage focusing on critical paths. Tests demonstrate quality consciousness and professional development practices.
- Comprehensive Documentation
Write detailed README including: project description, setup instructions with prerequisites, running application and tests, API endpoint documentation, database schema, assumptions made, technologies used, future improvements. Include examples of API requests/responses using curl or Postman. Architecture diagrams for complex projects showing component interactions. Quality documentation differentiates candidates significantly.
- Git Commit Strategy
Create logical, incremental commits showing development progression: initial setup, database entities, repository layer, service layer, controller layer, tests, documentation. Write meaningful commit messages: “Add User entity with JPA annotations”, “Implement authentication service with JWT”. Clean Git history demonstrates organized work approach and version control proficiency. Avoid single massive commit with all code.
- Going Beyond Requirements
After completing core requirements, consider enhancements demonstrating expertise: Docker containerization, API documentation with Swagger, exception handling with proper HTTP status codes, input validation, logging with proper levels, caching for performance. Document additional features clearly in README. Balance enhancement with time constraints avoiding over-engineering.
- Pre-Submission Checklist
Run all tests ensuring they pass. Check code with linters and formatters (CheckStyle, SpotBugs). Verify application runs cleanly on fresh clone without environment-specific configurations. Review README for completeness and clarity. Test API endpoints manually ensuring proper responses and status codes. Professional polish in final submission creates strong impression.
- Deployment Consideration
Deploy application to cloud platform (Heroku, AWS, Railway) providing live URL in README if possible. Include deployment instructions and environment variable configuration. Live demo more impressive than code review alone showing end-to-end delivery capability. If deployment not feasible, include Docker setup for easy local running.
- Time Management for Assignments
For multi-day assignments (3-5 days), aim to complete in 60-70% of time leaving buffer for polish and unexpected issues. Break work into manageable chunks spreading over multiple sessions avoiding last-minute rush. Track time spent on each component ensuring balanced attention. Early completion demonstrates efficiency; late submission suggests poor planning.
Managing Interview Stress and Anxiety
- Pre-Interview Physical Preparation
Get 7-8 hours sleep the night before interviews ensuring mental sharpness. Eat balanced breakfast providing sustained energy avoiding heavy foods causing sluggishness. Light exercise (walking, stretching) before interview releases nervous energy and improves focus. Stay hydrated throughout preparation and interview day.
- Mental Preparation Techniques
Visualize successful interview performance and positive interactions building confidence. Practice positive self-talk replacing “I might fail” with “I’m well-prepared and capable”. Review key achievements and projects boosting confidence in abilities. Prepare thoroughly as confidence comes from competence and preparation.
- Breathing and Relaxation Methods
Practice deep breathing: inhale 4 counts, hold 4 counts, exhale 4 counts before and during interviews. Focus on breathing when feeling overwhelmed bringing attention back to present moment. Progressive muscle relaxation: tense and release muscle groups reducing physical tension. These techniques lower heart rate and reduce anxiety symptoms.
- Reframing Nervousness Positively
Recognize nervousness as normal response even for experienced candidates. Reframe anxiety as excitement and readiness for challenge changing physiological interpretation. Remember interviewers want candidates to succeed and are generally supportive. View interviews as conversations and learning opportunities rather than interrogations.
- Handling Technical Difficulties Calmly
For virtual interviews, test equipment 30 minutes early having backup devices ready. If technical issues occur, communicate calmly: “I’m experiencing connection issues; let me reconnect”. Have interviewer contact information for quick resolution. Maintain composure as handling unexpected issues demonstrates professionalism.
- Recovery from Mistakes During Interview
When making coding errors, acknowledge without excessive apology: “Let me correct this”, then fix and continue. Don’t dwell on mistakes; maintain forward momentum and positive attitude. Interviewers expect some errors; recovery matters more than perfection. Learn from mistakes in real-time showing adaptability.
- Building Confidence Through Mock Interviews
Conduct 5-10 mock interviews with peers, mentors, or online platforms before real interviews. Record yourself answering questions identifying areas for improvement in communication. Use platforms like Pramp, interviewing.io for realistic practice with feedback. Repeated exposure reduces anxiety through familiarity with interview format.
- Post-Interview Reflection
Document questions asked, topics discussed, what went well, areas needing improvement after each interview. Avoid excessive self-criticism; focus on constructive learning points. Share experiences with peers learning from collective wisdom. Each interview improves skills regardless of outcome.
Post-Interview Follow-Up Excellence
- Thank-You Email Timing and Structure
Send thank-you email within 24 hours, ideally same day while conversation is fresh in interviewer’s mind. Use clear subject line: “Thank You – [Your Name] – Java Full Stack Developer Position”. Keep email concise (150-200 words): express gratitude, reference specific discussion points, reiterate interest, offer additional information if needed. Professional communication extends positive impression beyond interview.
- Personalizing Follow-Up Messages
Customize each email referencing unique conversation aspects: technical discussion about microservices architecture, interviewer’s questions about your Spring Boot experience, shared interests in specific technologies. Mention specific projects or challenges discussed demonstrating attentiveness. Generic templates appear insincere; personalization shows genuine engagement and attention to detail.
- Sample Thank-You Email for Java Developer
“Subject: Thank You – [Your Name] – Java Full Stack Developer Position
Dear [Interviewer Name],
Thank you for discussing the Java Full Stack Developer role at [Company] today. Our conversation about migrating your monolith to microservices using Spring Cloud was particularly engaging, and it reinforced my enthusiasm for contributing to your team.
I’m especially excited about the opportunity to work on [specific project discussed], and I’m confident my experience building scalable APIs with Spring Boot and implementing distributed tracing would enable immediate contributions.
Please let me know if you need additional information about my experience with [specific technology discussed]. I look forward to the next steps in your process.
Best regards,
[Your Name]
[LinkedIn URL] | [GitHub Profile]”
- Following Up on Promised Materials
If you committed to sending: GitHub repositories, portfolio projects, code samples, references, send within 24 hours professionally organized. Include brief context for each item: “Here’s the Spring Boot microservices project we discussed demonstrating my API design and Kafka integration experience”. Meeting commitments demonstrates reliability and follow-through.
- Handling Multiple Interviewers
Send individual thank-you emails to each interviewer personalizing content based on specific interactions. If you can’t obtain all email addresses, send general thank-you to HR contact requesting they share your gratitude. Individual emails show extra effort and genuine interest in building relationships.
- Timeline Inquiry Etiquette
If timeline wasn’t mentioned, politely ask in thank-you email: “Could you share the expected timeline for the next steps in your process?”. If provided timeline passes without communication, wait 2-3 business days then send brief follow-up: “I wanted to check on the status of my application for the Java Full Stack Developer position”. Professional persistence shows continued interest without appearing desperate.
- Graceful Response to Rejection
If rejected, send brief, gracious response thanking them for opportunity and expressing interest in future openings. Request feedback on areas for improvement: “I’d appreciate any feedback to help strengthen my candidacy for future opportunities”. Professional handling of rejection maintains positive relationships; many companies remember courteous candidates for future roles.
- Staying Connected Post-Interview
Connect on LinkedIn with interviewers and recruiters with personalized connection request referencing interview. Engage with company content occasionally showing genuine interest. When you learn new relevant skills or complete significant projects, share updates keeping you top-of-mind. Professional network building extends beyond single interview.
- Learning from Interview Experience
Create post-interview reflection document: questions asked, topics covered, what went well, areas needing improvement, new concepts encountered. Review technical questions you struggled with, study those topics deeply for future interviews. Track interview patterns across companies identifying common focus areas. Each interview regardless of outcome improves your skills and preparation.
- Managing Multiple Offers
If receiving multiple offers, communicate professionally with all companies about timeline needs. Request reasonable time (3-5 days) to evaluate offers without excessive delay. Consider: compensation, technology stack, team culture, growth opportunities, work-life balance. Once decided, notify declined companies promptly and professionally maintaining relationships.
Final Interview Day Preparation
- Technical Setup for Virtual Java Interviews
Test webcam, microphone, internet connection 30 minutes before interview. Ensure IDE ready (IntelliJ IDEA or Eclipse) with proper Java SDK installed if live coding expected. Close unnecessary applications preventing notifications or performance issues. Have backup device and phone number ready for contingencies. Professional technical setup demonstrates respect for interviewer’s time.
- Materials and Environment Ready
Have physical copies of resume, portfolio projects list, prepared questions for interviewers accessible. Keep glass of water nearby managing dry mouth from nervousness. Ensure quiet, well-lit environment free from interruptions for virtual interviews. Have notepad for taking notes during discussion. Preparation reduces stress and enables full focus on interview content.
- Last-Minute Review Strategy
Morning of interview, review: key Java concepts (multithreading, collections, streams), Spring Boot fundamentals, recent projects with technical details, company research notes. Avoid cramming new material causing confusion; focus on refreshing familiar topics. Review behavioral STAR stories practicing concise delivery. Light review builds confidence without overwhelming.
- Professional Presentation
Dress appropriately for company culture researched during preparation. For video interviews, professional attire creates right mindset even remotely. Arrive (virtually or physically) 10-15 minutes early demonstrating punctuality and managing unexpected delays. Professional presentation makes strong first impression influencing overall evaluation.
- Post-Interview Self-Care
After intense interviews, take time to decompress through: brief walk, healthy meal, relaxing activity. Avoid immediately analyzing every detail which increases anxiety. Celebrate effort invested regardless of outcome. Send thank-you email, then shift focus to other opportunities or skill development. Maintaining healthy perspective prevents burnout during job search process.
5. Comprehensive Java Full Stack Interview Preparation – Final Checklist
30 Days Before Interview
- ✅ Review all 220+ technical questions covering Java, Spring Boot, Hibernate, Microservices
- ✅ Complete 50+ LeetCode problems (Easy: 20, Medium: 25, Hard: 5) focusing on Java solutions
- ✅ Build/polish 2-3 portfolio projects showcasing full stack skills
- ✅ Study system design fundamentals and practice 5-10 design problems
- ✅ Prepare 8-10 STAR behavioral stories covering different competencies

1 Week Before Interview
✅ Conduct 2-3 mock interviews with peers or mentors.
✅ Review company technology stack, recent news, products
✅ Prepare 10-15 thoughtful questions for interviewers
✅ Test all technical equipment for virtual interviews
✅ Review key projects with technical details ready to discuss
Night Before Interview
✅ Light review of core concepts without cramming new material
✅ Prepare professional outfit and materials
✅ Get 7-8 hours quality sleep
✅ Visualization exercise of successful interview
✅ Avoid intensive studying; focus on rest and confidence building
Interview Day
✅ Healthy breakfast and light exercise
✅ Arrive/login 10-15 minutes early
✅ Breathing exercises before starting
✅ Have water, notepad, resume accessible
✅ Maintain positive mindset and confidence
Interview Day
✅ Send personalized thank-you email
✅ Follow up with any promised materials
✅ Document interview questions and reflection notes
✅ Practice self-care and manage stress
✅ Continue applying and preparing for other opportunities
🎯 Start Your Java Full Stack Journey Today
Master Skills → Practice Hands-On → Crack Interviews → Get Hired.